概述
课本的概述写得其实很不错,建议各位小伙伴的学习时一定要充分挖掘概要里面的信息。

整合出来的关键点有:
| 输入 | 特征向量 |
|---|---|
| 输出 | 类别标签(可以是多类) |
| 特点 | 不具有显示的学习过程 |
| 三要素 | 模型,距离度量,分类规则 |
因此本章节的重点内容为两部分:
- KNN算法流程:体会为什么KNN不具有显示的学习过程这个特点
- KNN算法的具体实现,kd树的具体实现。
1. KNN的算法流程
KNN是一种依靠数据固有分布来进行分类预测的算法。算法首先计算实例a与所有样本的距离,然后选择最近的K个点,再通过分析这个K个点的特性来预测a的分类。算法思想说白了很简单,意思就是“物以类聚”,我想知道你这个东西是哪一类的,那我可以从观察与你最相近的物体入手嘛。 算法的三个要素是:模型,距离度量与分类规则。只有确定了这三个要素,才能确定一个具体的KNN算法
- 模型:模型不像第二章中的感知机那样有一个显式的表达式,KNN也没有一个学习的过程,他是直接通过数据分布来对实例进行预测的。
- 距离度量:我该怎么衡量样本点之间的距离呢? 常见的方法有欧式距离,曼哈顿距离。余弦距离等,不同具有的适用场景不同,一般用的比较多的是欧式距离。下图是一张范数距离关系图:
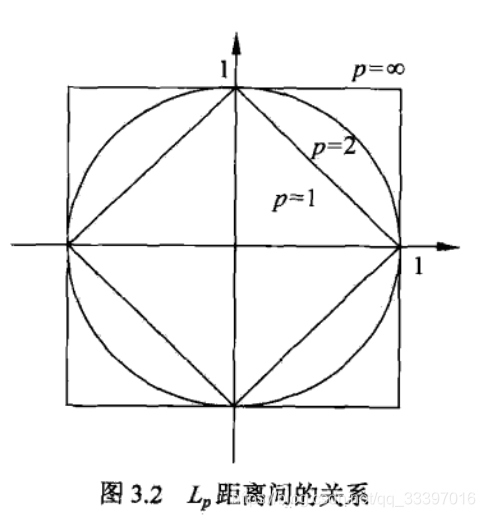
一范数(曼哈顿距离)在菱形上找最优点,二范数(欧式距离)在圆形上找最优点,无穷范数在正方形上找最优点。 - 分类规则: 当找个k个最近的样本点时,该用什么策略来决定实例的类别呢? 一般使用的是投票规则,这k个样本点大部分是什么类别,那这个实例也就是什么类别的了。这个投票别看着简单,是有理论支撑的:

2. KNN的实现
简单版本(自己实现)
实现思路:

代码:
class KNN:
def __init__(self,x_tranin,y_train,n_neighbours=3,p=2):
self.n = n_neighbours
self.p =p
self.x_train =x_tranin
self.y_train = y_train
def predict(self,x):
knn_list= []
# 保存距离数据
for i in range(len(self.x_train)):
dist = np.linalg.norm(x-self.x_train[i],ord = self.p)
knn_list.append((dist,self.y_train[i]))
#找出三个最近距离
nearest = []
for i in range(self.n):
max_index = knn_list.index(min(knn_list,key=lambda x:x[0]))
nearest.append(knn_list[max_index])
knn_list.remove(min(knn_list,key=lambda x:x[0]))
##统计票数
knn = [k[-1] for k in nearest]
count_pairs = Counter(knn)
max_count = sorted(count_pairs.items(), key=lambda x: x[1])[-1][0]
return max_count
def score(self, X_test, y_test):
right_count = 0
n = 10
for X, y in zip(X_test, y_test):
label = self.predict(X)
if label == y:
right_count += 1
return right_count / len(X_test)
clf = KNN(X_train, y_train)
print(clf.score(X_test, y_test))
Kd树版本(重点掌握)
kd树实际上就是一个二叉树,他以向量的某一维数据为参照量,不断把向量空间进行划分。如下图: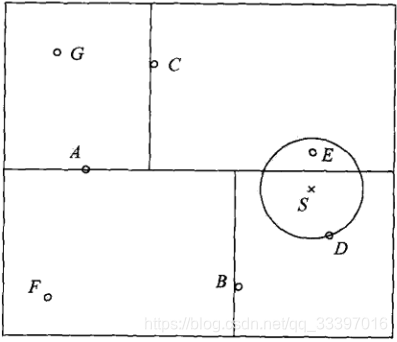
具体每一次分区该参考哪一维数据,这完全取决于个人选择。搜索kd树,只要找到该向量在哪一个区域,再然后再继续往下遍历,不断进入其子区域来寻找最近点即可。kd树的优点正是可以提高搜索效率,不需要盲目地暴力匹配。
每个树节点的结构
class Node(object):
def __init__(self,dom_elt,spilt,left,right):
self.dom_elt = dom_elt #这个就是划分点所表示的向量,如A点
self.spilt = spilt #表示按照第spilt维来对空间进行划分
self.left = left #左节点
self.right = right# 右节点
Kd树的构建
class KdTree(object):
def __init__(self,data):
k = len(data[0])
def CreatNode(spilt,data_set):
data_set.sort(data_set(spilt)) #首先按照某一维进行排序
spilt_pos = len(data_set)//2 #找出这一维度的中间值
median = data_set[spilt_pos] #提取样本点
spilt_next = spilt+1 %k #循环分组,防止越界,设置下一个被参考的维度
return Node(median,spilt,CreatNode(spilt_next,data[:spilt_next]),CreatNode(spilt_next,data[spilt_next+1:]))
self.root = CreatNode(0,data) #用递归的方法不断地构建叶节点
Kd树的前序遍历
def preorder(root):
print(root.dom_elt)
if root.left: # 节点不为空
preorder(root.left)
if root.right:
preorder(root.right)
搜索Kd树
kd的搜索过程比较复杂,我们认为,如果一个实例在一个分区中,那么这个实例的最近样本点必然在以该实例点为圆心,并通过当前最近点(表示该分区的叶节点)的圆内。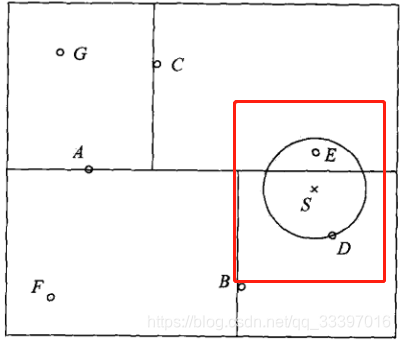
也就是说,S的最近样本点,一定在S与D所形成的圆内
def find_nearest(tree, point):
k = len(point)
def travel(Node, target, max_dist):
#递归结束的规则
if Node is None :
return result([0] * k, float("inf"), 0)
#设定遍历规则
nodes_visited = 1 #标记访问次数
s = Node.spilt
pivot = Node.dom_elt
if target[s]<=pivot[s]: #取某一维
nearer_node = Node.left
further_node = Node.right
else:
nearer_node = Node.right
further_node = Node.left
#递归遍历 ,找到覆盖目标点的叶节点
temp=travel(nearer_node,target,max_dist)
nearest= temp.nearest_point
dist = temp.nearest_dist
nodes_visited += temp.nodes_visited
if dist < max_dist:
max_dist= dist
temp_dist = abs(pivot[s]-target[s])# 第s维上目标点与分割超平面的距离,如果不相交
if temp_dist >max_dist:
return result(nearest,dist,nodes_visited)
#r如果与超球体相交
temp_dist = sqrt(sum((p1-p2)**2) for p1,p2 in zip(pivot,target))
if temp_dist <dist:
nearst = pivot
dist = temp_dist
max_dist = dist
#检查另一个子节点对应区域是否有更近的点
temp2 = travel(further_node, target, max_dist)
nodes_visited += temp2.nodes_visited
if temp2.nearest_dist < dist: # 如果另一个子结点内存在更近距离
nearest = temp2.nearest_point # 更新最近点
dist = temp2.nearest_dist # 更新最近距离
return result(nearest, dist, nodes_visited)
return travel(tree.root, point, float("inf")) # 从根节点开始递归
3 总结
- KNN算法的三要素是模型,距离度量,决策规则
- KNN算法没有显性的学习过程
- KNN算法的实现
- KDtree原理及实现
