sklearn.metrics.roc_curve使用简要说明
一、背景说明
小哥我是一名机器学习小白,刚开始学习sklearn。像部分刚入门的小白一样被混淆矩阵搞得头昏脑胀,最近碰到朋友咨询我roc_curve返回的结果是如何生成的时候,我一脸懵逼。shift+Tab查看系统说明没有看明白(本人英语水平很弱,亲一定要学好英语);然后,上网求助,也没有得到想要的答案。最后受这篇文章http://www.bubuko.com/infodetail-2718749.html的启发,自己重新摸索出规律,把自己一点小想法分享给大家,希望能帮助大家
二、TP、TN、FP、FN概念
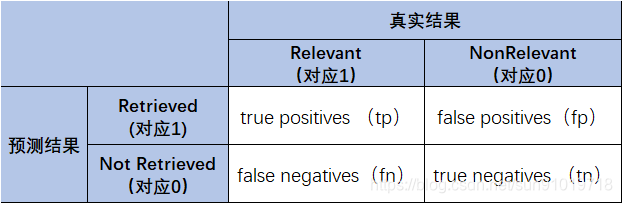 ## 三、TPR、TNR、FPR、FNR概念
## 三、TPR、TNR、FPR、FNR概念
1、TPR=tp/(tp+fn)
TPR:即真正率或灵敏度或召回率或查全率或真正率或功效,本来为正样本的样本被预测为正样本的总样本数量÷真实结果为正样本的总样本数
另:精确度或查准率公式等于tp/(tp+fp)
准确得分计算:(tp+tn)/(tp+fp+fn+tn)
2、FNR=fn/(tp+fn) =1-TPR
FNR:即假负率,本来为正样本的样本被预测为负样本的总样本数量÷真实结果为正样本的总样本数。
相当于假设检验中,犯第二类错误概率(β)
3、FPR=fp/(fp+tn)
FPR:即假正率,本来为负样本的样本被预测为正样本的总样本数量÷真实结果为负样本的总样本数。
相当于假设检验中,犯第一类错误概率(α)
4、TNR=tn/(fp+tn)=1-FPR
TNR:即真负率或特异度,本来为负样本的样本被预测为负样本的总样本数量÷真实结果为负样本的总样本数。
四、roc_curve运行机制简单剖析
4.1、roc_curve简单介绍
4.1.1 重要参数
y_true:真实结果数据,数据类型是数组
y_score:预测结果数据,可以是标签数据也可以是概率值,数据类型是形状 与y_true一致的数组
pos_label:默认为None,只有当标签数据如{0,1}、{-1,1}二分类数据才能默认;否则需要设置正样本值
4.1.2 返回的结果
返回三个数组结果分别是fpr(假正率),tpr(召回率),threshold(阈值)
4.2、第一种情形:y_score是标签数据
4.2.1、例子
代码.
//python 代码
y_true=np.array([0, 0, 0, 1, 1, 0, 0, 0, 1, 0])
y_score=np.array([0, 0, 0, 1, 1, 0, 0, 0, 0, 0])
fpr,tpr,threshold=roc_curve(y_true,y_score)
返回结果.
threshold:array([2, 1, 0])
tpr:array([0. , 0.66666667, 1. ])
fpr:array([0., 0., 1.])
4.2.2、解释:
1、threshold返回的结果是y_score内的元素去重后加入一个‘最大值+1’的值降序排序后组成的数据,每一个元素作为阈值,数据类型是一维数组。比如:y_score=np.array([0, 1, 2,0,3,1])对应的threshold=np.array([4, 3, 2,1,0])
2、当index=0,阈值等于threshold[0]=2。此时,假定y_score中所有大于等于2的元素对应index在y_true中的样本为正样本,其他为负样本,然后与y_true对应元素对比组成混淆矩阵,因没有大于等于2的值,所以TP和FP都为0,即tpr[0]=0/3=0.0,fpr[0]=0/7=0.0
3、当index=1,阈值等于threshold[1]=1。此时,假定y_score中所有大于等于1的元素对应index在y_true中的样本为正样本,其他为负样本,然后与y_true对应元素对比组成混淆矩阵,因大于等于1的数有2个,所以TP=2和FP=0,即tpr[1]=2/3=0.66666667,fpr[1]=0/7=0.0
4、当index=2,阈值等于threshold[2]=0。此时,假定y_score中所有大于等于0的元素对应index在y_true中的样本为正样本,其他为负样本,然后与y_true对应元素对比组成混淆矩阵,因大于等于0的数有10个,所以TP=3和FP=7,即tpr[2]=3/3=1.0,fpr[2]=7/7=1.0
所以,最终结果:tpr=array([0., 0.66666667, 1.]),fpr=array([0., 0., 1.])
4.3、第二种情形:y_score是概率值
4.3.1、例子
代码.
//python 代码
y_true=np.array([0,0,1,1])
y_score=np.array([0.1,0.4,0.35,0.8])
fpr,tpr,threshold=roc_curve(y_true,y_score)
返回结果.
threshold:array([1.8 , 0.8 , 0.4 , 0.35, 0.1])
tpr:array([0. , 0.5, 0.5, 1. , 1.])
fpr:array([0. , 0. , 0.5, 0.5, 1. ])
4.3.2、解释:
1、当index=0,阈值等于threshold[0]=1.8。此时,假定y_score中所有大于等于1.8的元素对应index在y_true中的样本为正样本,其他为负样本,然后与y_true对应元素对比组成混淆矩阵,因没有大于等于1.8的值,所以TP和FP都为0,即tpr[0]=0/2=0.0,fpr[0]=0/2=0.0
2、当index=1,阈值等于threshold[1]=0.8。此时,假定y_score中所有大于等于1的元素对应index在y_true中的样本为正样本,其他为负样本,然后与y_true对应元素对比组成混淆矩阵,因大于等于0.8的数有1个,刚好y_true中该位置元素值为1,所以TP=1和FP=0,即tpr[1]=1/2=0.5,fpr[1]=0/2=0.0
3、当index=2,阈值等于threshold[2]=0.4。此时,假定y_score中所有大于等于0.4的元素对应index在y_true中的样本为正样本,其他为负样本,然后与y_true对应元素对比组成混淆矩阵,因大于等于0.4的数有2个,所以TP=1和FP=1,即tpr[2]=1/2=0.5,fpr[2]=1/2=0.5
4、当index=3,阈值等于threshold[3]=0.35。此时,假定y_score中所有大于等于0.35的元素对应index在y_true中的样本为正样本,其他为负样本,然后与y_true对应元素对比组成混淆矩阵,因大于等于0.35的数有3个,所以TP=2和FP=1,即tpr[3]=2/2=1.0,fpr[3]=1/2=0.5
5、当index=4,阈值等于threshold[4]=0.1。此时,假定y_score中所有大于等于0.1的元素对应index在y_true中的样本为正样本,其他为负样本,然后与y_true对应元素对比组成混淆矩阵,因大于等于0.1的数有4个,所以TP=2和FP=2,即tpr[4]=2/2=1.0,fpr[4]=2/2=1.0
所以,最终结果:tpr=array([0. , 0.5, 0.5, 1. , 1.]),fpr=array([0. , 0. , 0.5, 0.5, 1. ])
小哥我的分享就到此结束,有不足之处,请及时指正!
另给大家推荐一个ROC曲线描述很好的博客: https://blog.csdn.net/yuxiaosmd/article/details/83046162.
