
随着数据行业的发展,数据量的不断增加,对数据分析挖掘的技术也在逐步更新。如今一提到大数据,业内人士首先就会想到Hadoop、Spark。那么怎么理解Hadoop和Spark让很多人产生迷茫。
CDA数据分析研究院认为,Spark是大数据行业的后起之秀,与Hadoop相比,Spark有很多优势。Hadoop能在业内得到充分认可的主要原因是:
1、 Hadoop解决了大数据的可靠存储和处理问题。
2、 Hadoop的开源性,能让大数据从业人士找到灵感,方便实用。
3、 Hadoop拥有完整的生态圈
4、 HDFS是一种分布式文件系统层,可对集群节点间的存储和复制进行协调。HDFS确保了无法避免的节点故障发生后数据依然可用,可将其用作数据来源,可用于存储中间态的处理结果,并可存储计算的最终结果。
5、 MapReduce通过简单的Mapper和Reducer的抽象提供一个变成模型,可以并发的,分布式的处理大量的数据集,将最终结果重新写入HDFS。

Hadoop及其Map reduce处理引擎提供了一套久经考验的批处理模型,最适合处理对时间要求不高的非常大规模的数据集,通过非常低成本的组建即可搭建完整功能的Hadoop集群,使得廉价且高效的处理技术可以灵活应用在很多哪里实例中。
但Hadoop也会有很多局限和不足,在数据量的不断扩大下,Hadoop的运算速度会比较吃力,现阶段来讲,Hadoop在大数据行业仍有很高频率的应用,但随着数据量的增大,Hadoop中的Map reduce将面临窘境。而Spark的运算速度是Hadoop中Map reduce的百倍甚至更快。
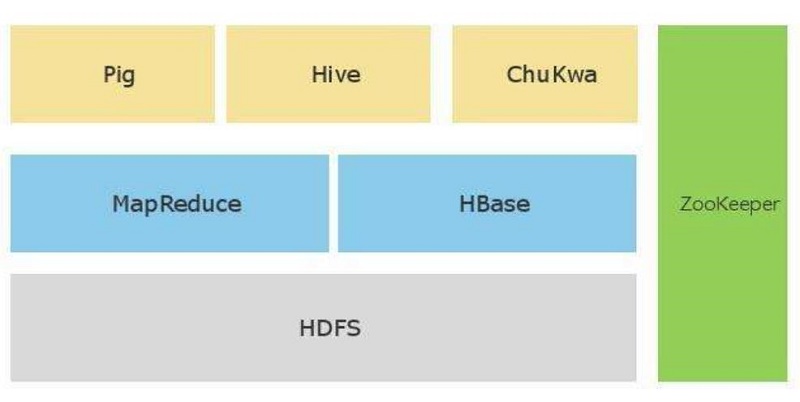
Hadoop体系架构
Spark是一种包含流处理能力的下一代批处理框架。与Hadoop的Map reduce引擎基于各种相同原则开发而来的,Spark主要侧重于通过完善的内存计算和处理优化机制加快批处理工作负载的运算速度。
CDA大数据分析师都具备了Hadoop与Spark的技能,在各行各业得到了实际的应用,如交通大数据、电力大数据、电商大数据等。
从对CDA大数据分析师的采访中得知,在电商行业,用户每天的浏览、点击、下单支付行为都会产生海量的日志信息,这些日志信息会被汇总、整理、挖掘、学习,用Hadoop中的Map reduce框架解决数据处理、机器学习等问题,从而对行业的推荐、搜索系统甚至公司的战略目标提供数据支持。但是随着数据量的不断增大,Map reduce框架明显有些吃力,企业也正在往Spark上转。Spark的三个优点使得它在行业里得到了的迅速发展:

1、 快速高效,,首先,Spark使用了线程池模式,任务调度效率很高,其次,Spark可以最大限度的利用内存,多轮迭代任务执行效率高。
2、 API友好易用。主要体现在两个方面:第一,Spark支持多门编程语言,可以满足不同语言背景的人使用需求,第二,Spark的表达能力非常丰富,并且封装了大量的常用操作
3、 组建丰富。Spark生态圈当下已经比较完整,在官方组件涵盖SQL、图计算、机器学习和实时计算的同时,还有很多第三方开发的优秀组件,足以应对日常的数据处理需求。
阿里是国内最早使用Spark的公司之一,同时也是最早在Spark中是用来YARN的公司之一。
淘宝网络数据挖掘和计算团队针对淘宝的大数据和应用场景,在MLlib、GraphX和Streaming三大块进行了广泛的应用,并取得了很好的效果。可以说阿里的技术团队在利用Spark来解决多次迭代的机器学习算法、高计算复杂度的算法方面,在国内居于领先的位置。同时阿里也在积极打造Spark周边的生产环境,使得Spark在阿里的应用更加广泛,可以满足大部分算法工程师和数据科学家的需求。