目录: 一、神经网络框架学习 二、项目实战:学生录取 1、数据读入 2、画图看数据分布 3、对rank进行one-hot编码 4、GPA/GRE归一化 5、切分训练集、测试集 6、生成特征、目标 7、定义模型 8、训练模型 9、评估模型
一、神经网络框架学习
神经网络包:keras, Tensorflow,caffe, theano, scikit-learn and so on....
keras参考文档:keras中文文档
keras与tensorflow,theano的关系如下图:
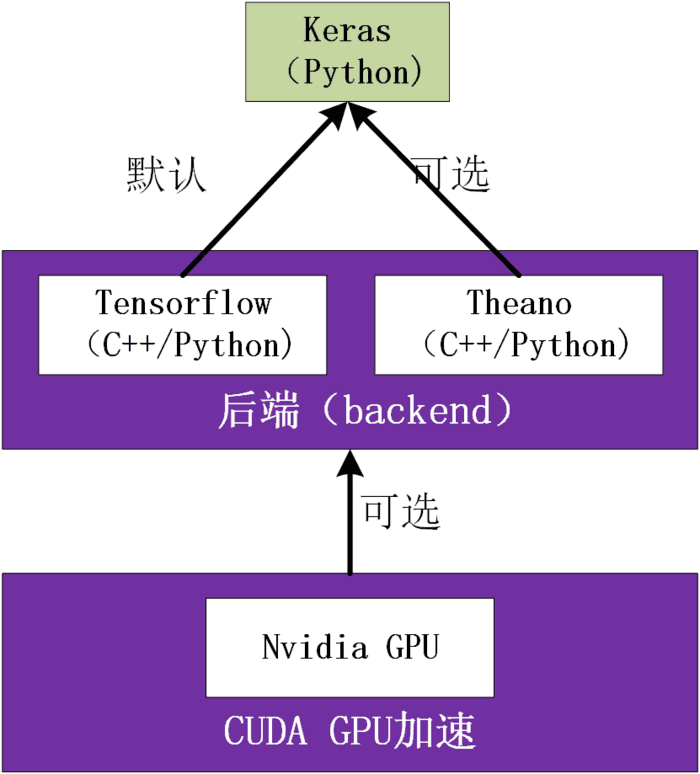
keras核心概念
(1)序列模型

keras.models.Sequential是神经网络的封装容器。提供常见的函数,比如:fit(),evaluate()和compile()。
(2)层
有全连接层、最大池化层和激活层。可以使用add()函数添加层。
二、项目实战:学生录取
输入:测试成绩GRE,平时成绩GPA,评级(1,2,3,4)
输出:是否录取(0,1)
1、数据读入
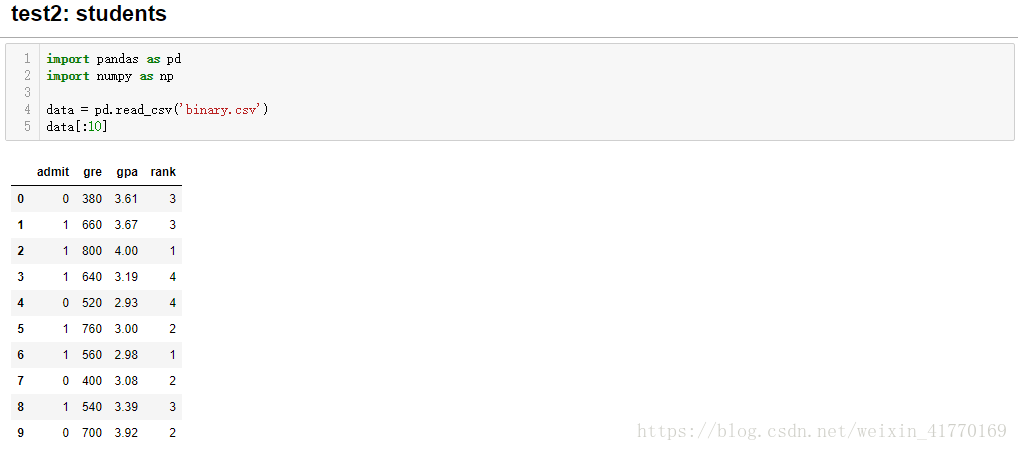
2、画图看下数据分布
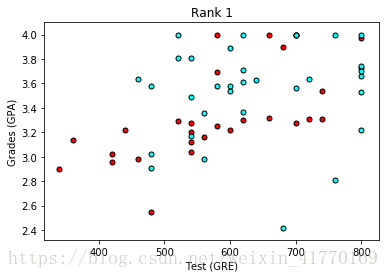
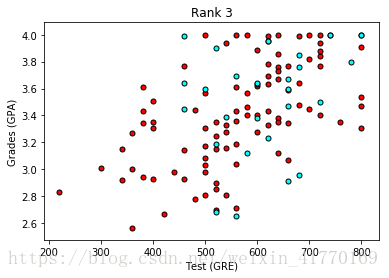
蓝色点:录取,红色点:拒绝
(1)先不带rank,只看GPA和Gre,发现基本是GPA和GRE都高的,就会被录取。但是分的不是很明显,所以下面加入Rank。
import matplotlib.pyplot as plt
def plot_points(data):
X = np.array(data[["gre","gpa"]])
y = np.array(data["admit"])
admitted = X[np.argwhere(y==1)]
rejected = X[np.argwhere(y==0)]
plt.scatter([s[0][0] for s in rejected], [s[0][1] for s in rejected], s = 25, color = 'red', edgecolor = 'k')
plt.scatter([s[0][0] for s in admitted], [s[0][1] for s in admitted], s = 25, color = 'cyan', edgecolor = 'k')
plt.xlabel('Test (GRE)')
plt.ylabel('Grades (GPA)')
# Plotting the points
plot_points(data)
plt.show()

(2)看看GPA,GRE,Rank和录取之间的关系。
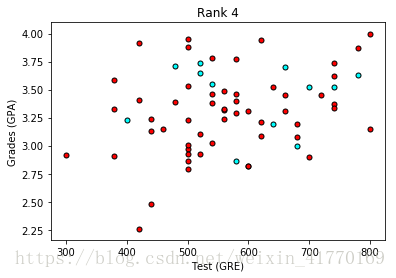
可以看出Rank等级越低,录取率越高。
# Separating the ranks
data_rank1 = data[data["rank"]==1]
data_rank2 = data[data["rank"]==2]
data_rank3 = data[data["rank"]==3]
data_rank4 = data[data["rank"]==4]
# Plotting the graphs
plot_points(data_rank1)
plt.title("Rank 1")
plt.show()
plot_points(data_rank2)
plt.title("Rank 2")
plt.show()
plot_points(data_rank3)
plt.title("Rank 3")
plt.show()
plot_points(data_rank4)
plt.title("Rank 4")
plt.show()

3、one-hot编码
Rank1-4要进行转化才能做为特征,因此使用one-hot编码。
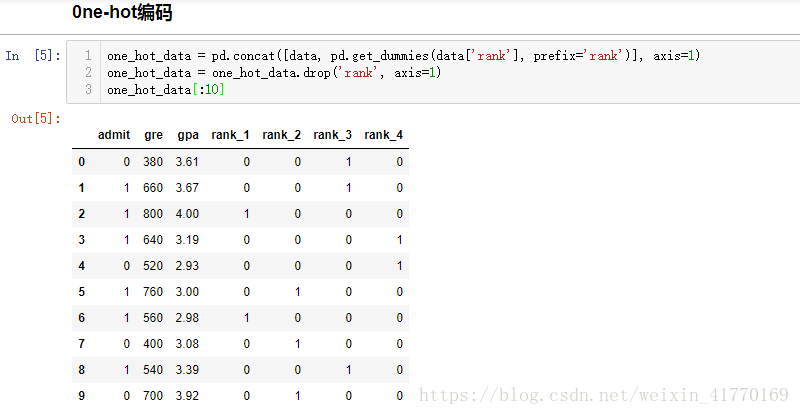
get_dummies(data['rank'], prefix='rank'),对data['rank']这一列进行one-hot编码,新的列名加上前缀'rank'
concat:当axis=1时,加到右边。当axis = 0时,加到后边。
drop(2, axis=0) axis=0时,去掉索引为2的行row;drop('B', axis=1) axis=1时,去掉索引为B的列column;
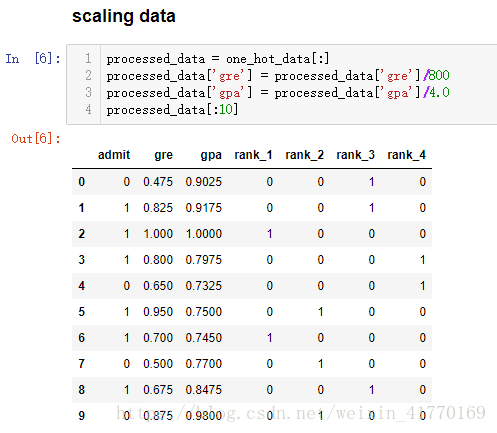
4、缩放数据:归一化
5、数据集划分:训练集和测试集
sample = np.random.choice(processed_data.index, size=int(len(processed_data)*0.9), replace=False)
train_data, test_data = processed_data.iloc[sample], processed_data.drop(sample)
print("Number of training samples is", len(train_data))
print("Number of testing samples is", len(test_data))
print(train_data[:10])
print(test_data[:10])

分析:
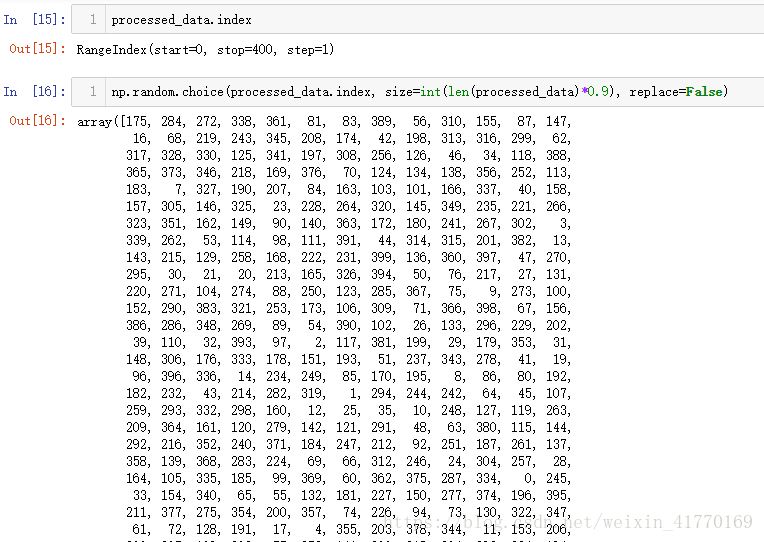
np.random.choice(processed_data.index, size=int(len(processed_data)*0.9), replace=False)
从一维数组中随机选取size个数,返回选择数的数组。
data.iloc 取行
data.drop 默认去掉行;axis=1,去掉列。
6、特征和目标生成
import keras
features = np.array(train_data.drop('admit', axis=1))
targets = np.array(keras.utils.to_categorical(train_data['admit'], 2))
features_test = np.array(test_data.drop('admit', axis=1))
targets_test = np.array(keras.utils.to_categorical(test_data['admit'], 2))
print(features[:10])
print(targets[:10])
分析:
去掉admit列:

去掉标题生成数组:
取admit这一列:

keras.utils.to_categorical其实就是用one-hot对类别标签进行编码,数字2表示类别总数:

与get_dummies的用法类似,如下:


7、定义模型结构:
import numpy as np from keras.models import Sequential from keras.layers.core import Dense, Dropout, Activation from keras.optimizers import SGD from keras.utils import np_utils model = Sequential() model.add(Dense(128, activation='relu', input_shape=(6,))) model.add(Dropout(.2)) model.add(Dense(64, activation='relu')) model.add(Dropout(.1)) model.add(Dense(2, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.summary()

分析:
sequential参考文章:https://keras-cn.readthedocs.io/en/latest/models/sequential/
(1)model.add 添加单元
第一个参数是输出单元个数
第一层必须指定输入单元个数,用input_dim或者input_shape来指定。
(2)model.compile 编译
在训练模型之前,我们需要通过compile来对学习过程进行配置。compile接收三个参数:
- 损失函数loss:该参数为模型试图最小化的目标函数,它可为预定义的损失函数名,如
categorical_crossentropy、mse,也可以为一个损失函数。详情见losses。categorical_crossentropy:对数损失,mse:均方误差。 - 优化器optimizer:该参数可指定为已预定义的优化器名,如
rmsprop、adagrad,或一个Optimizer类的对象,详情见optimizers。 - 指标列表metrics:对分类问题,我们一般将该列表设置为
metrics=['accuracy']。指标可以是一个预定义指标的名字,也可以是一个用户定制的函数.指标函数应该返回单个张量,或一个完成metric_name - > metric_value映射的字典.请参考性能评估。
(3)model.summary模型总结给出模型的形象化描述
模型除了输入层共3层,输入层是6个单元,第一层128个,第二层64个,输出层2个。
参数为:(6+1)*128+(128+1)*64+(64+1)*2=896+8256+130=9282
8、训练模型

fit(self, x, y, batch_size=32, epochs=10, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0)
x:输入数据。如果模型只有一个输入,那么x的类型是numpy array,如果模型有多个输入,那么x的类型应当为list,list的元素是对应于各个输入的numpy array
y:标签,numpy array
batch_size:整数,指定进行梯度下降时每个batch包含的样本数。训练时一个batch的样本会被计算一次梯度下降,使目标函数优化一步。
epochs:整数,训练终止时的epoch值,训练将在达到该epoch值时停止,当没有设置initial_epoch时,它就是训练的总轮数,否则训练的总轮数为epochs - inital_epoch
verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
callbacks:list,其中的元素是
keras.callbacks.Callback的对象。这个list中的回调函数将会在训练过程中的适当时机被调用,参考回调函数validation_split:0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集。验证集将不参与训练,并在每个epoch结束后测试的模型的指标,如损失函数、精确度等。注意,validation_split的划分在shuffle之前,因此如果你的数据本身是有序的,需要先手工打乱再指定validation_split,否则可能会出现验证集样本不均匀。
validation_data:形式为(X,y)的tuple,是指定的验证集。此参数将覆盖validation_spilt。
shuffle:布尔值或字符串,一般为布尔值,表示是否在训练过程中随机打乱输入样本的顺序。若为字符串“batch”,则是用来处理HDF5数据的特殊情况,它将在batch内部将数据打乱。
class_weight:字典,将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失函数(只能用于训练)
sample_weight:权值的numpy array,用于在训练时调整损失函数(仅用于训练)。可以传递一个1D的与样本等长的向量用于对样本进行1对1的加权,或者在面对时序数据时,传递一个的形式为(samples,sequence_length)的矩阵来为每个时间步上的样本赋不同的权。这种情况下请确定在编译模型时添加了
sample_weight_mode='temporal'。initial_epoch: 从该参数指定的epoch开始训练,在继续之前的训练时有用。
fit函数返回一个History的对象,其History.history属性记录了损失函数和其他指标的数值随epoch变化的情况,如果有验证集的话,也包含了验证集的这些指标变化情况
9、评估模型

分析:
evaluate(self, x, y, batch_size=32, verbose=1, sample_weight=None)
本函数按batch计算在某些输入数据上模型的误差,其参数有:
x:输入数据,与
fit一样,是numpy array或numpy array的listy:标签,numpy array
batch_size:整数,含义同
fit的同名参数verbose:含义同
fit的同名参数,但只能取0或1sample_weight:numpy array,含义同
fit的同名参数本函数返回一个测试误差的标量值(如果模型没有其他评价指标),或一个标量的list(如果模型还有其他的评价指标)。
model.metrics_names将给出list中各个值的含义。