单节点NameNode存在问题:
NameNode宕机,metadata数据消失;
单节点出现故障,如何进行故障转移?
如果增加一个NameNode节点,会出现脑裂问题(一个集群有多个管理者),如何解决?
ZK搭建高可用(HA High Aliavble)HDFS集群
原理
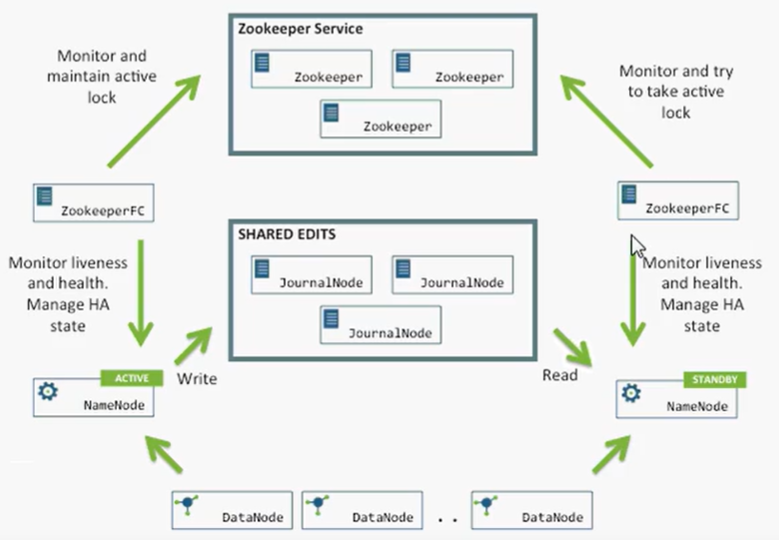
QJM(Quorum Jouranl Manager)是Hadoop转为为NameNode共享存储开发的组件。其集群运行一组Journal Node,每个Journal节点暴露一个简单的RPC接口,允许NameNode读取和写入数据,数据存放在Journal节点的本地磁盘。
故障转移问题上,引入了监控NameNode状态的ZookeeperFailController(ZKFC)。ZKFC一般运行在NameNode宿主机器上,与Zookkeeper集群写作完成故障的自动转移。
Journal Node两大作用:
- 同步NameNode们的editlog
- 当出现脑裂情况时,触发隔离机制,将其中一个NameNode节点kill掉(例如,NameNode1出现网络延迟,ZooKeeper认为它宕机了,ZKFC将NameNode2由standby转为active状态,此时,就有两个NameNode处于active状态,出现脑裂情况,Journal Node就会触发隔离机制,将剩余NameNode1的写入操作执行完毕之后,会通过SSH登录NameNode1节点将其进程关闭)
ZK集群
通常需要开辟三个独立端口
1:处理client请求
2:集群内部原子广播
3:集群内部选举投票

ZK集群创建
1.安装zookeeper
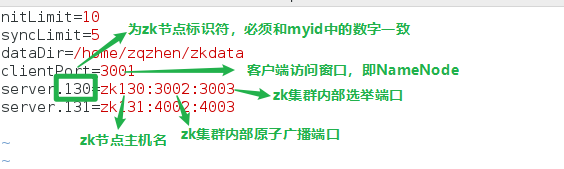
2.在每个zk节点创建数据目录,每个数据目录中必须有myid文件,用来唯一标识zk节点
3.数据目录中创建zoo.cfg的配置文件
启动zk集群
1 ./zkServer.sh start /root/zkdata/zoo.cfg
查看集群状态
1 ./zkServer.sh status /root/zkdata/zoo.cfg