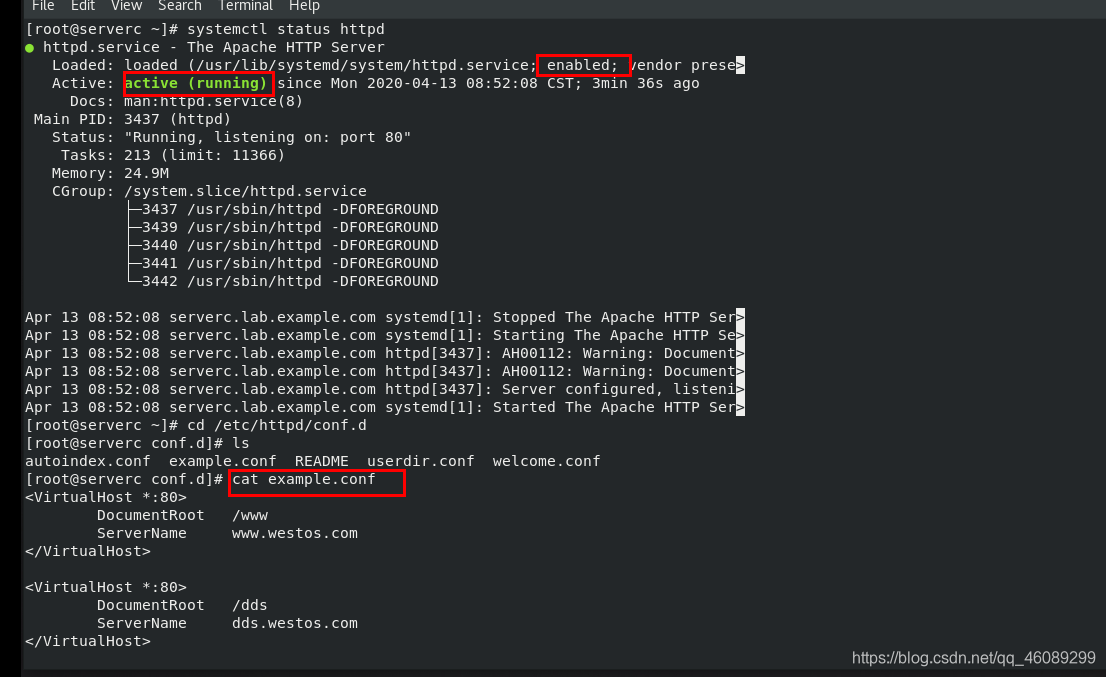
一、处理任务失败
通常playbook遇到错误会中止执行,但是有时我们想要失败时也能继续执行 后面的任务
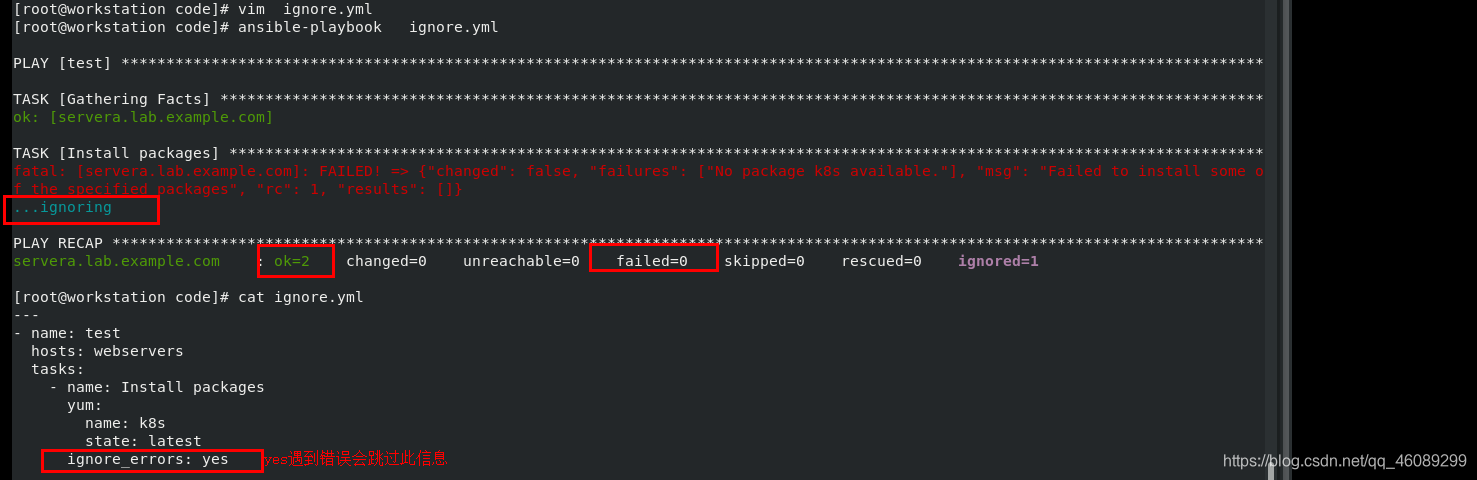
1.忽略任务失败
关键字:ignore_errors yes/no在任务执行错误时,忽略错误并继续执行任务

2.任务失败后强制执行处理程序
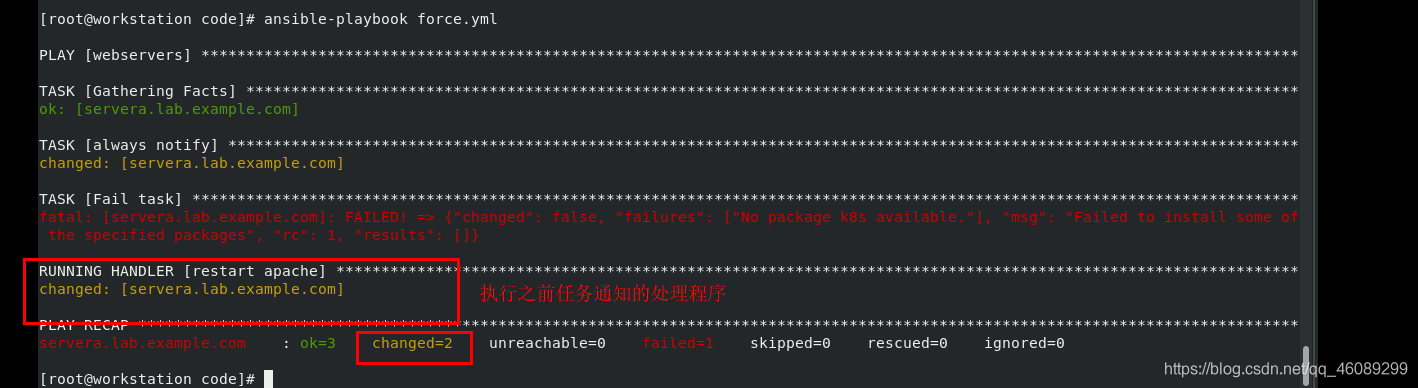
通常任务失败,play会中止当收到play中之前任务通知的处理程序将不会运行,如果要运行,需要使用关键字:force_handlers:yes
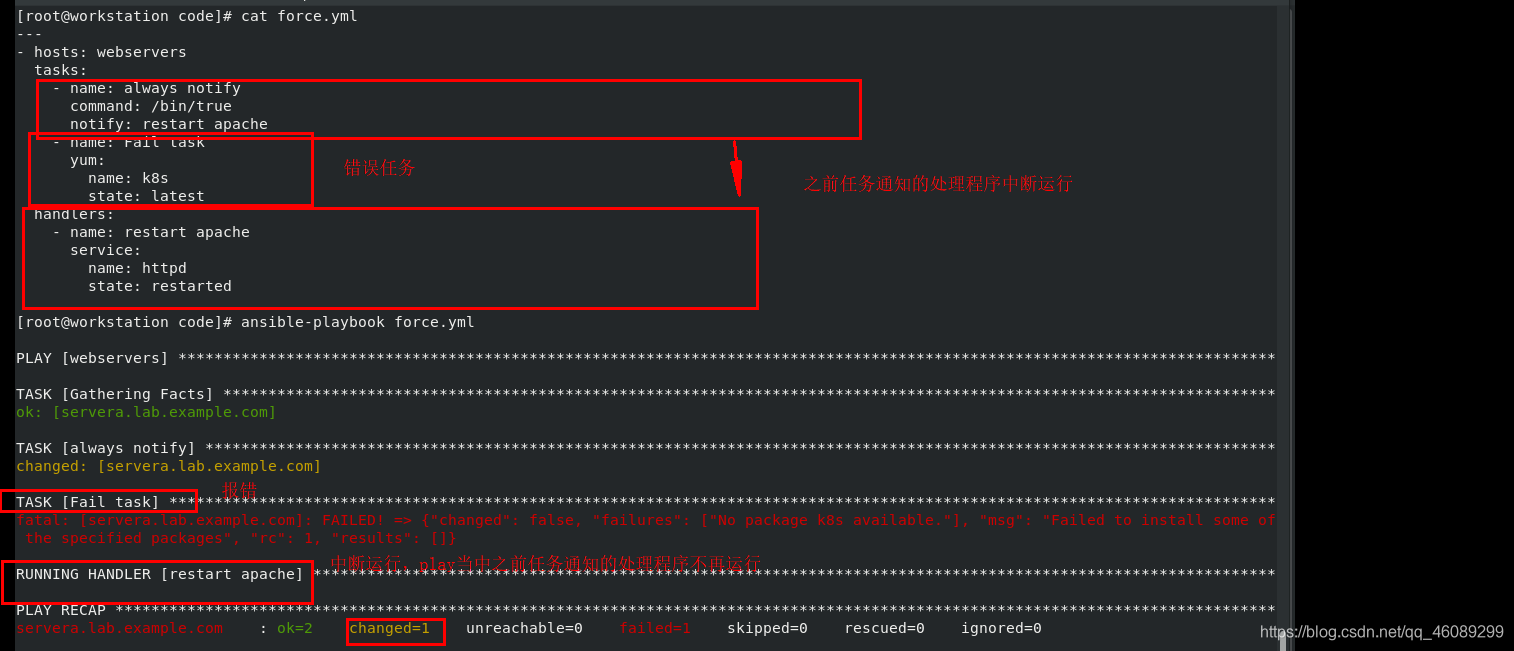
[root@workstation code]# cat force.yml
---
- hosts: webservers
force_handlers: yes 关键字 使用关键字才能继续执行之前任务通知的处理程序
tasks:
- name: always notify
command: /bin/true
notify: restart apache
- name: Fail task
yum:
name: k8s
state: latest
handlers: 通知的处理程序
- name: restart apache
service:
name: httpd
state: restarted
处理程序会在任务报告changed结果时获得通知,ok或者failed都不会’
3.指定任务失败条件
关键字:failed_when 其实是ansible的一种错误处理机制,是由fail模块使用了when条件语句的组合效果
---
- name: test
hosts: webservers
tasks:
- name: run script
shell: /usr/local/bin/user.sh
register: command_result
failed_when: "failure in command_result.stdout"
使用fail模块实现以上效果
---
- name: test
hosts: webservers
tasks:
- name: run script
shell: /usr/local/bin/user.stdout
register: command_resule
ignore_errors: yes
- name: report failure
fail:
msg: "Authentication failure" 提供明确信息
when: "failure in command_result.stdout"
4.指定任务何时报告"Changed"结果
在控制一些远程主机执行某些任务时,当任务在远程主机上成功执行,状态发生更改时,会返回changed状态响应,状态未发生更改时,会返回OK状态响应,当任务被跳过时,会返回skipped状态响应。我们可以通过changed_when来手动更改changed响应状态
关键字:changed_when
---
- name: test
hosts: webservers
tasks:
- name: get time
shell: date
changed_when: fales 当changed_when为false时,该tasks在执行以后,永远不会返回changed状态
5.ansible块和错误处理
三种关键字:
block:定义要运行的主要任务
rescue:定义要在block子句中定义的任务失败时运行的任务
always:定义始终独立运行的任务(其他任务成功或失败都将独立运行的任务)
5.1练习:
故意制造错误
[root@workstation code]# cat error.yml
---
- name: Test task failure
hosts: webservers
vars: 定义变量
web_pkg: http 此软件包不存在正确的是(httpd)
db_pkg: mariadb-server
db_service: mariadb
tasks:
- name: Install {{ web_pkg }} packages 安装失败
yum:
name: "{{ web_pkg }}"
state: present
- name: Install {{ db_pkg }} packages 前面失败后面无法继续执行
yum:
name: "{{ db_pkg }}"
state: present已安装

[root@workstation code]# cat error.yml
---
- name: Test task failure
hosts: webservers
vars: 定义变量
web_pkg: http 此软件包不存在正确的是(httpd)
db_pkg: mariadb-server
db_service: mariadb
tasks:
- name: Install {{ web_pkg }} packages 安装失败
yum:
name: "{{ web_pkg }}"
state: present
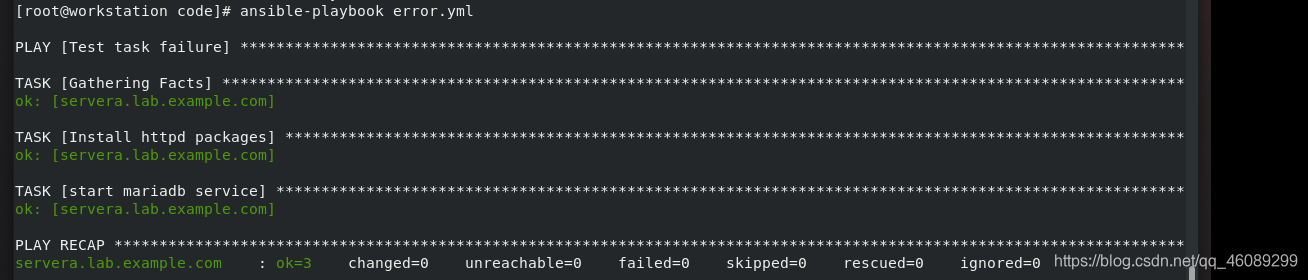
ignore_eroors: yes 添加忽略关键字忽略此次安装,进入下一个任务
- name: Install {{ db_pkg }} packages 前面失败后面无法继续执行
yum:
name: "{{ db_pkg }}"
state: present已安装
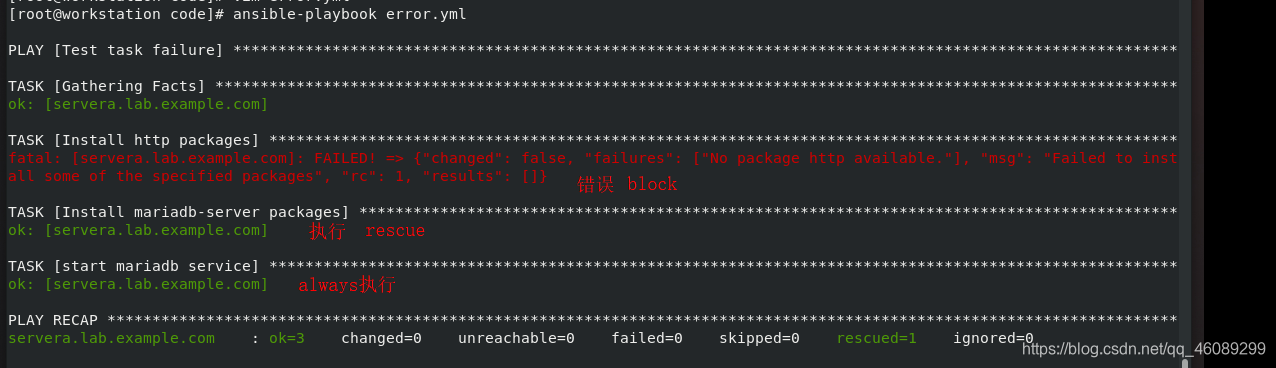
使用block、rescue、always将任务分开执行
---
- name: Test task failure
hosts: webservers
vars:
web_pkg: http 错误
db_pkg: mariadb-server
db_service: mariadb
tasks:
- name: set up web
block:
- name: Install {{ web_pkg }} packages 错误任务
yum:
name: "{{ web_pkg }}"
state: present
rescue:
- name: Install {{ db_pkg }} packages block错误rescue执行,block正确此任务不执行
yum:
name: "{{ db_pkg }}"
state: present
always: always单独每次都执行执行
- name: start {{ db_service }} service
service:
name: "{{ db_service }}"
state: started
使用changed_when 终止之前任务通知的处理程序
---
- name: Test task failure
hosts: webservers
vars:
web_pkg: httpd
db_pkg: mariadb-server
db_service: mariadb
tasks:
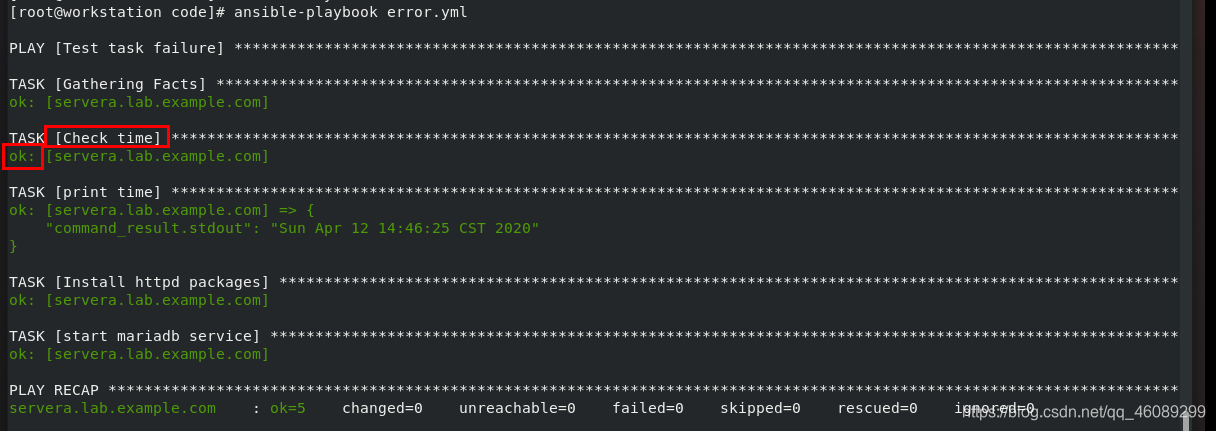
- name: Check time 终止时间
command: date 时间命令
register: command_result 注册变量
changed_when: false 去掉此参数每次运行都会触发时间程序,添加后再次运行为OK
- name: print time 打印时间
debug: 输出
var: command_result.stdout
- name: set up web
block:
- name: Install {{ web_pkg }} packages
yum:
name: "{{ web_pkg }}"
state: present
rescue:
- name: Install {{ db_pkg }} packages
yum:
name: "{{ db_pkg }}"
state: present
always:
- name: start {{ db_service }} service
service:
name: "{{ db_service }}"
state: started
使用failed_when关键字只是改变了任务的执行状态,不改变任务本身执行效果,但是失败的状态可以让rescue语句块执行
[root@workstation code]# vim error.yml
---
- name: Test task failure
hosts: webservers
vars:
web_pkg: httpd
db_pkg: mariadb-server
db_service: mariadb
tasks:
- name: Check time
command: date
register: command_result
changed_when: false
- name: print time
debug:
var: command_result.stdout
- name: set up web
block:
- name: Install {{ web_pkg }} packages
yum:
name: "{{ web_pkg }}"
state: present
failed_when: web_pkg = "httpd" 当安装的服务是httpd时候报错,因为只有block报错状态下rescue任务才会执行,但是http也是正常安装的
rescue: 执行
- name: Install {{ db_pkg }} packages
yum:
name: "{{ db_pkg }}"
state: present
always:
- name: start {{ db_service }} service
service:
name: "{{ db_service }}"
state: started
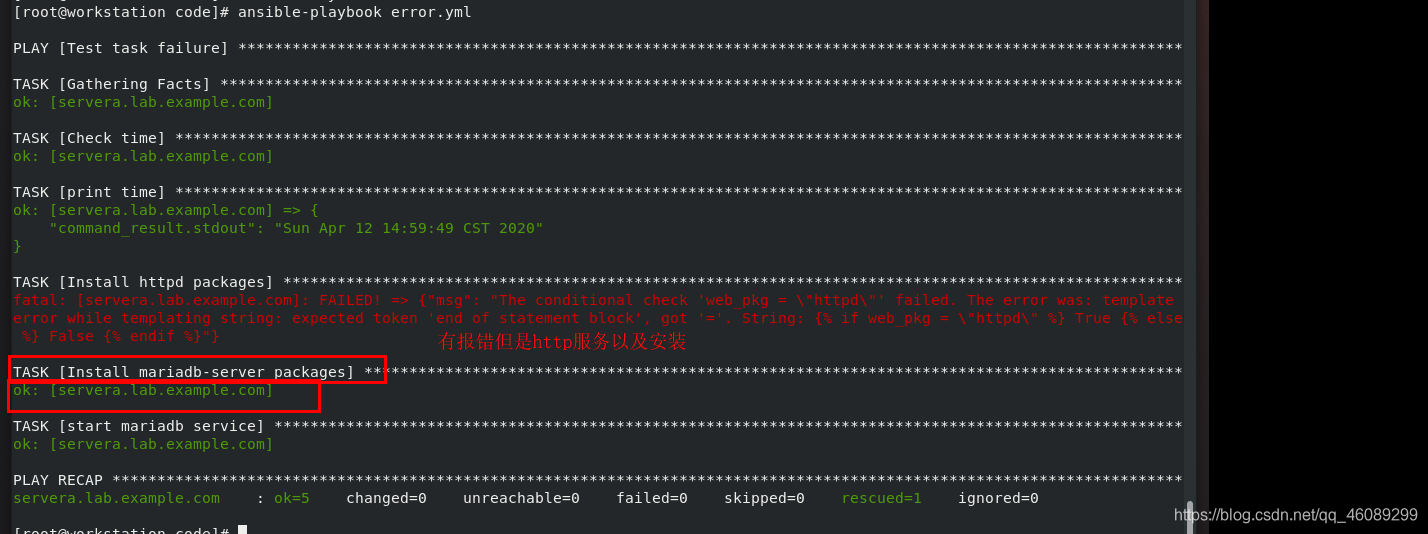
有报错,但是其实已经安装了httpd包
总结:
1.循环迭代的方法;
2.条件用于仅再次符合特定条件时执行任务或play
3.处理程序用法
4.只有任务报告受管主机做了更改,才会通知处理程序 {changed的结果才会触发}
5.处理任务失败,即使成功的任务也可以标记为失败 {failed_when};
6.块用于将任务分组为单元,通过任务是否成功来确定执行其他任务是否执行
二、在受管节点上创建文件或目录
1.修改文件并将其复制到主机
常用文件模块
blockinfile 将文本块添加到现有文件
copy 将文件复制到受管主机
fetch 从受管主机拷贝文件到控制节点
file 设置文件属性
lineinfile 确保特定行位于某个文件
stat 检索文件状态信息
synchronize rsync命令的一个打包程序
2.file模块处理文件,若文件不存在就新建 文件
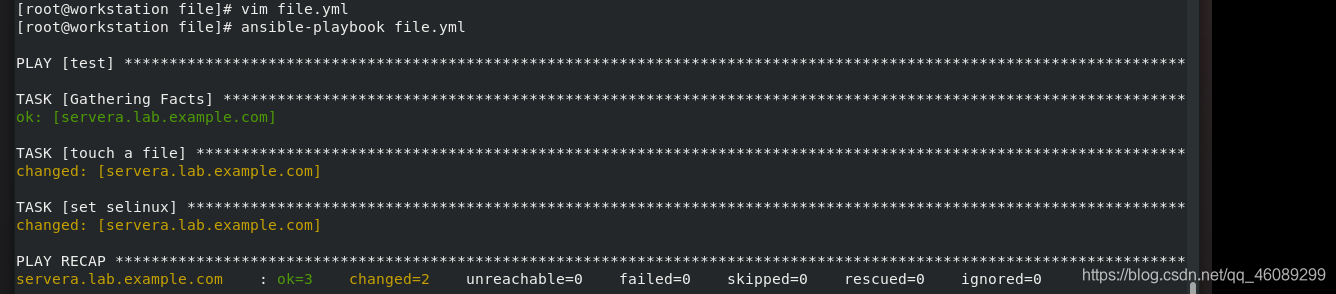
---
- name: test
hosts: webservers
tasks:
- name: touch a file 受管主机上创建文件
file: file模块
path: /root/file1 创建文件名称和路径
owner: student 所有人
group: student 所有组
mode: 0600 权限
state: touch 新建文件
- name: set selinux 更改文件安全上下文
file:
path: /root/file1
setype: samba_share_t 临时更改文件安全上下文

永久更改文件安全上下文(保持实验环境纯洁删除上面操作)
---
- name: test
hosts: webservers
tasks:
- name: touch a file
file:
path: /root/file1
owner: student
group: student
mode: 0600
state: touch
- name: set selinux
sefcontext: sefcontext模块
target: /root/file1 target指定目标
setype: samba_share_t setype指定更改的安全上下文类型
state: present 状态当前

3.在受管主机上复制和编辑文件
blockinfile:blockinfile 模块帮助我们在指定的文件中插入”一段文本”,这段文本是被标记过的,也就是我们在这段文本上做了记号,以便在以后的操作中可以通过”标记”找到这段文本,然后修改或者删除它
copy 复制
fetch
lineinfile
[root@workstation file]# cat shanchu.yml
---
- name: delete file
hosts: webservers
tasks:
- name: delete
file:
dest: /root/file1
state: absent
4.检测受管主机上的文件状态
MD5 全称是报文摘要算法,此算法对任意长度的信息逐位计算,产生一个二进制长度为 128 位(十六进制长度 32 位)的报文摘要,
---
- name: test
hosts: webservers
tasks:
- name: touch a file
file:
path: /root/file1
owner: student
group: student
mode: 0600
state: touch
- name: set selinux
sefcontext:
target: /root/file1
setype: samba_share_t
state: present
- name: Verify the status
stat:
path: /root/file1
checksum_algorithm: md5 校验算法
register: result
- debug:
msg: "The checksum is {{ result.stat.checksum }}"
5.同步控制节点和受管主机之间的文件
synchronize模块主要用于目录、文件的同步,主要基于rsync命令工具同步目录和文件
常用的src为源目录,dest为目标目录
三、使用jinjia2模板部署自定义文件
1.jinjia2介绍
jinja2之所以被广泛使用是因为它具有以下优点:
1.相对于Template,jinja2更加灵活,它提供了控制结构,表达式和继承等。
2.相对于Mako,jinja2仅有控制结构,不允许在模板中编写太多的业务逻辑。
3.相对于Django模板,jinja2性能更好。
4.Jinja2模板的可读性很棒。
5.格式:
{%EXPR %} 表达式或者逻辑
{{ EXPR }} 最终向用户输出表达式或结果
{# COMMENT #} 注释
2.构建jinja2模板
jinja2模板由多个元素组成:数据、变量、表达式
模板中使用的变量可以在playbook的vars中指定 ,模板中所有的值都使用变量方式,将来会被受管主机对应的值替代
如:更改http服务中的配置文件/etc/httpd/conf/httpd.conf
Port22==>Port{{ssh_port}} 端口变量
PermitRootLoginyes==>{{root_allowed}} 允许超级用户登录变量
3.部署jinja2模板
tasks:
-name:template
template: src:/root/j2-template.j2
dest: /root/dest-config-file.txt
4.控制结构 和使用循环
jinja2中的if语句类似与Python的if语句,它也具有单分支,多分支等多种结构,不同的是,条件语句不需要使用冒号结尾,而结束控制语句,需要使用endif关键字。
4.1.
{% for user in users %}
{{ user }} user变量将遍历users
{% endfor %}
4.2
{% for myhost in groups['myhosts'] %} 列出myhosts组中所有主机
{{ myhosts }}
{% endfor %}
使用条件句
{% if finished %} 只有此条件为真,才会将result变量的值放入文
{{ result }}
{% endif %}
jinja2的循环和条件只能在模板中使用,不能在playbook中使用
5.变量过滤器
{{ output | to_json }} 以json格式输出
{{ output | to_yaml }} 以yml格式输出
{{ output | from_json }} 对json格式字符串进行解析
{{ output | from_yaml }}
变量可以通过“过滤器”进行修改,过滤器可以理解为是jinja2里面的内置函数和字符串处理函数。
常用的过滤器有:
过滤器名称 说明
safe 渲染时值不转义
capitialize 把值的首字母转换成大写,其他子母转换为小写
lower 把值转换成小写形式
upper 把值转换成大写形式
title 把值中每个单词的首字母都转换成大写
trim 把值的首尾空格去掉
striptags 渲染之前把值中所有的HTML标签都删掉
join 拼接多个值为字符串
replace 替换字符串的值
round 默认对数字进行四舍五入,也可以用参数进行控制
int 把值转换成整型
那么如何使用这些过滤器呢? 只需要在变量后面使用管道(|)分割,多个过滤器可以链式调用,前一个过滤器的输出会作为后一个过滤器的输入。
练习:
[root@workstation jinjia2]# cat ansible.cfg
[defaults]
inventory = ./inventory
[root@workstation jinjia2]# vim inventory
[root@workstation jinjia2]# cat inventory
[webservers]
servera.lab.example.com
serverb.lab.example.com
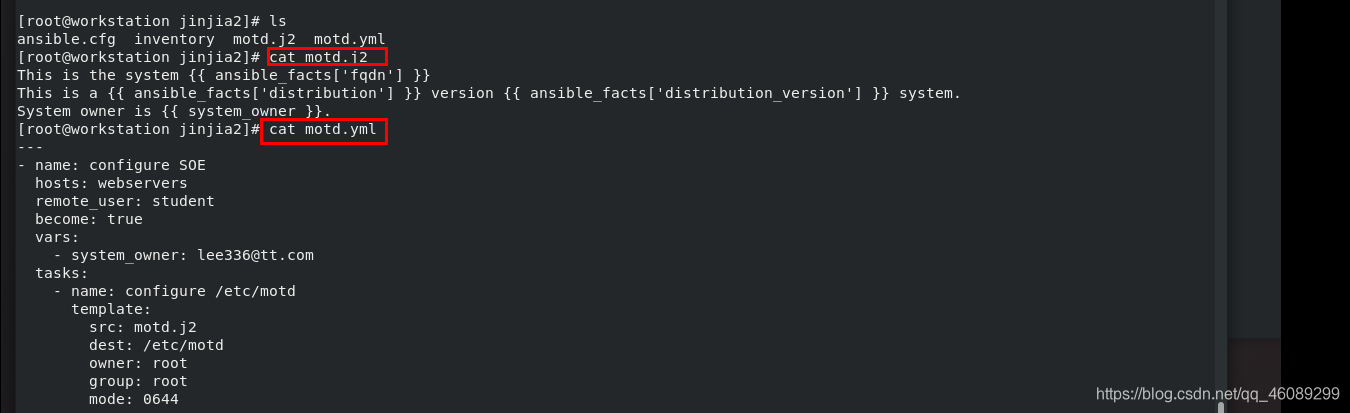
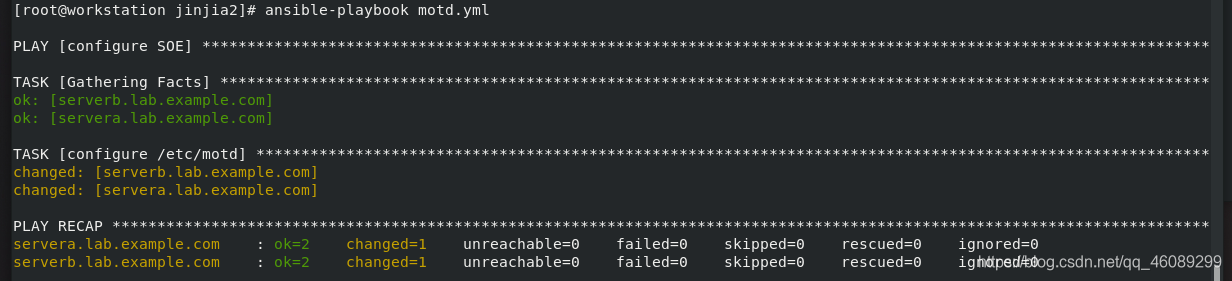
测试:
[root@servera ~]# cat /etc/motd
This is the system servera.lab.example.com 主机名称
This is a RedHat version 8.0 system. 操作系统
System owner is lee336@tt.com. 管理用户所有人
[root@serverb ~]# cat /etc/motd
This is the system serverb.lab.example.com
This is a RedHat version 8.0 system.
System owner is lee336@tt.com.
总结:
1.file模块库包含创建、复制、编辑、修改等权限和其他属性
2.使用jinja2模板动态构建文件来部署
3.jinja2模板由两个元素构成:变量和表达式,在使用jinja2模板时,他们被替换为值
4.通过jinja2过滤器,模板表达式可以从一种数据格式转换为另一种
四、管理大项目
利用主机模式选择主机
1.使用通配符匹配多个主机
-hosts:'*' 匹配所有
-hosts:'*.example.com' 匹配所有已example.com结尾的主机
-hosts:'172.25.254.*' 匹配所有此网段的主机
2.通过列表匹配主机或主机组
-hosts:www1.example.com,www2.example.com,172.25.254.250 匹配此三台主机
-hosts:webservers,westos 匹配此两个主机组
3.将通配符和列表等一起使用
-hosts:webservers,&westos 即属于webserver组也属于westos组
4.匹配westos组中所有主机,但是 servera.lab.example.com除外
-hosts:westos,!servera.lab.example.com
5.匹配所有主机除了servera.lab.example.com
-hosts all,!servera.lab.example.com
五、管理动态清单
github有很多动态清单脚本
1.编写动态清单程序
将INI格式的清单转换为JSON格式
[root@workstation hosts]# cat inventory
workstation.lab.example.com
[webservers]
web1.lab.example.com
web2.lab.example.com
[dbservers]
db1.example.com
db2.example.com
[root@workstation hosts]# ansible-inventory -i inventory --list
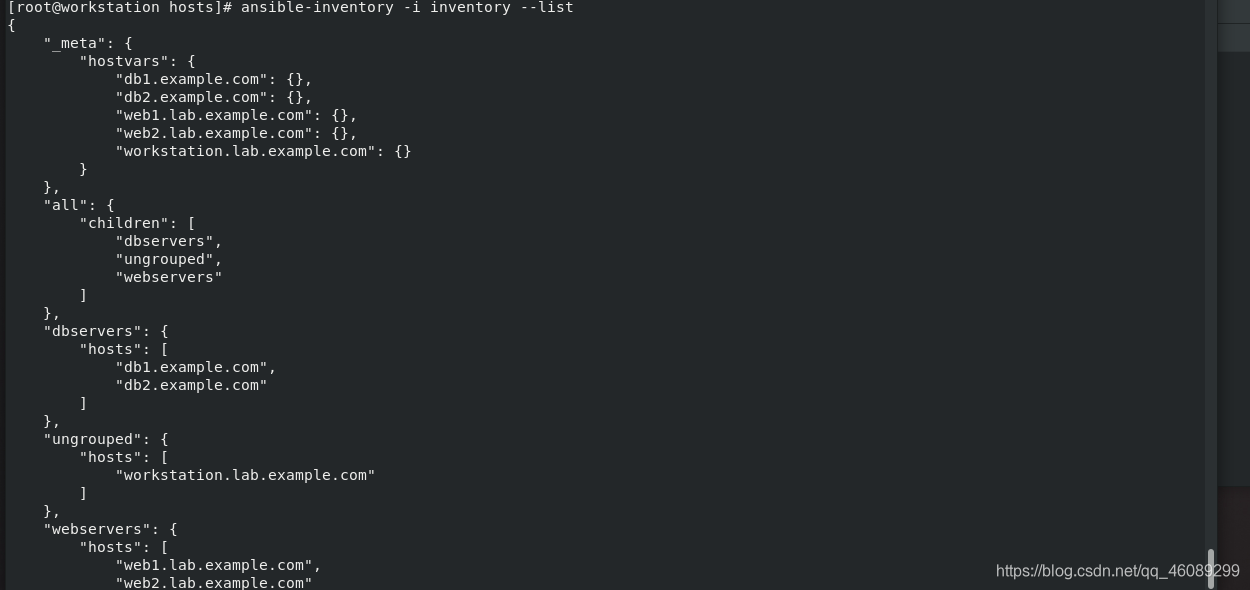
5.1配置并行
ansible最大的同时连接数是由ansible配置文件中forks参数控制
使用forks在ansible中配置并行
查看默认的最大连接数量
[root@workstation hosts]# grep forks /etc/ansible/ansible.cfg
#forks = 5
[root@workstation hosts]# ansible-config dump | grep -i forks
DEFAULT_FORKS(default) = 5
最大连接数为5,假设有十台主机,那么每次执行playbook,任务一运行前五台再运行后五台,任务二先前五台在后五台,以此类推
ansible默认并发数是5,可以用下面两种方法修改并发数:
1.环境变量方式
export ANSIBLE_FORKS=20
2.设置ansible.cfg
[defaults]
forks = 20
列如
[root@workstation hosts]# export ANSIBLE_FORKS=20
[root@workstation hosts]# ansible-config dump | grep -i forks
DEFAULT_FORKS(env: ANSIBLE_FORKS) = 20
5.2管理滚动更新
默认情况下,Ansible将尝试并行管理playbook中所有的机器。对于滚动更新用例,可以使用serial关键字定义Ansible一次应管理多少主机
如果更新发生在负载均衡服务器,更新完成会重启,可能导致后端所有web服务器停止服务, 因此可以使用 serial 关键字来分批运行 ,保证后端服务正常运行
还可以将serial关键字指定为百分比,表示每次并行执行的主机数占总数的比例:
- name: test play
hosts: webservers
serial: "30%"
[root@workstation hosts]# cat inventory
[webservers]
servera.lab.example.com
serverb.lab.example.com
serverc.lab.example.com
serverd.lab.example.com
编写脚本
---
- name: rolling update
hosts: webservers
serial: 2 此参数表示任务一次只能执行两台主机
tasks:
- name: install packages
yum:
name: httpd
state: latest
notify: restart apache
handlers:
- name: restart apache
service:
name: httpd
state: restart
serial参数优点:在更新时如果出现问题,那么在前2台发生问题是playbook就会 停止运行,后面的服务器不会执行,那么也就保证了服务的高可用’。
5.3包含和导入文件
大型playbook管理起来比较复杂,可以用模块化的方式管理
两种方法:包含、导入
5.3.1 导入playbook
导入playbook
1: 示列
- name: configure webserver
import_playbook: web.yml 假设web.yml已存在可以直接导入新的playbook使用
2.示列
- name:Play1
hosts: localhost
tasks:
- debug:
msg:Play1
- name: Import Playbook
import_playbook: play2.yml
5.3.2导入和包含任务的playbook
[root@workstation hosts]# cat test.yml
---
- name: Install packages
hosts: webservers
tasks:
- name: install apache
yum:
name: httpd
state: latest
- name: Start apache
service:
name: httpd
state: started
把上面写好的play导入到下面的play中
---
- name: install web
hosts: webservers
tasks:
- import_tasks: test.yml
使用导入时,when等条件语句应用于导入的每个任务;循环不能作用于导入的任务
5.3.3包含任务
包含任务
---
- name: Install web
hosts:webservers
tasks:
- include_tasks: tasks.yml
5.4为外部play和任务定义变量
提高play脚本的复用性
一个安装软件包和配置开机启动的任务
[root@workstation tasks]# cat task.yml
---
- name: Install {{ packages }}
yum:
name: "{{ packages }}"
state: latest
- name: Enable and start {{ service }}
service:
name: "{{ service }}"
enabled: true
state: started
以上play可以导入
---
- name: Test Install web
hosts: webservers
tasks:
- name: Import task
import_tasks: task.yml
vars:
packages: httpd
service: httpd
六、管理大项目综合实验

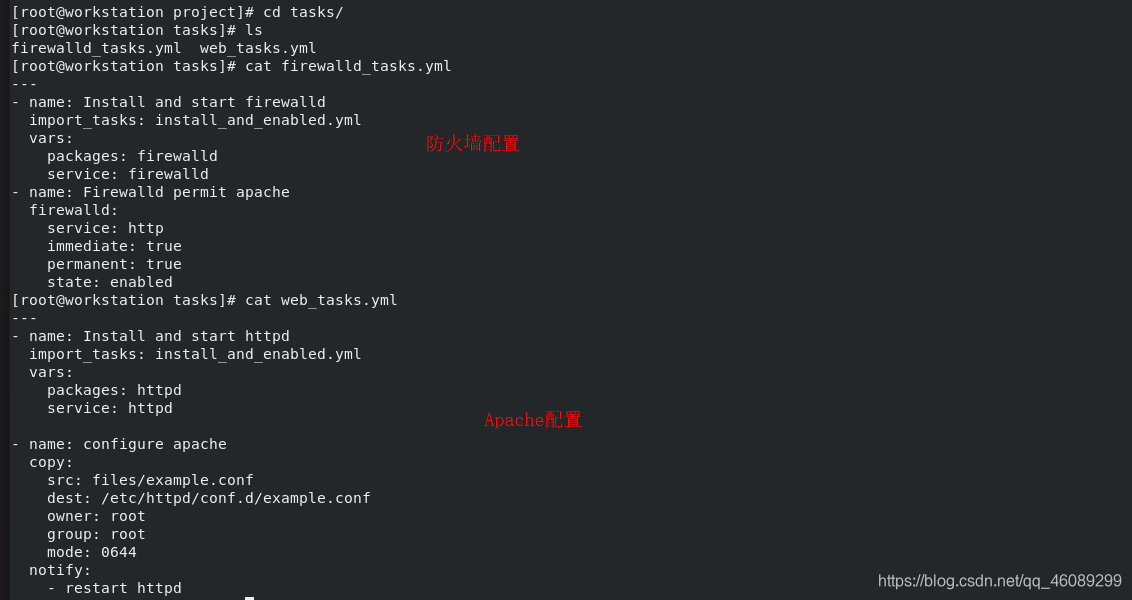
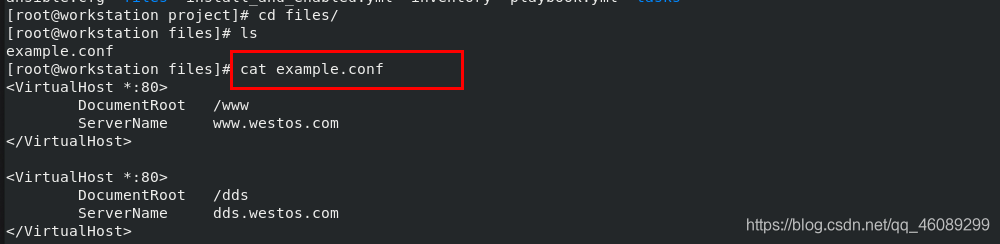

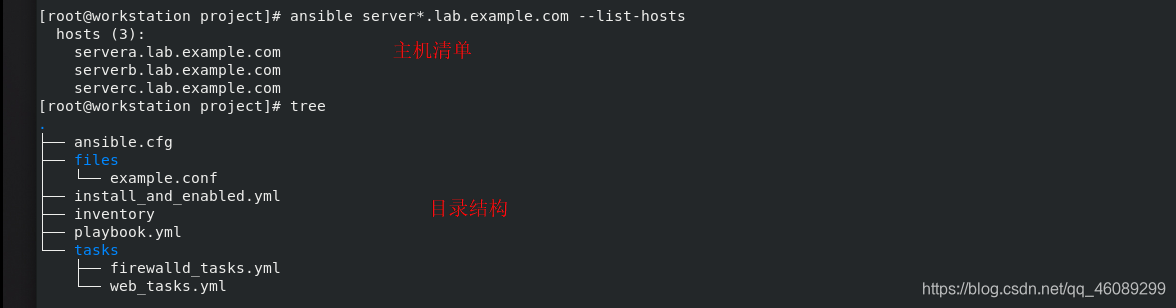
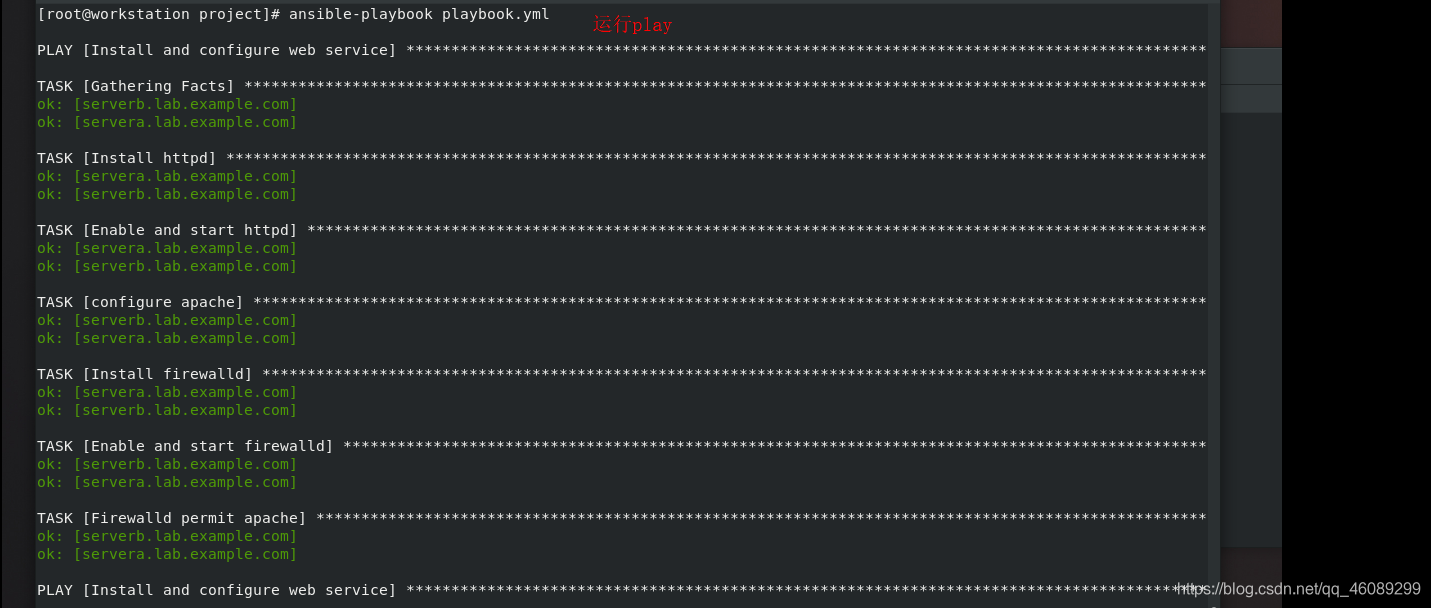
运行play
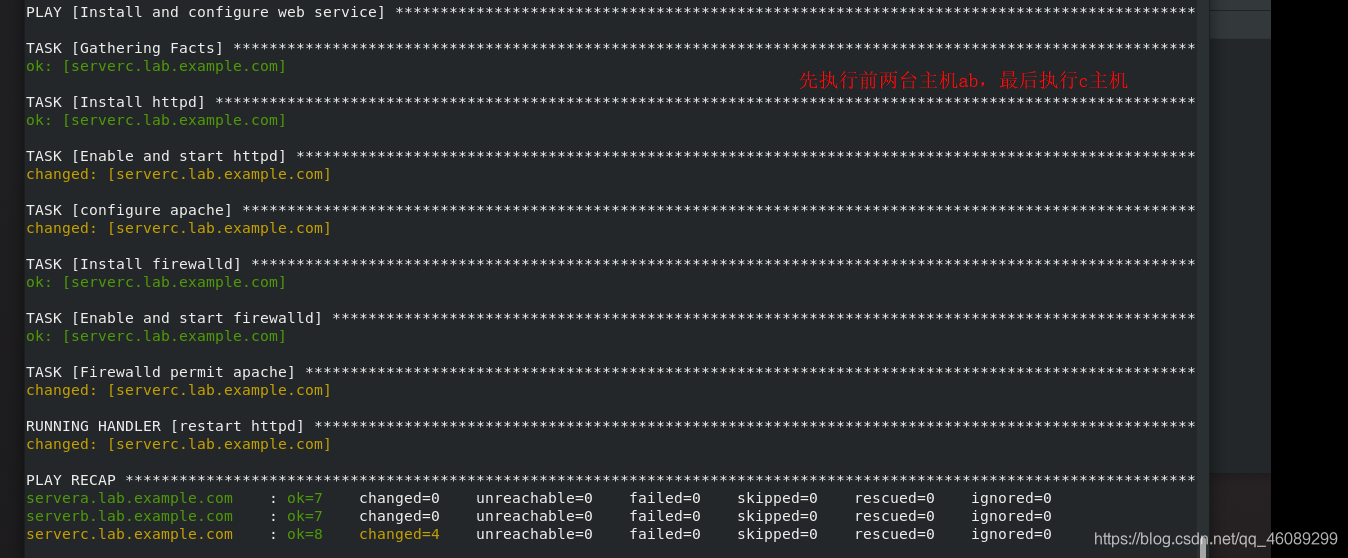
受管主机c测试