1.Mapper任务
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import sys
# 从标准输入中读取一行
for line in sys.stdin:
# 拆分每一行中的单词
words = line.split()
# 生成单词计数
for word in words:
# 将键 / 值对写入STDOUT中,以供减速器处理。
# 键是第一个制表符之前的任何字符,值是
# 第一个制表符之后的任何内容
print('{0}\t{1}'.format(word, 1))
# 调用
# echo 'hello world hello zhengzhou' | python mapper.py
# hello 1
# world 1
# hello 1
# zhengzhou 1
2.Reduce任务
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import sys
word = None
curr_word = None
curr_count = 0
# 处理mapper.py输出的键值对
for line in sys.stdin:
# 拆分line中键值对
word, count = line.split('\t')
# 转换计数类型int
count = int(count)
# 如果当前单词与前一个单词相同,则增加其单词
# count,否则将单词count打印到STDOUT
if word == curr_word:
curr_count += count
else:
if curr_word:
print('{0}\t{1}'.format(curr_word, curr_count))
curr_word = word
curr_count = count
# 输出最后一个单词的计数
if curr_word == word:
print('{0}\t{1}'.format(curr_word, curr_count))
# 调用
# echo 'hello world hello zhengzhou' | python mapper.py | sort -t 1 | python reducer.py
# hello 2
# world 1
# zhengzhou 1
3.wordcount
3.1 本地运行任务
- 创建文件test.txt
hello
ni hao ni haoni hao ni hao ni hao ni hao ni hao ni hao ni hao ni hao ni hao ni hao ni hao ao ni haoni hao ni hao ni hao ni hao ni hao ni hao ni hao ni hao ni hao ni hao ni haoao ni haoni hao ni hao ni hao ni hao ni hao ni hao ni hao ni hao ni hao ni hao ni hao
Dad would get out his mandolin and play for the family
Dad loved to play the mandolin for his family he knew we enjoyed singing
I had to mature into a man and have children of my own before I realized how much he had sacrificed
I had to,mature into a man and,have children of my own before.I realized how much he had sacrificed

2. 本地执行程序
cat test.txt | python mapper.py | sort -t 1 | python reducer.py
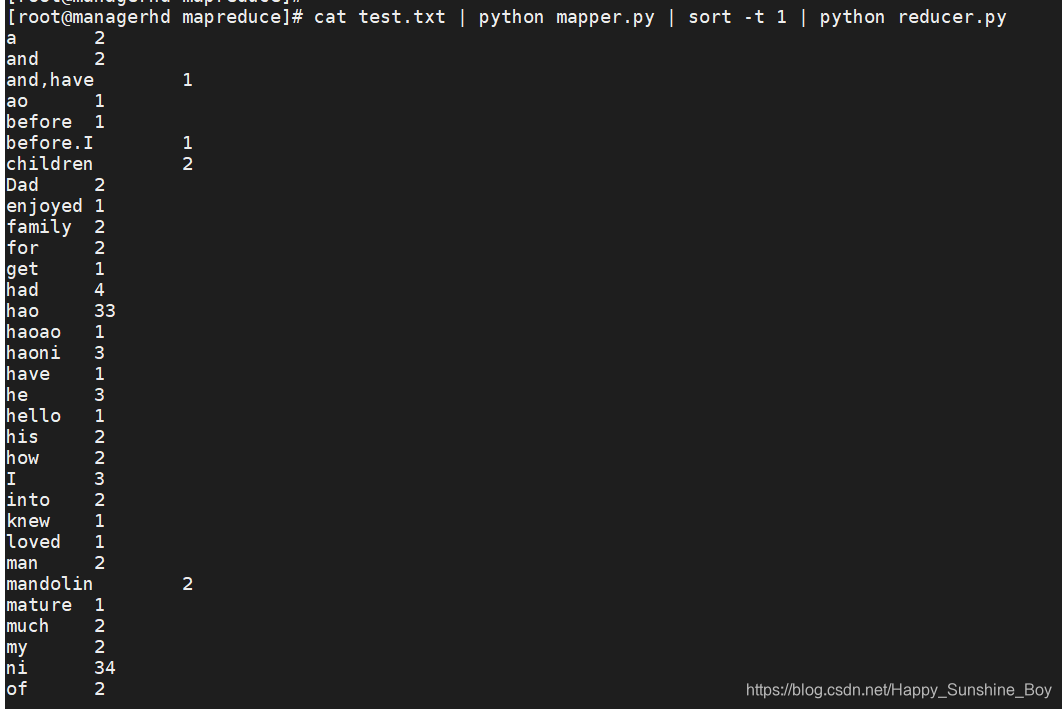
3.本地执行wordcount,统计出单词量
cat test.txt | python mapper.py | sort -t 1 | python reducer.py | wc -l

3.2 集群运行任务
1.上传文件
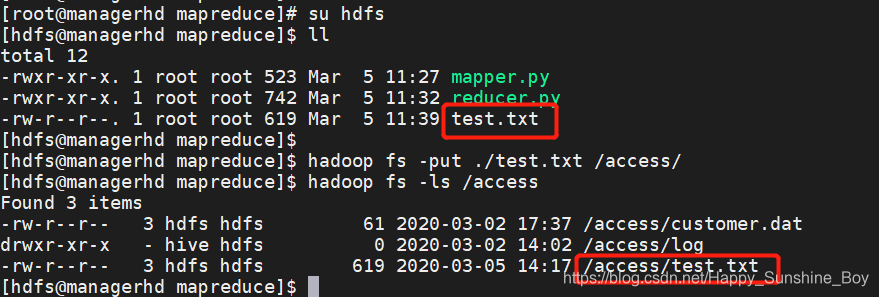
2.提交任务
切换用户:
su hdfs
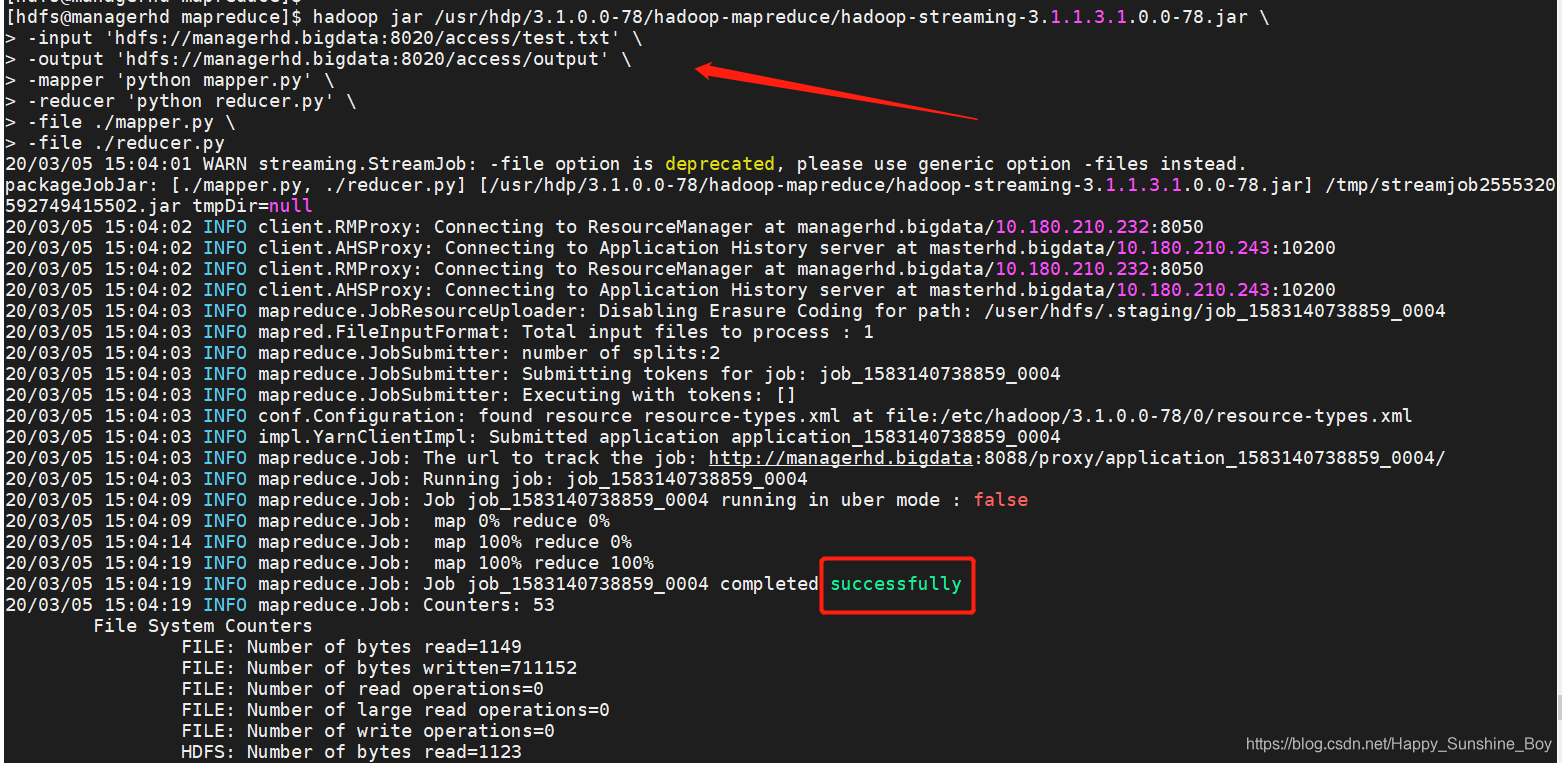
执行:
hadoop jar /usr/hdp/3.1.0.0-78/hadoop-mapreduce/hadoop-streaming-3.1.1.3.1.0.0-78.jar \
-input 'hdfs://managerhd.bigdata:8020/access/test.txt' \
-output 'hdfs://managerhd.bigdata:8020/access/output' \
-mapper 'python mapper.py' \
-reducer 'python reducer.py' \
-file ./mapper.py \
-file ./reducer.py
3.查看结果
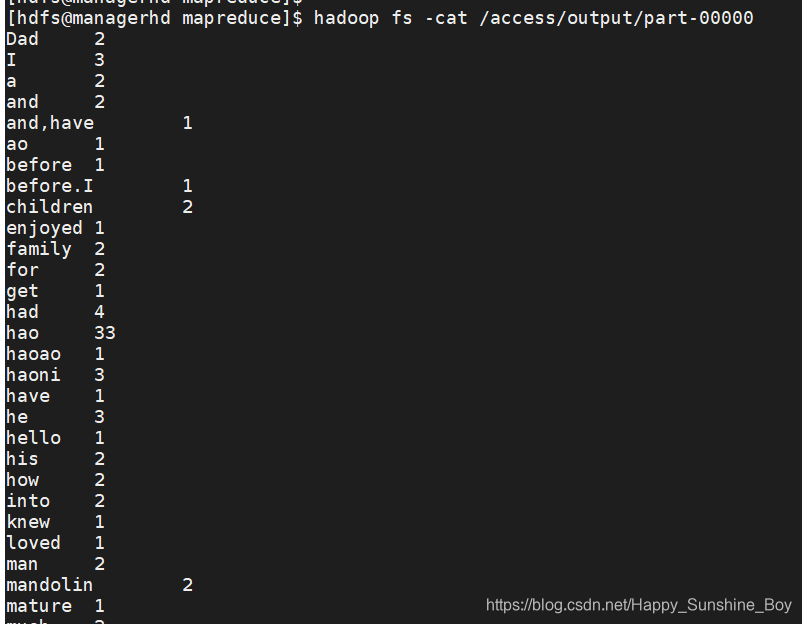
4.统计单词量

