Spark系列文章 java实现Pi、WordCount任务程序部署到yarn

Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark
在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。

环境
| 组件 | 版本 |
|---|---|
| CentOS (4核 cpu 4G内存) | 7 |
| Apache Hadoop | 3.2.1 |
| JDK | 1.8 |
| Spark | 3.0.0 |
Apache Spark 部署
Spark下载

上传,解压
$ tar -zxvf spark-3.0.0.tgz -C /sda3/spark
解压之后的目录
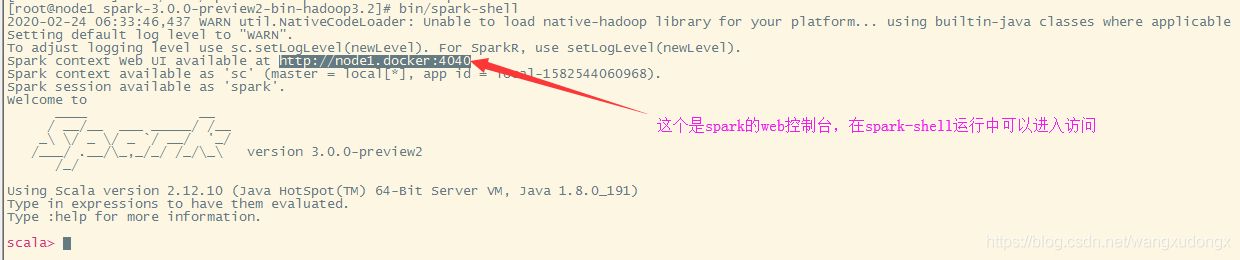
运行spark-shell
可以运行bin/spark-shell来使用scala进行交互式编程和查看spark的各种shell命令。

配置Spark使用yarn做资源管理
让我们先把yarn可调度的资源范围调大一些
yarn对集群资源调度的范围默认是0.1,这是在是有些小了,特别是在单机上,这很容易引发application申请不到资源的情况。
调整yarn对资源调度的范围: etc/hadoop/capacity-scheduler.xml
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.6</value>
<description>
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
applications.
</description>
</property>
配置yarn对节点内存的管理范围
配置文件:etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
在节点资源不富裕的情况下,以上两个配置是很重要的,不然很可能会出现,任务运行资源申请不到的情况或者是( java.nio.channels.ClosedChannelException异常)出现。
配置spark与yarn的连接
修改配置文件:conf/spark-env.sh
需要先将conf/spark-env.sh.template重命名为conf/spark-env.sh
然后增加配置项:
YARN_CONF_DIR=/sda3/hadoop-3.2.1/etc/hadoop
运行一个example检测配置的情况
java实现Spark程序
引入依赖
gradle
compile group: 'org.apache.spark', name: 'spark-core_2.12', version: '2.4.5'
码代码:写一遍Pi
import java.util.ArrayList;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
/**
* 计算Pi
*/
public class Pi {
public static final int NUM_SAMPLES = 1000;
public static void main(String[] args) {
List<Integer> l = new ArrayList<>(NUM_SAMPLES);
for (int i = 0; i < NUM_SAMPLES; i++) {
l.add(i);
}
// 获取配置:指定配置项 appname、master
SparkConf conf = new SparkConf().setAppName("myPI2").setMaster("yarn");
// .setMaster("local");
// 获取spark上下文
JavaSparkContext sc = new JavaSparkContext(conf);
// 计算过程
long count = sc.parallelize(l).filter(i -> {
double x = Math.random();
double y = Math.random();
return x*x + y*y < 1;
}).count();
// 结果输出
System.out.println("Pi is roughly " + 4.0 * count / NUM_SAMPLES);
}
}
java实现WordCount
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
/**
* 单词计数job
*/
public class WordCount {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("myWordCount2").setMaster("yarn");
// .setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
// 指定文件源
JavaRDD<String> textFile = sc.textFile("hdfs://192.168.84.133:9000/user/root/wordcount/input");
JavaPairRDD<String, Integer> counts = textFile
.flatMap(s -> Arrays.asList(s.split(" ")).iterator())
.mapToPair(word -> new Tuple2<>(word, 1))
.reduceByKey((a, b) -> a + b);
// 指定输出目录
counts.saveAsTextFile("hdfs://192.168.84.133:9000/user/root/wordcount/output");
System.out.println("=================================================================================");
System.out.println("wordcount is end");
System.out.println("=================================================================================");
}
}
打包
上传到服务器运行
将打好的jar包放到~目录
$ bin/spark-submit --class cn.spark.Pi --master yarn --deploy-mode client --executor-memory 512M --total-executor-cores 1 ~/ApacheSpark-0.0.2-alpha.jar
此过程比较慢,需要耐心等待
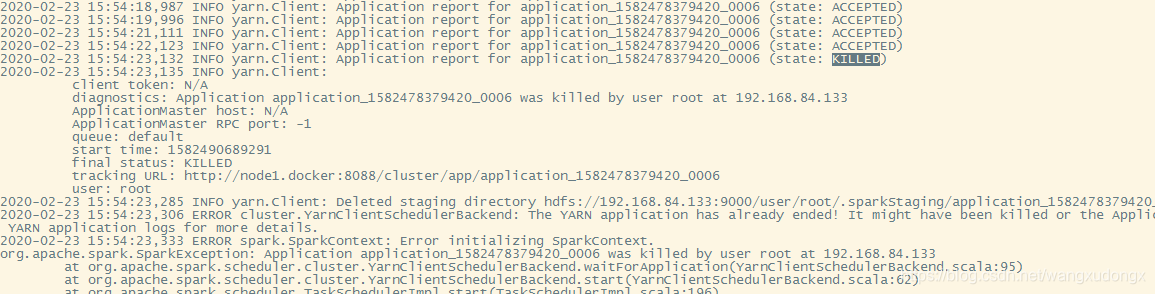
中间有可能会出现资源申请不下来的情况,有时等一下资源就会下来,也有很多时候回一直卡到申请资源那里。
这个就是在运行过程中申请了多遍才成功申请到运行job的资源
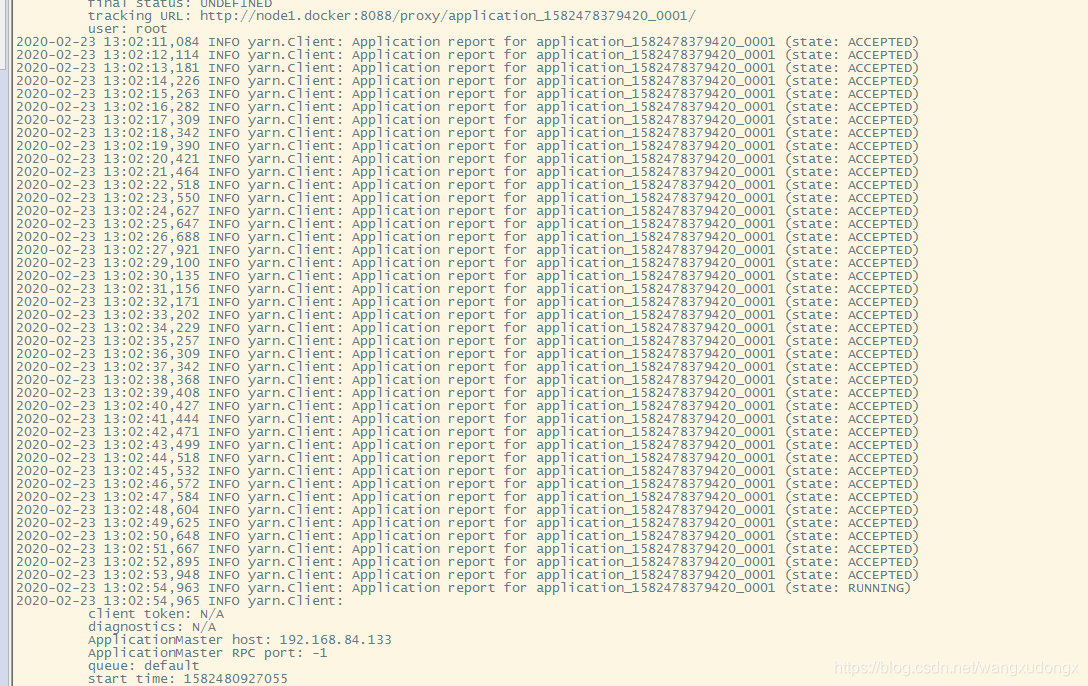
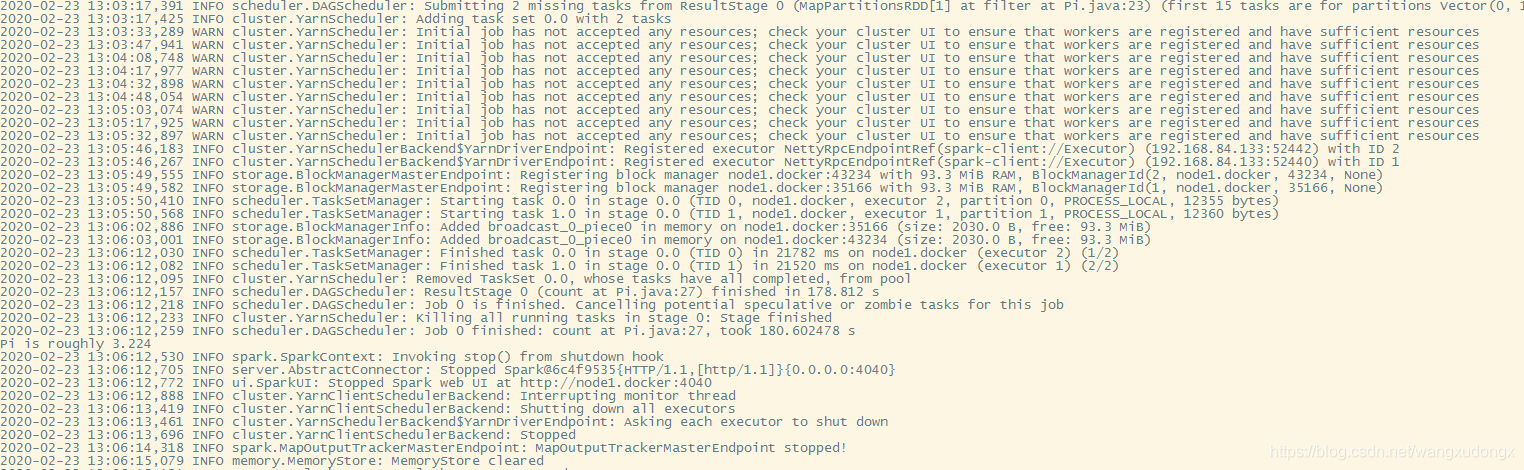
查看job运行状况
进到hadoop yarn的控制台:http://192.168.84.133:8088/cluster/apps

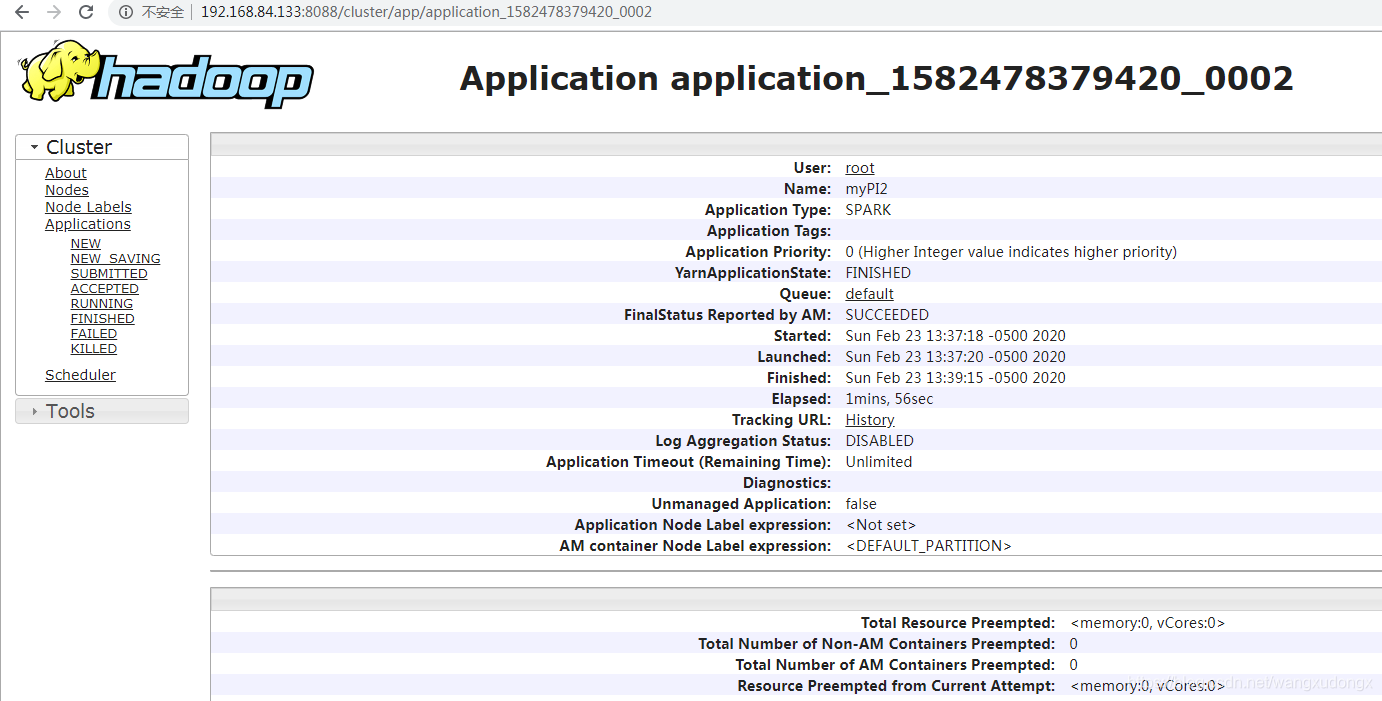
成功的输出
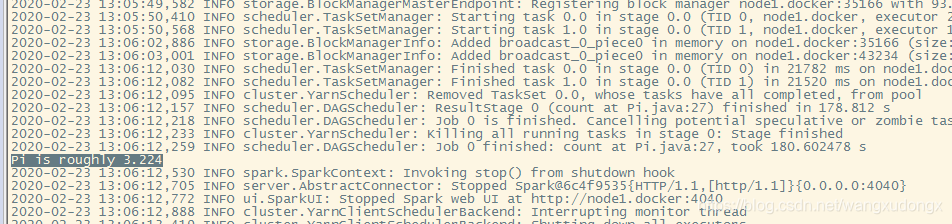
WordCount
准备测试用的文件
首先我们准备一些用来测试任务的文件。
因为我们用了hdfs,所以要创建相关目录,然后把文件放到里面。
$ hdfs dfs -mkdir /user/root/wordcount/input
$ hdfs dfs -copyFromLocal ~/index.html /user/root/wordcount/input
$ hdfs dfs -copyFromLocal ~/Overview.html /user/root/wordcount/input
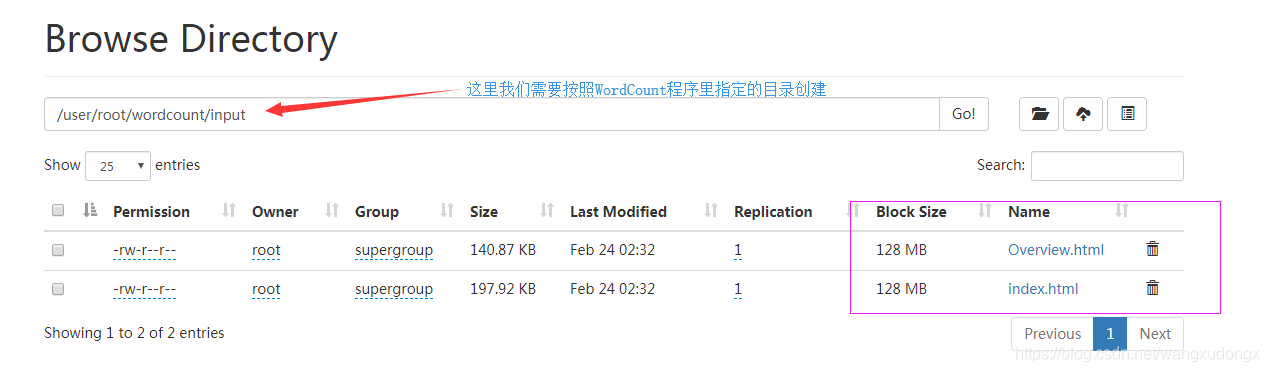
检测环境
查看各个组件的是否在正常运行:jps
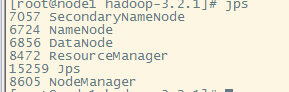
okay,都在。
查看系统负载:top


宿主机和客户机的负载都不高,应该可以。
提交任务
bin/spark-submit --class cn.spark.WordCount --master yarn --deploy-mode client --executor-memory 512M --total-executor-cores 1 ~/ApacheSpark-0.0.3-alpha.jar
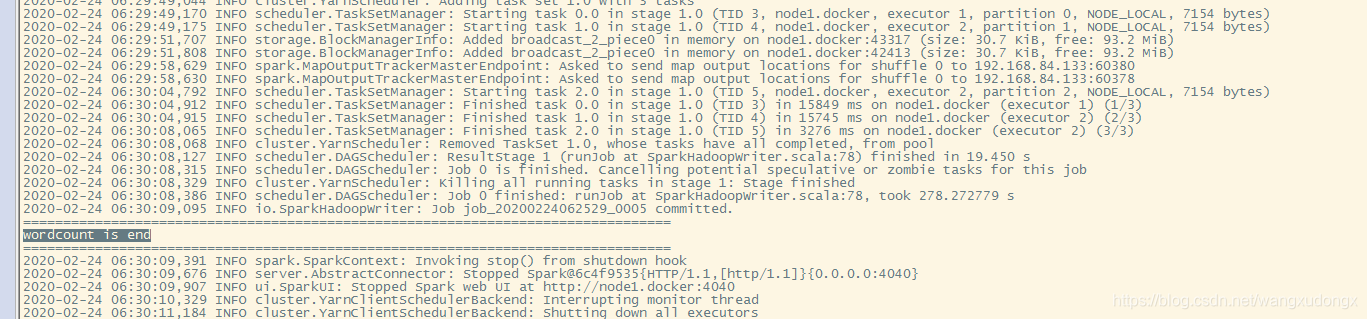
查看WordCount运行结果
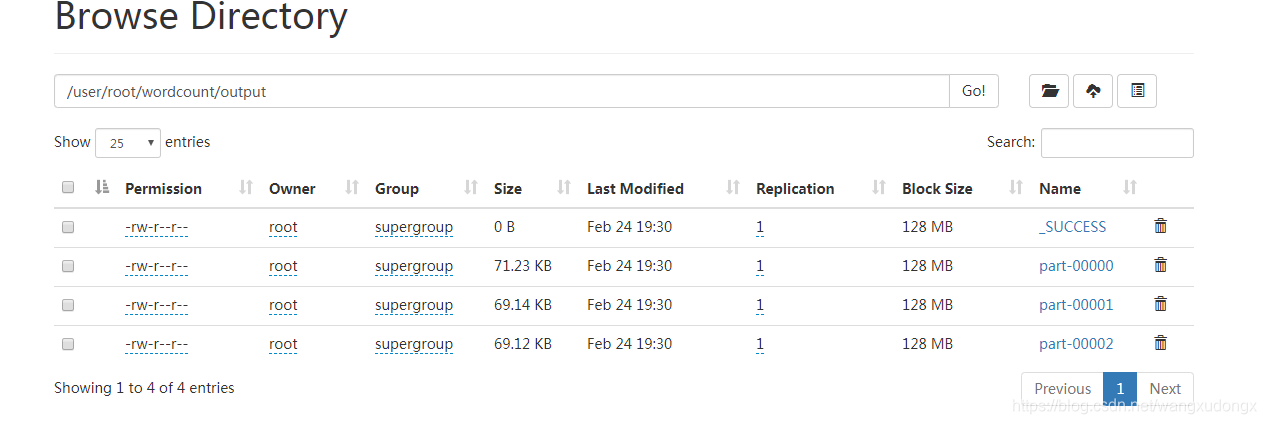
查看输出内容hdfs dfs -cat /user/root/wordcount/output/part-00000
可以到http://192.168.84.133:8088/查看任务运行状态
常见问题的处理
重新运行任务
如果是因为异常原因中断了任务,想要重新运行任务,需要手动做些清理:
- yarn application -list 查看是否有残留的任务,如果有就-kill掉
- 在用了hdfs之后,如果已经创建了output目录,再次运行任务会出现目录已存在的已存在的异常,使用 hdfs dfs -rm -r -f /user/root/wordcount/output 清理
- 出现
Failed to cleanup staging dir hdfs://192.168.84.133:9000/user/root/.sparkStaging/application_1582541540155_0003这是因为hdfs在安全模式下无法删除sparkstaging目录了,这样的情况下需要hdfs dfsadmin -safemode leave暂时关闭安全模式,然后手动删除一下sparkstaging目录。 - 如果你的节点性能不富裕的话最好在cpu、内存比较空闲的情况下spark-submit
卡到资源申请
如果碰到job一直卡到资源申请那里可以使用
查看application id
$ yarn application -list

然后kill掉
$ yarn application -kill application_1582478379420_0006