1.概述
- sqoop是一款
“Hadoop和关系数据库服务器之间传送数据”的工具;
- 将导入或导出命令翻译成mapreduce程序来实现,在翻译出的mapreduce中主要是对inputformat和outputformat进行定制;
导入数据(Import): MySQL,Oracle导入数据到Hadoop的HDFS、HIVE、HBASE等数据存储系统;导出数据(Export): 从Hadoop的文件系统中导出数据到关系数据库mysql等;

2.启动
[root@managerhd ~]# cd /usr/hdp/3.1.0.0-78/sqoop
[root@managerhd sqoop]# ./bin/sqoop-version

3.导入【Import】
3.1 测试Sqoop与MySQL之间的连通性
[root@managerhd sqoop]# ./bin/sqoop-list-databases --connect jdbc:mysql://managerhd.bigdata:3306 --username root --password bigd*****3


./bin/sqoop-list-tables --connect jdbc:mysql://managerhd.bigdata:3306/userdb --username root --password bigd*****3

3.2 将MySQL数据表导入HDFS指定目录
- 将 userdb 数据库中的 test_1 表导入HDFS /sqooptest 目录
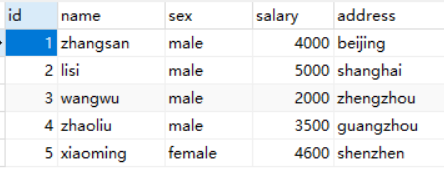
- 切换 hdfs 用户
[root@managerhd sqoop]# su hdfs
[hdfs@managerhd sqoop]$ ./bin/sqoop import \ # import导入
> --connect jdbc:mysql://managerhd.bigdata:3306/userdb \ # mysql jdbc连接
> --username root \ # 数据库用户名
> --password bigd*****3 \ # 数据库密码
> --table test_1 \ # 指定mysql数据表
> --target-dir /sqooptest \ # hdfs 目录
> --fields-terminated-by ',' \ # 数据分隔符
> --split-by id \ # 拆分数据
> --m 2 # 指定2个maptask数量,默认指定4个maptask数量

3.3 将MySQL数据表导入Hive
- 将 userdb 数据库中的 test_1 表导入Hive
[root@managerhd sqoop]# su hive
[hive@managerhd sqoop]$ ./bin/sqoop import \
> --connect jdbc:mysql://managerhd.bigdata:3306/userdb \
> --username root \
> --password bigd*****3 \
> --table test_1 \
> --hive-import \
> --fields-terminated-by ',' \
> --split-by id \
> --m 2

3.4 导入表数据子集

[root@managerhd sqoop]# su hdfs
[hdfs@managerhd sqoop]$ bin/sqoop import \
> --connect jdbc:mysql://managerhd.bigdata:3306/userdb \
> --username root \
> --password bigd*****3 \
> --table test_1 \
> --where "sex ='female'" \
> --target-dir /wherequery \
> --fields-terminated-by ',' \
> --split-by id \
> --m 1
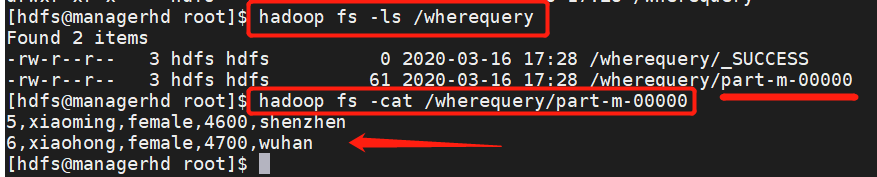
3.5 选择导入【增量导入 --query】
- mysql test_1 数据表新增三条数据,选择导入 id 不大于6,id,name,sex字段;

[hdfs@managerhd sqoop]$ bin/sqoop import \
> --connect jdbc:mysql://managerhd.bigdata:3306/userdb \
> --username root \
> --password bigd*****3 \
> --query 'SELECT id,name,sex FROM `test_1` where id <=5 and $CONDITIONS' \
> --target-dir /wherequery2 \
> --fields-terminated-by ',' \
> --split-by id \
> --m 1

3.6 增量导入
- 参考4:将 userdb 数据库中的 test_1 表导入HDFS /sqooptest 目录;
- mysql test_1 数据表新增三条数据;


[hdfs@managerhd sqoop]$ bin/sqoop import \
> --connect jdbc:mysql://managerhd.bigdata:3306/userdb \
> --username root \
> --password bigd*****3 \
> --table test_1 \
> --target-dir /sqooptest \
> --fields-terminated-by ',' \
> --split-by id \
> --m 1 \
> --incremental append \
> --check-column id \
> --last-value 5

4.导出【Export】
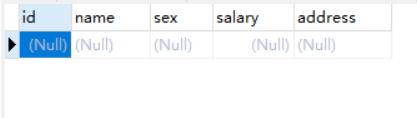
4.1 将HDFS目录数据导出到MySQL
- 将HDFS目录导出到 userdb 数据库中的 test_2 的空表中;
[hdfs@managerhd sqoop]$ bin/sqoop export \
> --connect jdbc:mysql://managerhd.bigdata:3306/userdb \
> --username root \
> --password bigd*****3 \
> --input-fields-terminated-by ',' \
> --table test_2 \
> --export-dir /sqooptest/

4.2 将hive的表数据(hdfs的文件)导出到mysql
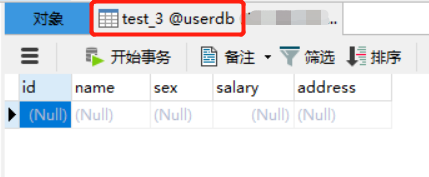
[root@managerhd sqoop]# su hive
[hive@managerhd sqoop]$ bin/sqoop export \
> --connect jdbc:mysql://managerhd.bigdata:3306/userdb \
> --username root \
> --password bigd*****3 \
> --table test_3 \
> --input-fields-terminated-by ',' \
> --export-dir /warehouse/tablespace/managed/hive/test_1/delta_0000001_0000001_0000/

