统计学
统计学是收集、处理、分析、解释数据并从数据中得出结论的科学。
数据分析所用的方法分为描述统计方法和推断统计方法。
(选择,判断,简答,计算<4,7,8,10,11>)
1.2
(1)计量尺度:
分类数据(只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,是用文字来表示)
顺序数据(只能归于某一有序类别的非数字型数据)
数值型数据(按数字尺度测量的观测值,其结果表现为具体的数值)
(2)收集方法:
观测数据(通过调查或观测而收集的数据)
实验数据(在实验中控制实验对象而收集到的数据)
(3)时间状况:
截面数据(在相同或近似相同的时间点上收集的数据)
时间序列数据(同一现象在不同的时间收集的数据)

1.3
总体(包含所研究的全部个体(数据)的集合)<参数:用来描述总体特征的概括性数字度量>
样本(从总体中抽取的一部分元素的集合)<统计量:用类描述样本特征的概括性数字度量>
变量:分类变量,顺序变量,数值型变量
2.2
(1)概率抽样:也称随机抽样,是指遵循随机原则进行的抽样,总体中每个单位都有一定机会被选入样本。
①简单随机抽样—>从含有N个元素的总体中,抽取n个元素作为样本,使得总体中的每一个元素都有相同的概率被抽中的抽样方式。
②分层抽样—>在抽样时,将总体分成互不交叉的若干个层级,然后按一定的比例,从各层次独立地随机抽取一定数量的个体,将各层次取出的个体合在一起作为样本。
③整群抽样—>先将总体划分为若干群体,然后以群作为抽样单位从中抽取部分群,再对抽中的各个群中所包含的所有元素进行观察的抽样方式。
④系统抽样
⑤多阶段抽样
(2)非概率抽样:指抽取样本时不是依据随机原则,而是根据研究目的对数据的要求,采用某种方式从总体中抽出部分单位对其实施调查。
①方便抽样
②判断抽样
③自愿样本
④滚雪球抽样
⑤配额抽样
搜集数据基本方法:自填式,面访式,电话式,试验式,观察式
2.4
抽样误差:样本量与抽样误差成反比。随着样本量的逐渐增大,抽样误差就越小。不可避免但可控制
非抽样误差:抽样框误差<仅在概率抽样中存在>,回答误差,无回答误差,调查员误差,测量误差。可避免可控制
误差的控制:通过样本量的大小控制可以改变误差大小,要求的抽样误差越小,所需要的样本量就越大。对于随机误差,提高样本容量;对于系统误差,只有做好准备工作并做好补救措施。
3.2
(1)分类数据的图示:
频数:是落在某个特定类别或组中的数据个数。
<条形图,帕累托图,饼图,环形图>(适用于所有数据)
(2)顺序数据的图示:
累积频数:是将各有序类别或组的频数逐级累加起来得到的频数。
<向上累积,向下累积>(适用于顺序数据,数值型数据)
(3)数值型数据的图示:(适用于数值型数据)
组距分组:组距=(最大值-最小值)÷组数
组距分组步骤:①确定组数②确定组距③根据分组整理成频数分布表
分组数据:<直方图>
未分组数据(原始数据):<茎叶图,箱线图>
时间序列数据:<线图>
多变量数据的图示:<散点图,气泡图,雷达图>

4计算题 4.1数据集中趋势
(1)分类数据:众数(Mo):一组数据中出现次数最多的变量值。
(2)顺序数据:
中位数(Me):是一组数据排序后处于中间位置上的变量值;
四分位数(QL,QU):一组数据处于25%和75%位置上的值
QL位置=n/4;
QU位置=3n/4;
整数位置:整数对应值;
0.5的位置:两侧值得平均值;
0.25或0.75的位置;下侧值+(上侧值—下侧值)*0.25或者0.75
(3)数值型数据:
平均数(简单平均数,加权平均数<频数>
几何平均数(计算平均比率和平均增长率)

(4)众数和中位数和平均数的比较:
左偏分布(众数Mo最大,平均数<中位数<众数);
右偏分布(众数Mo最小,众数<中位数<平均数);
对称分布(三者相等,众数=中位数=平均数)
4.2数据离散程度
(1)分类数据:
异众比率: 
fm为众数组的频数,比率越大,其他非众数组频数比重越大,该众数代表性越差
(2)顺序数据:四分位差Qd=QU-QL,数值越小,中间数据越集中
(3)数值型数据:
极差R=max(xi)-min(xi)
平均差(平均绝对离差)Md=Σ(∣xi-x∣)/n
方差s²=Σ((xi-x)^2)/(n-1)
标准差s
标准分数(z分数)zi=(xi-x)/s
离散系数: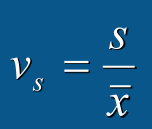 是离散程度的相对统计量,离散系数越大,数据离散程度也大
是离散程度的相对统计量,离散系数越大,数据离散程度也大
样本容量与置信水平成正比,与总体方差成正比,与边际误差成反比

5
离散型随机变量方差:D(X)=E(X²)-(E(X))²
离散系数:σ/E(X)
正态分布:X~N(μ,σ²),E(X)=μ,D(X)=σ²
二项分布:E(X)=np,D(X)=npq,P{X=x}=pχq1-χ,(x=0,1)
泊松分布:E(X)=λ,D(X)=λ,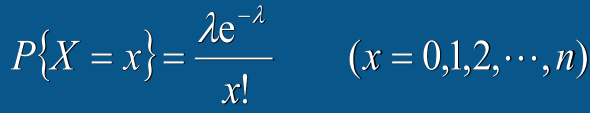
6
正态总体条件下:X²分布,t分布,F分布
中心极限定理:从均值为μ,方差为σ²的一个任意总体中抽取容量为n的样本,当n充分大时,样本均值的抽样分布近似服从均值为μ、方差为σ²/n的正态分布
样本均值X的抽样分布:X~N(μ,σ²/n)
样本均值的抽样标准误差:σ=σ/√n
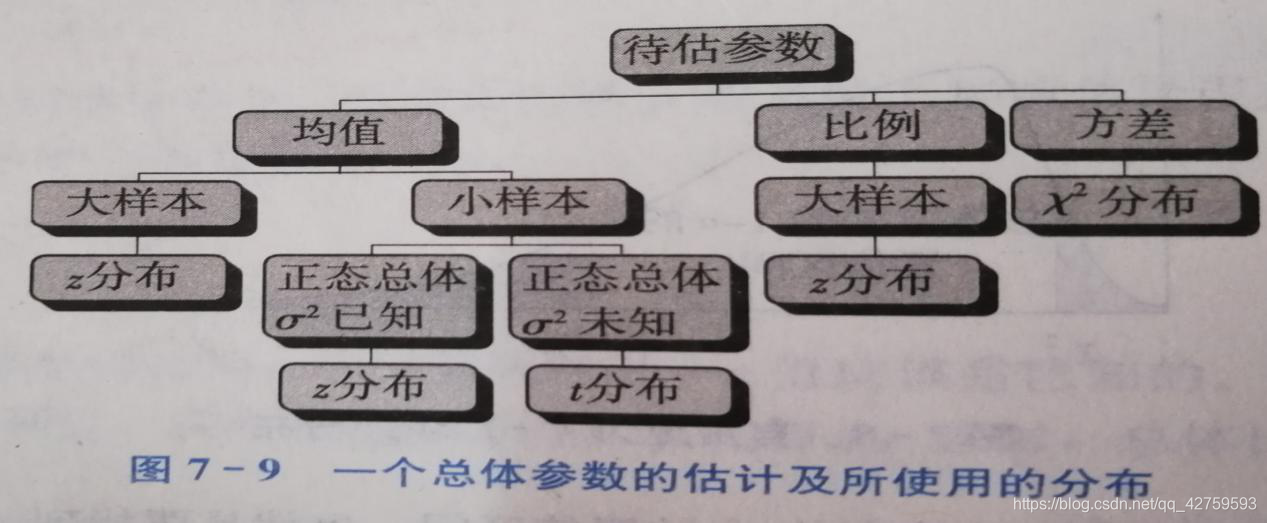
7计算题 7.1
估计量:用来估计总体参数的统计量
估计值:根据一个具体的样本计算出来的估计量的数值
参数估计:点估计,区间估计
评价估计量的标准:
无偏性(是指估计量抽样分布的数学期望等于被估计的总体参数)
有效性(较小标准误差的点估计量比其他点估计量相对有效,D(θ1)<D(θ2),θ1是比θ2更有效的估计量)
一致性(是指随着样本量的增大,估计量的值越来越接近被估计总体的参数,一个大样本给出的估计量要比一个小样本给出的估计量更接近总体参数)
7.2
总体均值的区间估计:
(1)正态分布、方差已知,或非正态分布、大样本z=(x-μ)/(σ/n½)~N(0,1),置信区间x±zα/2*(σ/n½)
(2)正态总体、方差未知、小样本t=(x-μ)/(s/n½)~t(n-1),置信区间x±tα/2*(s/n½)
总体比例的区间估计:z=(p-π)/(π(1-π)/n)½~N(0,1),置信区间p±zα/2*(p(1-p)/n)½
总体方差的区间估计:Χ²=(n-1)s²/σ²~Χ²(n-1),置信区间为
(n-1)s²/Χ²α/2<= σ² <=(n-1)s²/Χ²(1-α/2)
8计算题 8.1
α错误(弃真错误)
β错误(取伪错误)
<α和β两类错误不能同时减少>
拒绝原真假设的概率为α,也称为显著性水平
假设检验的过程:
①提出原假设H0和备择假设H1
②确定适当的检验统计量,并计算其数值
③进行统计决策
P值决策:P值越小,拒绝原假设的理由越充分(双侧:P<α/2拒绝原假设,P>α/2不能拒绝原假设;单侧:P<α拒绝原假设,P>α不能拒绝原假设)
8.2
总体均值的检验:
(1)样本量大:z统计量z=(x-μ0)/(σ/n½),单侧检验z和zα比较,双侧检验z和zα/2比较
(2)样本量小、σ已知:z统计量z=(x-μ0)/(σ/n½),单侧检验z和zα比较,双侧检验z和zα/2比较
(3)样本量小,σ未知:t统计量t=(x-μ0)/(s/n½),单侧检验t和tα(n-1)比较,双侧检验t和tα/2(n-1)比较
总体比例的检验:z统计量z=(p-π0)/(π0(1-π0)/n)½,单侧检验z和zα比较,双侧检验z和zα/2比较
总体方差的检验:Χ²统计量Χ²=(n-1)s²/σ²,单侧检验Χ²和Χ²α(n-1)比较,双侧检验Χ²和Χ²α/2(n-1)比较

9.1
分类数据(Χ²检验是对分类数据的频数进行分析的统计方法)
Χ²统计量Χ²=Σ((f0-fe)²/fe),f0为观察值频数,fe为期望值频数
9.4列联表中相关测量
Φ相关系数:Φ=(Χ²/n)½
列联相关系数:c=(Χ²/(Χ²+n))½
V相关系数:V=(Χ²/(n*min[(R-1),(C-1)]))½
10计算题 10.1
方差分析是比较多个总体的均值是否相等的统计方法,分类型自变量对数值型因变量是否有显著影响
方差分析三个基本假定:
(1)每个总体都服从正态分布
(2)各个总体的方差σ²必须相同
(3)观测值是独立的
方差分析的过程:
①提出假设H0:μ1=μ2=…=μk;H1:μi(i=1,2,…,k)不全相等
②构造检验的统计量F统计量
③作出统计决策
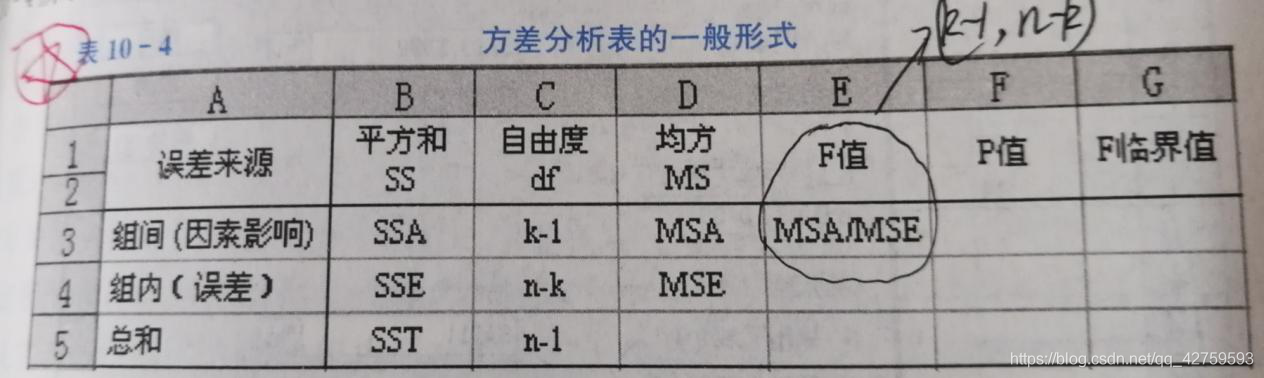
④方差分析表
10.2(p215的表,习题10.4)
总平方和(SST)=组间平方和(SSA)+组内平方和(SSE)
组间均方:MSA=SSA/(k-1)
组内均方:MSE=SSE/(n-k)
F统计量:F=MSA/MSE~F(k-1,n-k)
F>Fα(k-1,n-k),则拒绝原假设,总体均值有显著差异,分类型自变量对数值型因变量有显著影响;F<Fα(k-1,n-k),则不能拒绝原假设,总体均值无显著差异。
判定系数(平方根R为相关系数):R²=SSA/SST (R²∈[0,1])
多重比较方法:
①提出假设H0:μi=μj;H1:μi≠μj
②计算检验统计量:xi-xj
③计算LSD=tα/2(MSE*(1/ni+1/nj))½
④做出决策:∣xi-xj∣>LSD,拒绝H0
11计算题 11.1
相关系数:
r=(nΣxy-ΣxΣy)/((nΣx²-(Σx)²)½*(nΣy²-(Σy)²)½)r∈[-1,1],r=0只表示两个变量不存在线性相关关系,并不说明变量之间没有任何关系,∣r∣->1说明两个变量之间线性关系越强,∣r∣->0说明两个变量之间线性关系越弱
r的显著性检验:
①提出假设:H0:ρ=0;H1:ρ≠0
②计算检验统计量:t=∣r∣*((n-2)/(1-r²))½~t(n-2)
③进行决策:∣t∣>tα/2(n-2),拒绝原假设H0,表明总体的两个变量之间存在显著的线性关系。
11.2(p247的表,习题11.4)
一元线性回归
参数的最小二乘估计:求β1,β0(p247的表,习题11.4)
β1=(nΣxy-ΣxΣy)/(nΣx²-(Σx)²)
β0=y-β1X
判定系数R²=SSR/SST
显著性检验:
(1)线性关系检验:
①提出假设:H0:β1=0(两个变量之间的线性关系不显著)
②计算检验统计量:F=(SSR/1)/(SSE/(n-2))=MSR/MSE~F(1,n-2)
③进行决策:F>Fα(1,n-2),拒绝H0,两个变量之间的线性关系是显著的
(2)回归系数检验:
Sβ1=se/(Σxi²-1/n*(Σxi)²)½,se是σ的估计量
①提出假设:H0:β1=0;H1:β1≠0
②计算检验统计量:检验β1是否等于0,t=β1/Sβ1~t(n-2)
③进行决策:t>tα/2(n-2),拒绝原假设H0,自变量x对因变量y的影响是显著的
!!!
(1)相关分析的两个变量是对等关系;只能计算出一个相关系数;变量都是随机的或者其中一个是随机的。
(2)回归分析的两个变量不是对等关系;必须根据研究目的确定自变量和因变量;可以根据目的不同建立不同的回归方程;自变量是可以控制的变量(给定的变量),因变量是随机变量。



12 12.4
多重共线性:回归模型中两个或以上的自变量彼此相关时,称回归模型中存在多重共线性。
暗示存在多重共线性:①模型各对自变量之间显著相关②线性关系检验显著,回归系数检验不显著③回归系数的正负号与预期的相反
选择自变量的方法:向前选择,向后剔除,逐步回归,最优子集
13.1
时间序列:是同一现象在不同时间的相继观察值排列而成的序列
分成平稳序列(随机)和非平稳序列(包含:趋势,季节性,周期性)
13.2
增长率
平均增长率(几何平均数减1)G=ⁿ√(Yn/Y0)-1
时间序列观察值出现0或者负数时,不宜计算增长率;不能单纯就增长率论增长率,要注意增长率与绝对水平的综合分析
13.3

