这里全程以df这个为例来讲解
import pandas as pd
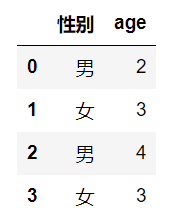
df=pd.DataFrame({'性别':['男','女','男','女'],'age':[2,3,4,3]})
df
get_dummies处理
pd.get_dummies(df,columns=['性别','age'])
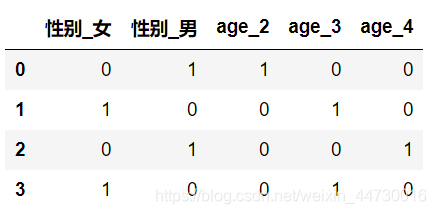
get_dummies可以对多列(字符型和数值型)直接进行哑变量编码
缺点:如果在测试集中出现了训练集没有出现过的类型,简单的用get_dummies会出现错误,比如训练集中的性别是男、女,而在测试集中有男、女、未知这三种类型的特征出现,直接用get_dummies处理的话两个数据集生成的哑变量特征数不一致。
标题OneHotEncoder
对于OneHotEncoder只能对于数值型特征进行编码,对于字符串编码会报错
import warnings
warnings.filterwarnings("ignore")
from sklearn.preprocessing import OneHotEncoder
enc=OneHotEncoder(sparse=False).fit(df[['age']])
enc.transform([[2],[4],[3]])
这里如果transfrom出现的是fit没有出现过的类型,会报错,有以下两种处理办法:
方法一:在n_values自己指定特征的维度
说明1:如果transfrom里出现的是fit里面没有出现过的特征值,而且这个特征值比原先fit的值小或者介于原先的特征值之间,此时不需要处理,系统会默认把这些值都当作0处理,如例子里面年龄是2,3,4,当tansform里面取0或1,是默认会变成[0,0,0],如下面的示例:
#示例一
enc=OneHotEncoder(sparse=False).fit(df[['age']])
enc.transform([[2],[3],[0]])
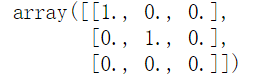
#示例二
x=OneHotEncoder(sparse=False).fit([[5],[3]])
x.transform([[4],[0],[1],[2]]) #可以简单理解为比最大值小的特征值都能表示(这里需要都是正数)
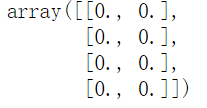
说明2:如果transfrom里出现的是fit里面没有出现过的特征值,而且这个特征值比原先fit的最大值大,那需要自己设定特征维度,否则会报错。这里要特别说明:维度的数值不是任意取的,如果原先的数值类型有2,3,4这三个数,系统默认是生成三个维度表示,如果要完全表示这个特征,那么维度最小是5,编码时会按照0,1,2,3,4进行编码, 所以要想要自己指定维度数,设置的值的范围是transform中的最大值+1(因为是从0开始编码,所以要加1,如上面就是4+1=5)
#示例一
enc=OneHotEncoder(sparse=False,n_values=[5]).fit(df[['age']])
enc.transform([[2],[3],[4]]) #完全显示的话就需要设置特征维度为4+1=5
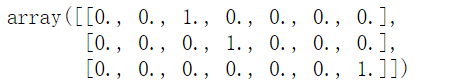
#示例二
x=OneHotEncoder(sparse=False,n_values=7).fit([[5],[3]])
x.transform([[6]]) # max_num+1=6+1=7
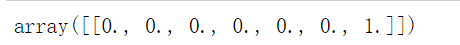
方法二设定忽略未知值
#这种方法比较简便,而且实际应用也较多
enc=OneHotEncoder(sparse=False,handle_unknown='ignore').fit(df[['age']])
enc.transform([[2],[6],[5]])

enc=OneHotEncoder(sparse=False).fit(df[['age','等级']])
enc.transform([[3,2],
[0,2]])
onehot和get_dummies一样,同样可以对多列特征进行转化处理

- 总结:onehot可以设置参数,使用fit,transfrom确保训练集和测试集的特征一样。测试集中出现了训练集中没有出现过的特征,可以使用上述两种方法(方法二较优)进行处理避免报错。
- 但是缺点是只能对数值型特征进行处理,对于字符串型,需要通过如下的处理方法:
LabelEncoder+OnehotEncoder
from sklearn.preprocessing import LabelEncoder
L=LabelEncoder()
x1=L.fit_transform(df['性别'])
enc=OneHotEncoder(sparse=False,handle_unknown='ignore').fit(x1.reshape(-1,1))
enc.transform(x1.reshape(-1,1))
缺点:对于未知的新数据还是不能进行很好的transform.
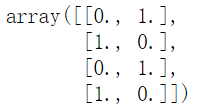
更加便捷的方法:管道处理(推荐)
transfrom中遇到与fit时不一致的数据的时候,结合OneHotEncoder设定忽略未知值的参数,可以把测试集中训练集没有出现过的值全填充为0。
这里在生成一个df1进行说明讲解。
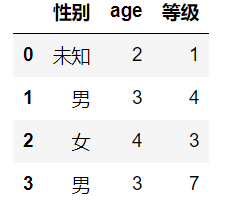
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
cat_transformer=Pipeline([('onehot',OneHotEncoder(handle_unknown='ignore'))])
preprocessor=ColumnTransformer(transformers=[('cat',cat_transformer,['性别','等级'])])
p1=Pipeline([('pre',preprocessor)])
p1.fit_transform(df)
#这里用ColumnTransformer是因为实际操作的时候可能不单单对分类变量进行处理,也会对数值型变量进行缺失值的处理等,可以都放入ColumnTransformer里面进行捆绑处理,进行特征高效处理

p1.transform(df1)

#这里也可以更加简便些
cat_transformer=Pipeline([('onehot',OneHotEncoder(sparse=False,handle_unknown='ignore'))])
cat_transformer.fit_transform(df[['性别','等级']])
cat_transformer.transform(df1[['性别','等级']])

