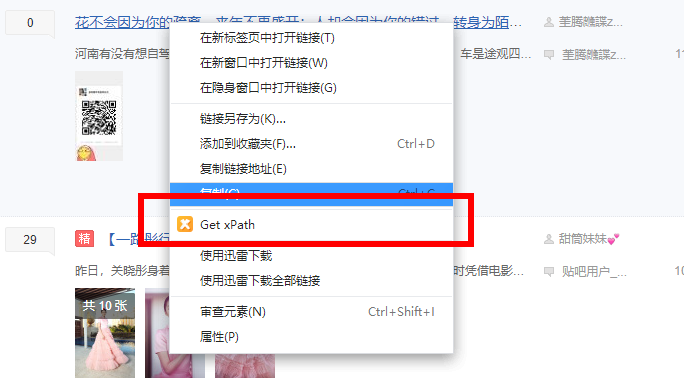
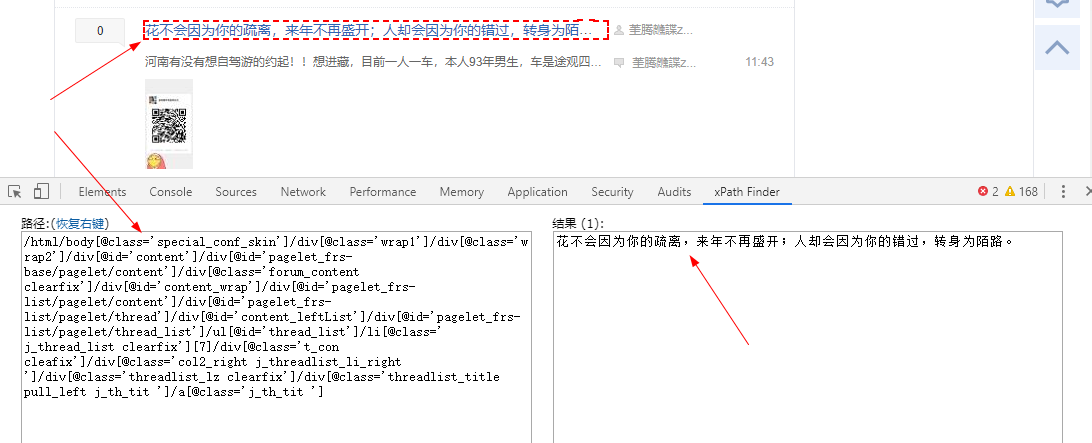
1. 使用xpath插件,进行筛选
直接鼠标在想筛选的文字或者图片,右键,就有xpath,然后F12,修改修改就可以了
------------------------------------
2.编写代码
from lxml import etree import re,time,os,random import requests from urllib import parse from fake_useragent import UserAgent class BaiduTiebaSpider(object): def __init__(self): self.baseurl = r'http://tieba.baidu.com/f?kw={}&pn={}' self.title_baseurl = r'https://tieba.baidu.com{}' self.picXpath = r'//cc//img[@class="BDE_Image"]/@src' self.titleurlXpath = r'//li//a[@class="j_th_tit "]/@href' self.videoXpath = r'/div[@class="video_src_wrap_main"]/video/@src' self.ua = UserAgent() self.savePath = r'/home/user/work/spider/baidu/BaiduTieba/' def get_html(self,url): # header = {'User-Agent':self.ua.random} header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko'} res = requests.get(url=url,headers=header).content return res def parse_html(self,html): parse = etree.HTML(html) titlelink_list = parse.xpath(self.titleurlXpath) for li in titlelink_list: titleurl = self.title_baseurl.format(li) print(titleurl) self.save_html(titleurl) time.sleep(random.randint(2,3)) def save_html(self,url): html = self.get_html(url) parse = etree.HTML(html) piclinks = parse.xpath(self.picXpath) for pics in piclinks: self.save_img(pics,self.savePath+pics[-10:]) videolinks = parse.xpath(self.videoXpath) for videos in videolinks: self.save_img(videos,self.savePath+videos[-10:]) def save_img(self,imgurl,filename): img = self.get_html(imgurl) with open(filename,'wb') as f : f.write(img) print(filename,'DownLoad Sucess') def run(self): name = input('输入要查询的贴吧名称>') start = input('Start Page>') end = input('End Page>') mainurl = self.baseurl.format(parse.quote(name),0) print(mainurl) pagehtml = self.get_html(mainurl) self.parse_html(pagehtml) if __name__ == '__main__': spider = BaiduTiebaSpider() spider.run();
注意header
3.结果