前几天和朋友微信吹牛,这年头吹牛光发文字,根本解决不了问题,无法让他感觉到你此时的情绪波动,奈何自己平常不怎么注意盗图,导致自己在斗图这一环节败下阵来。当时那是一个气呀,我堂堂八尺男儿,怎么能被这样嘲讽,不能忍,我大鱼人今天要教他做大人!!!

想着确实好久没有写爬虫,之前在学习的时候,线程的消费者和生产者队列也该拿出来实践实践了。
逻辑梳理
使用queue来做队列,生产者调用来个queue,一个url_queue,一个img_queue。url_queue主要用来存储网站的初始链接,请求后获取表情包具体的url,再将表情包url传给img_queue并且下载到本地。生产者和消费者的逻辑就搭建起来了,每个类各调用5个线程来采集图片。具体的代码如下,没有什么难度。
import time
import queue
import random
import requests
import threading
from lxml import etree
from fake_useragent import UserAgent
import os
ua = UserAgent(verify_ssl=False)
class CollectImage(threading.Thread):
def __init__(self,url_queue,img_queue):
super(CollectImage, self).__init__()
self.url_queue = url_queue
self.img_queue = img_queue
self.headers = {
"referer": "https://www.doutula.com/photo/list/?page=2",
"upgrade-insecure-requests": "1",
"user-agent": ua.random,
"cookie": "__cfduid=df6cea198a4b5c7aa4ec1435fd4dfb20b1579672813; _ga=GA1.2.375526924.1579672985; _gid=GA1.2.833521468.1579672985; UM_distinctid=16fcbd8df0b513-033e078ae44a09-3f385c06-ff000-16fcbd8df1187; CNZZDATA1256911977=335321636-1579670964-%7C1579670964; _agep=1579672988; _agfp=22be48d2d46c1d3a00053b9d658f6457; _agtk=1cbe52183be64e8a3441b05f0d7a2049; XSRF-TOKEN=eyJpdiI6Im9mUGlQUnpzSE9ob1U4MEJybFU0QXc9PSIsInZhbHVlIjoiWmtwTVM3KzdJbDhNaW5rS3Y5TGNJb1k3dnJBWmd1YnlhQXc0eWxzdmQrK0pvclpWS29zdG40eW5tNzhncVNlSyIsIm1hYyI6IjU2ODZiZDk1MjZlZjU1ZWU1NTQyZjIwZDY0ZmY3YWNlODYzNDM2OWRhMGJmZmZlMmIwYzk3ZjQwMTJiMGY0MmQifQ%3D%3D; doutula_session=eyJpdiI6ImtLcGpTUHdsVlRCZXAyME5PeWxBbUE9PSIsInZhbHVlIjoiRzNzbVdiXC9CbWR5UUNvTFNcL1hcLzFkU2htemhtbGplMVY4OVFabEhtUW5NMHAyXC9Lb0NLS1R3K0dzMGozSHY4dFwvIiwibWFjIjoiZDgzYjFkNTU3Yjk5Y2Q3MzdmZDk0MTNiODZjNjBhNTIwZTgwMGVkOTVhN2NjMTg5OWNiMjFmOWZmOGE4NTA5YyJ9; _gat=1"
}
def run(self):
# 当url_queue为空是,循环停止
while not self.url_queue.empty():
url = self.url_queue.get()
self.parse_url(url)
self.url_queue.task_done()
def parse_url(self,url):
req = requests.get(url=url,headers=self.headers)
html = etree.HTML(req.text)
a_list = html.xpath('//div[@class="page-content text-center"]//img')
for a in a_list:
img_url = "".join(a.xpath('./@data-original')).strip()
if img_url:
# 给下载img_queue提供下载地址
self.img_queue.put(img_url)
class DownloadImg(threading.Thread):
def __init__(self,img_queue):
super(DownloadImg,self).__init__()
self.img_queue = img_queue
self.headers= {
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Accept-Encoding":"gzip, deflate",
"Accept-Language":"zh,en-US;q=0.9,en;q=0.8,zh-CN;q=0.7,en-GB;q=0.6",
"Cache-Control":"no-cache",
"Connection":"keep-alive",
"Host":"ww2.sinaimg.cn",
"Pragma":"no-cache",
"Upgrade-Insecure-Requests":"1",
"User-Agent": ua.random
}
def run(self):
if os.path.exists("./IMAGES"):
pass
else:
os.makedirs('./IMAGES')
# 当img_queue队列为空,停止循环
while not self.img_queue.empty():
img_url = self.img_queue.get()
self.download_url(img_url)
self.img_queue.task_done()
def download_url(self,url):
# 下载到本地
filename = url.split('/')[-1]
print("正在下载--------", filename)
with open("IMAGES/" + filename, 'wb') as f:
f.write(requests.get(url, headers=self.headers).content)
if __name__ == '__main__':
start_time = time.time()
url_queue = queue.Queue()
img_queue = queue.Queue()
for page in range(1, 11):
url = 'https://www.doutula.com/photo/list/?page={0}'.format(str(page))
url_queue.put(url)
# 开启5个请求连接线程
for i in range(5):
t = CollectImage(url_queue, img_queue)
t.start()
t.join()
# 开启5个下载连接线程
for i in range(5):
t = DownloadImg(img_queue)
t.start()
t.join()
print('一共需要%s' % (time.time()-start_time))
上面采集了10页的表情包图片,一共用了31秒左右。
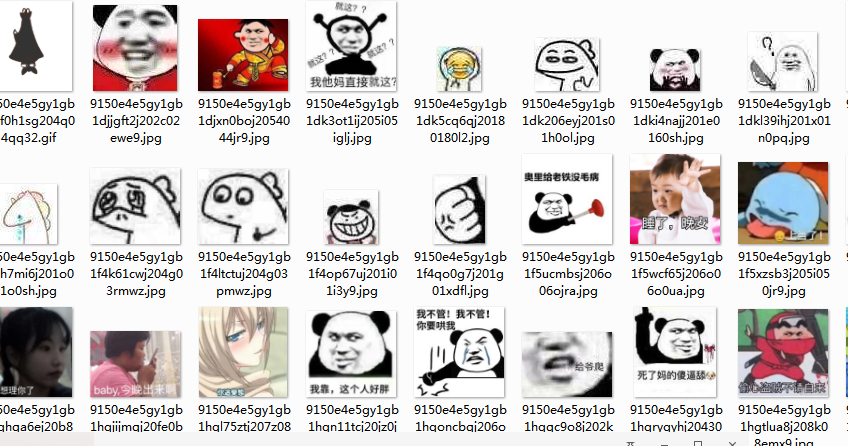
哈哈哈,以上就是全部的采集流程了,以后谁敢和我斗图,我就是一记重锤,直接K.O!!!
欢迎访问个人博客
