最近入坑了机器学习,为了快速提高自己的机器学习的代码能力,入坑了《机器学习实战》,目前只学习了第一个重要算法:k近邻算法(kNN),在学习过程中发现许多相关的学习资料要么代码是python2的,要么代码的解释不够详细,对于像我这样的菜鸡而言苦不堪言,为了后来者不踩我踩过的大坑,现在將这一章的学习笔记做一个小结,全文有些长,请根据自己的需要查看。
一.什么是kNN
首先上一段李航《统计学习方法》里kNN的算法总结

用人话来说就是,对于某一个群体里的某个个体,其某一特性取决于其周围最近的k个人的该特性的多数值。
举个例子,有一个100人的球迷群体,他们的主队分别是巴萨和皇马,现对于某一球迷(x),我们不知道他是皇马球迷还是巴萨死忠,我们依据k近邻算法可以对其主队(类)进行预测,假如取其周围最近的9个球迷(与x最邻近的k个点,这里k=9)来统计他们的主队(类别),发现其中5人为巴萨球迷,剩余4人为皇马球迷,我们就认为该球迷为巴萨球迷(多数表决)。
这个就是k近邻算法的基本原理,下面结合机器学习实战,將这一算法进行实践。
注:编程语言:python3.5,数据库来源:点击打开链接 打开后右侧随书下载——《机器学习实战》源代码.zip
二.第一个kNN算法实践
任务目标:自己创建一个基本数据集,并建立一个基本分类器,基于创建的基本数据集对某一数据进行分类
任务实施:
1.创建数据集
在kNNdemo3.py 文件输入下列代码:
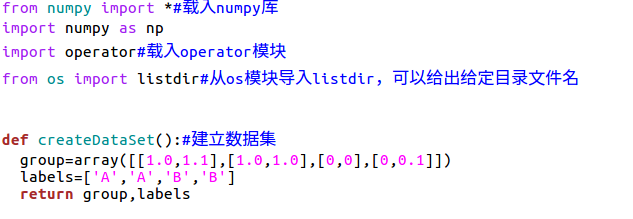
这样就建立了一个数据集,在这个数据集里,group代表了其具体坐标位置,labels代表了其标签(属性),下面基于该数据集建立了一个基本分类器,该分类器將通过坐标,对其可能的属性是‘A’还是‘B’进行预测。下面是分类器部分的代码:

注意:书里为python2.7的代码,所以倒数第三行书里用的是iteritems(),但在python3里已经被item()代替
下面在terminal里运行这个分类器:

这里首先载入python,载入数据集后对[0,0]和[3,3]通过分类器分别判断其标签是‘A’还是‘B’
三.使用k-近邻算法选择约会对象
任务目标:通过每年飞行里程数,玩视频游戏所耗时间,冰淇淋消耗数来确定约会对象是否是意中人
任务实施:
因为我们的数据是以文本形式存储的,所以需要將文本转换为numpy矩阵,以便于將其带入现有函数来分类。代码如下:

现在这一文本文件已经转换为了所需要的数组形式,现在这个问题就已经转换为之前的分类问题了,但是在分类前还需要对其进行归一化处理,代码如下:

现在,我们再將现有数据带入具体问题,以分类器的形式来实现这个问题,并集成为一个函数,代码如下:

现在在terminal上再对文本数据处理一下,看看该算法,对于这个数据集效果如何:
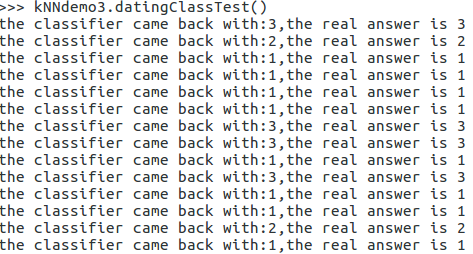
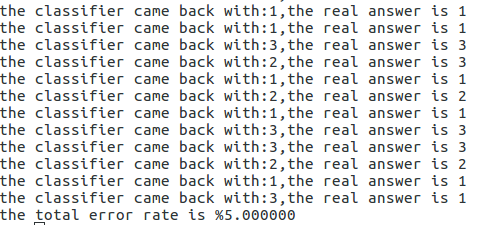
不难发现,其错误率只有5%,所以算法效果不错,故我们以此算法为基础,来实现对于约会对象满意度的预测模型,代码如下:
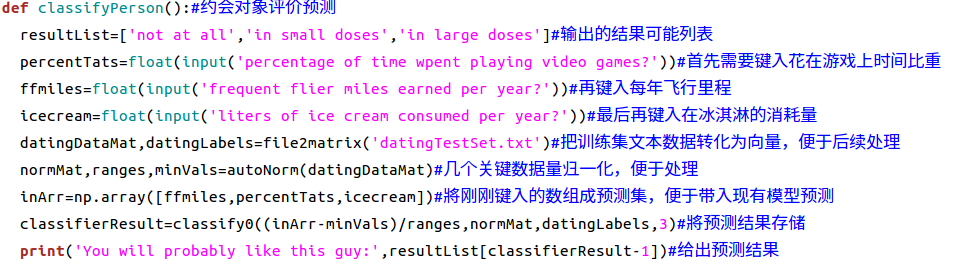
现在我们在terminal上对数据进行处理,对应的交互代码如下:

这一段代码首先重载了kNNdemo3这个模块,每一次更新代码后都需要重载模块,值得注意的是,原来书上写的reload(kNNdemo3),但是在python3里不能这么写,必须现载入imp模块,再reload。后面执行的就是预测模型,以预测是否合适。
四.手写识别算法
任务目标:通过训练模型,希望模型能准确识别0-9的数字图像
任务实施:
首先要对图像进行预处理,前面我们获取的均是向量,虽然图像本质上也是种向量,但这种向量并不是我们之前分类器所使用的向量,为了方便处理,这里我们將图像均依次转化为一维向量,代码如下:

下面就是带入一个分类器,来实现手写图像识别,,在这里使用了listdir方法和skelearn库,以便于后面运算,这里需在文件里加上这两行代码:

再写入手写图像识别函数:

最后在terminal上运行这个函数,得到的结果如下:

错误率只有1.34%,令人满意,所以我们可以认为这个算法满足我们的需要。
注:本文参考资料:李航《统计学习方法》,Peter Harrington《机器学习实战》,手写识别系统sklearn代码源自Jack Cui,其主页:点击打开链接