#coding=utf-8
'''
爬虫豆瓣电影,支持分年代爬取
'''
import time
import requests
import os
import re
import json
import Save_Data
import logging
#定义日志级别及日志文件名
logging.basicConfig(
# 日志级别
level = "ERROR",
# 日志打印时间格式
datefmt = "%Y-%m-%d %H:%M:%S",
# 日志打印内容格式
format = '%(asctime)s %(filename)s[line:%(lineno)d] %(message)s',
# 日志输出到文件
filename = ("log_2010.txt"),
# 覆盖模式
filemode = 'w'
)
# 定义请求头
headers = {
"Referer":"https://movie.douban.com/explore",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
# 定义获取年份的时间区间
year_dict = {
"80年代":"1980,1989",
"90年代":"1990,1999",
"2000年代":"2000,2009",
"2010年代":"2010,2019",
}
# 定义各个年代获取的电影页数
max_page = {
"80年代":"376",
"90年代":"752",
"2000年代":"1342",
"2010年代":"2315",
}
def get_doubanmovie_index(time_start,idx,headers):
'''
获取电影类别页面内容
:param movie_type:电影类别
:param headers:请求头部信息
:return:电影类别页面数据
'''
global proxy
proxy= ''
my_proxy = {
'http': 'http://' + proxy,
'https': 'https://' + proxy,
}
logging.error(proxy)
logging.error(my_proxy)
# page_idx = idx * 20
url = "https://movie.douban.com/j/new_search_subjects?" \
"sort=U&range=0,10&tags=%E5%8A%A8%E6%BC%AB&start={}" \
"&countries=%E6%97%A5%E6%9C%AC&year_range={}".format(idx,time_start)
try:
logging.error(my_proxy)
ret = requests.get(url,headers=headers,timeout=(2,4))
# ret.raise_for_status() #判断http头中的状态码是否为200
except:
print("获取电影:%s 页面内容出错;url:%s"%(time_start,url))
logging.error("获取电影:%s 页面内容出错;url:%s"%(time_start,url))
logging.error('')
return ""
return ret.text
def get_movie_list(data):
'''
解析电影页面数据,主要为了获取电影名称及电影详情页url
:param data:电影类别页面数据
:return:电影名称及电影详情页url
'''
movie_list = []
try:
tmp_data = json.loads(data)
subjects_data = tmp_data["data"]
for i in subjects_data:
movice_name = i["title"]
movie_url = i["url"]
movie_list.append([movice_name,movie_url])
except:
print("获取电影名称及电影详情页失败~")
logging.error("获取电影名称及电影详情页失败~")
logging.error(data)
if len(movie_list) == 0:
logging.error(data)
return []
return movie_list
def movie_content_page(url,headers):
'''
获取电影详情页内容
:param url:电影详情页url
:param headers:请求头
:return:电影详情页数据
'''
global proxy
my_proxy = {
'http': 'http://' + proxy,
'https': 'https://' + proxy,
}
logging.error(proxy)
logging.error(my_proxy)
try:
logging.error(my_proxy)
ret = requests.get(url,headers = headers,timeout=(2,4))
# ret.raise_for_status()
except:
# proxy = MyProxy.get_proxy()
print("获取电影详情页失败,url:%s"%url)
logging.error("获取电影详情页失败,url:%s"%url)
logging.error('')
return ""
return ret.text
def handle_movie_data(data):
'''
解析电影详情页数据,提取演员表、剧情介绍
:param data:电影详情页所有数据
:return:电影演员表
:return:电影剧情介绍
'''
movie_info = []
mark_pattern = re.compile('property=\"v:average\">(.*?)</strong>')
mark_and_count = re.findall(mark_pattern,data)
count_pattern = re.compile('property=\"v:votes\">(.*?)</span>')
count = re.findall(count_pattern,data)
movie_year_pattern = re.compile('\"datePublished\".*?:.*?\"(.*?)\"')
movie_name_pattern = re.compile('property=\"v:itemreviewed\">(.*?)</span>')
movie_name = re.findall(movie_name_pattern,data)
movie_year_bk = re.findall('class=\"year\">(.*?)</span>',data)
movie_year = re.findall(movie_year_pattern,data)
try:
#电影名称
_name = (movie_name[0])
except:
_name = ""
try:
# 电影年份
_year_bk = (str(movie_year_bk[0]).replace("(","").replace(")",""))
except:
_year_bk = ""
try:
_year = (movie_year[0])
except:
_year = ""
try:
_count = (count[0])
except:
_count = ""
try:
_mark = (mark_and_count[0])
except:
_mark = ""
try:
movie_info.append([_name,_year_bk,_year,_mark,_count])
except:
print("err")
logging.error("ERROR movie_name:%s movie_year:%s movie_mark:%s movie_count:%s"%(
movie_name,
movie_year_bk,
movie_year,
mark_and_count,
count))
return movie_info
def main(year_type,count):
global proxy
my_count = 1
mk_path = '数据集' + "\\" + year_type
# 类别文件夹如果不存在,就创建
if not os.path.exists(mk_path):
os.makedirs(mk_path)
# 提取开始年份
time_start = year_dict.get(year_type)
for idx in range(count):
page_idx = idx * 20
if page_idx > int(max_page.get(year_type)):
break
for i in range(5):
# 获取该类别的电影主页内容
index_data = get_doubanmovie_index(time_start,page_idx,headers)
# 解析该主页内容,得到["电影名称","电影详情页url"]
movie_url_list = get_movie_list(index_data)
if len(index_data) > 0 and len(movie_url_list) > 0:
break
else:
logging.error("------------%s"%proxy)
time.sleep(2)
if i > 3:
break
logging.error("第%d页获取成功! length_html:%d"%(
(page_idx+1),
len(index_data)
)
)
for url_list in movie_url_list:
logging.error(url_list)
movie_url = url_list[1]
for i in range(5):
# 获取电影详情页的内容
movie_content_data = movie_content_page(movie_url, headers)
# 获取电影演员表及剧情介绍
movie_info_list = handle_movie_data(movie_content_data)
if len(movie_content_data) > 0 and len(movie_info_list) > 0:
print('已经获取%d部电影数据'%my_count)
my_count += 1
break
else:
logging.error("------------%s" % proxy)
if i > 3:
break
# 保存电影剧情介绍
Save_Data.save_content(mk_path,movie_info_list)
logging.error("第%d页获取成功! url:%s"%(
(page_idx+1),
url_list[1]
)
)
if __name__ == '__main__':
if not os.path.exists('数据集'):
os.mkdir('数据集')
# 定义需要爬取的类别列表
want_get_movie = ["80年代","90年代","2000年代","2010年代"]
# 定义爬取页数,每页20条
COUNT = 2315
# 遍历需要爬取的类别列表
for type_name in want_get_movie:
main(type_name,COUNT)
#coding=utf-8
'''
数据存储模块,保存电影数据
'''
import csv
import logging
def save_actor(file_path,data):
'''
保存电影演员信息
:param file_path:保存的路径信息
:param data: 电影演员信息
:return:
'''
file_name = file_path + "\\" + "演员表.csv" #在电影名的文件夹下,将数据保存到演员表.csv
o_file = open(file_name,"w",newline="",encoding="utf-8-sig")
f = csv.writer(o_file)
for i in data:
f.writerow(i)
o_file.close()
def save_content(file_path,data):
'''
:param file_path: 保存的路径信息
:param data: 电影信息
:return:
'''
try:
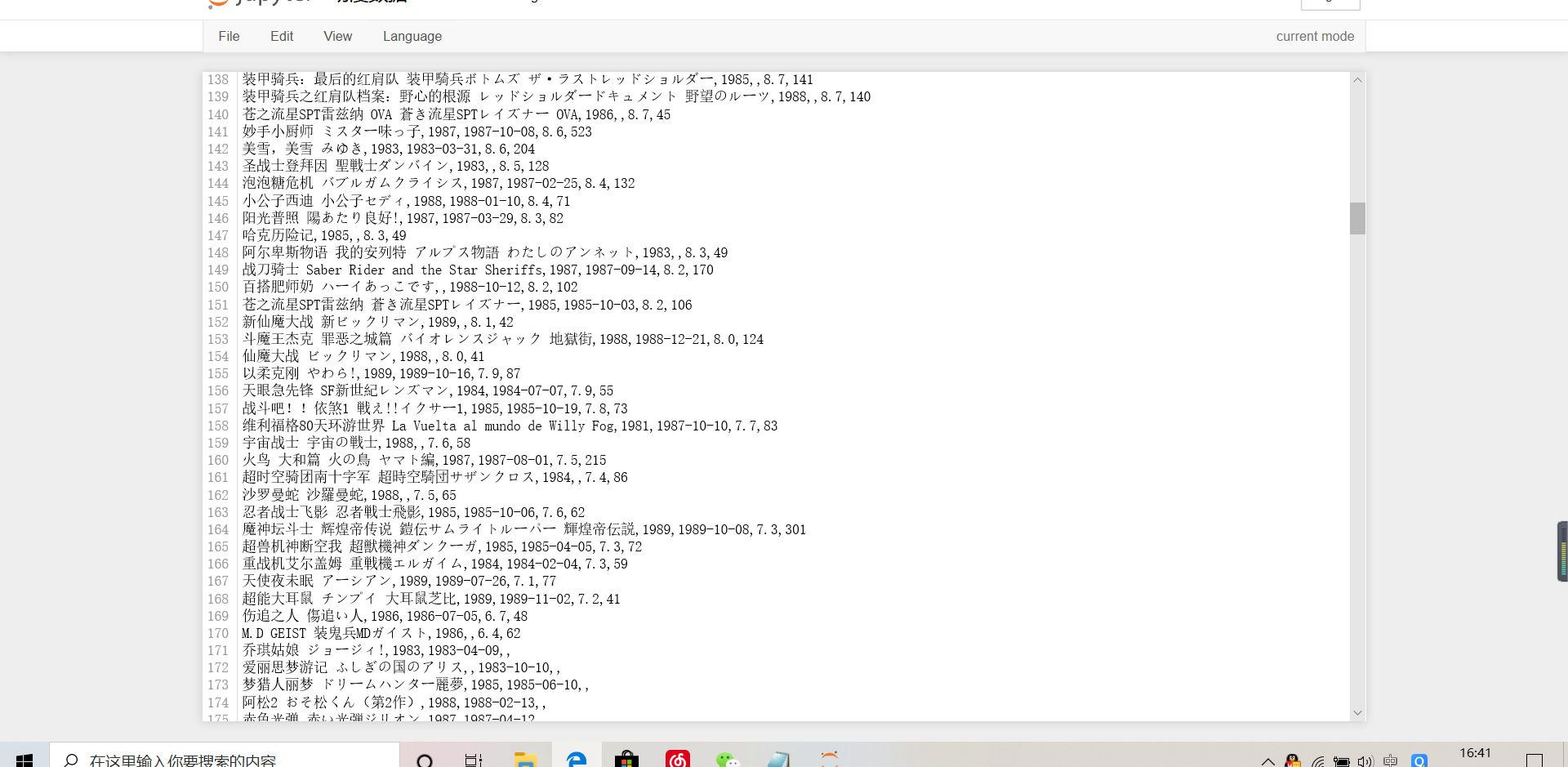
file_name = file_path + "\\" + "动漫数据.csv"
f = open(file_name, "a", encoding="utf-8-sig",newline="")
c_f = csv.writer(f)
for i in data:
c_f.writerow(i)
f.close()
except:
logging.error("保存数据失败:%s"%data)