一、元数据:
hdfs的根目录存在一个Person.txt文件,内容如下
1,tingting,23,80
2,ningning,25,90
3,ruhua,27,60
4,mimi,33,85二、用Spark Shell实现如下
2.1、取出来
val res=sc.textFile("hdfs://node01:9000/person.txt").map(_.split(","))注意:hdfs的端口是9000,spark-shell的端口是7077
2.2、转化成Person类
2.2.1、先定义Person类
case class Person(id:Int,name:String,age:Int,faceVal:Int)2.2.2、转化
val personRdd=res.map(x=>Person(x(0).toInt,x(1),x(2).toInt,x(3).toInt))2.3、查看
val personDf=personRdd.toDF2.3.1、结果如下
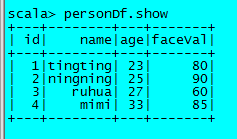
2.4、有DSL方式查看某一列,有好多种写法
2.4.1、用col
personDf.select(personDf.col("name")).show其中personDf这个前缀也可以省略。
2.4.1.1、显示多列用逗号分隔
personDf.select(personDf.col("name"),col("age")).show2.4.1.2、personDf和col只保留其一,下面的例子是将col省略
personDf.select(personDf("name"),personDf("age")+1).show注意:如果想要列+1,则只能用personDf或者col其中一种,纯列名的不行
2.4.2、直接用列名
personDf.select("name","faceVal").show2.4.3、filter
personDf.filter(personDf.col("age")>=24).show2.4.4、groupBy
personDf.groupBy("age").count.show2.5、用Sql方式
2.5.1、先注册临时表
personDf.registerTempTable("myTable")2.5.2、用sql查询
sqlContext.sql(" select * from myTable order by age desc limit 2").show2.5.3、结果如下
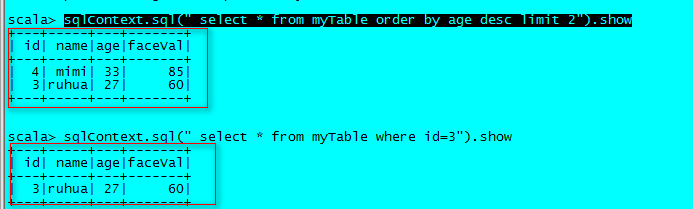
三、用代码实现如下
package scalapackage.testspark
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Germmy on 2018/5/28.
*/
object TestSparkSql {
def main(args: Array[String]) {
val sparkConf: SparkConf = new SparkConf().setAppName("TestSparkSql").setMaster("local[2]")
val sc: SparkContext = new SparkContext(sparkConf)
//1、引入sparkSqlContext
val sQLContext=new SQLContext(sc)
//2、剩下的和sparkShell逻辑一样
//2.1、读取文件
val lines: RDD[Array[String]] = sc.textFile(args(0)).map(_.split(","))//它为什么能够推断出来它就是可以被split,难道就是因为rdd[String]?
//2.2、转为personRdd
val personRdd: RDD[Person] = lines.map(x=>Person(x(0).toInt,x(1),x(2).toInt,x(3).toInt))
//2.3、转为dataFrame
import sQLContext.implicits._ //我操,竟然是引为sqlContext里面的implicit
val personDf: DataFrame = personRdd.toDF()
//2.4、注册表
personDf.registerTempTable("myTable")
//2.5、查询
val dataFrame: DataFrame = sQLContext.sql("select * from myTable order by age desc limit 2")
//2.6、写入Hdfs
dataFrame.write.json(args(1))
sc.stop()
}
}
case class Person(id:Int,name:String,age:Int,faceVal:Int)
运行结果如下
![]()
注意到:
3.1、要导入Pom
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.6.1</version>
</dependency>3.2、想要用personRdd.toDF,需要用到隐式转换,即sqlContext.implicits._
3.3、2个入参分别是:
hdfs://node01:9000/person.txt hdfs://node01:9000/output/testsparksql四、QA
Q1:报org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply in 10 seconds. This timeout is co
A1:启动时spark-shell时分配更多的内存和CPU,我这里是1G内存,CPU是4核,否则会因为运算太慢,被超时机制拦截。参考