排序算法——看这一篇就够了!
1、冒泡排序
①. 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
②. 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
③. 针对所有的元素重复以上的步骤,除了最后一个。
④. 持续每次对越来越少的元素重复上面的步骤①~③,直到没有任何一对数字需要比较。
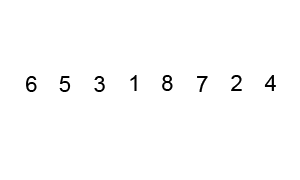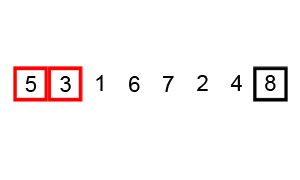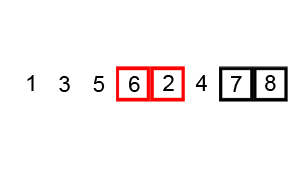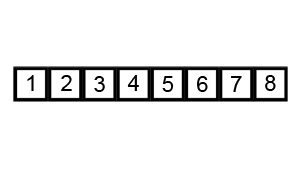
代码实现:
//1.冒泡排序
int[] originArray = new int[]{5,3,1,6,7,2,4,8};
for (int i = 0; i < originArray.length - 1;i++) {
for (int j = 0;j < originArray.length - i -1;j++) {
if(originArray[j] > originArray[j +1]){
int temp = originArray[j];
originArray[j] = originArray[j +1];
originArray[j +1] = temp;
}
}
}
System.out.println(Arrays.toString(originArray));
}
运行结果:
[1, 2, 3, 4, 5, 6, 7, 8]
2、插入排序
①. 从第一个元素开始,该元素可以认为已经被排序
②. 取出下一个元素,在已经排序的元素序列中从后向前扫描
③. 如果该元素(已排序)大于新元素,将该元素移到下一位置
④. 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
⑤. 将新元素插入到该位置后
⑥. 重复步骤②~⑤
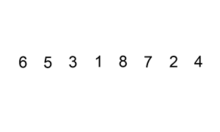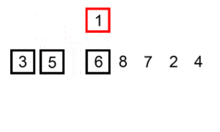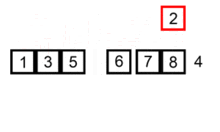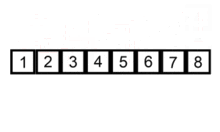
代码实现:
//2.插入排序
int[] originArray = new int[]{6,5,3,1,8,7,2,4};
for (int i =0; i< originArray.length - 1;i++) {
int insert = originArray[i + 1];
int j = i;
for (; j >= 0 && insert < originArray[j];j--) {
originArray[j + 1] = originArray[j];
}
originArray[j + 1] = insert;
}
System.out.println(Arrays.toString(originArray));
}
运行结果:
[1, 2, 3, 4, 5, 6, 7, 8]
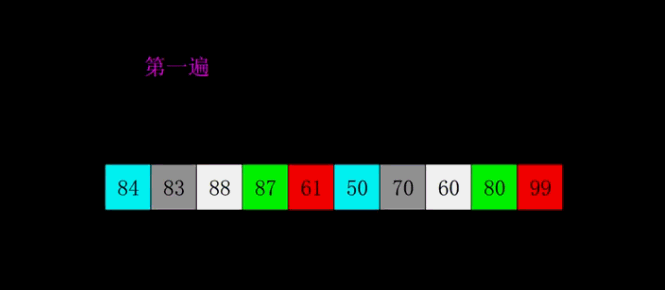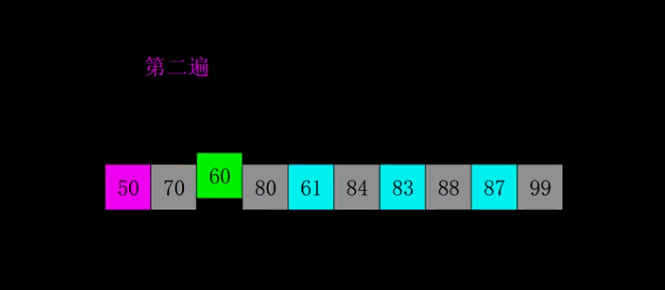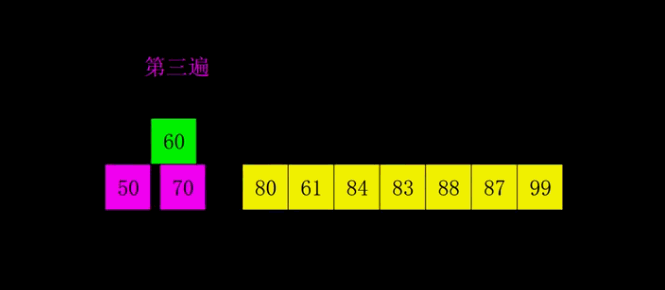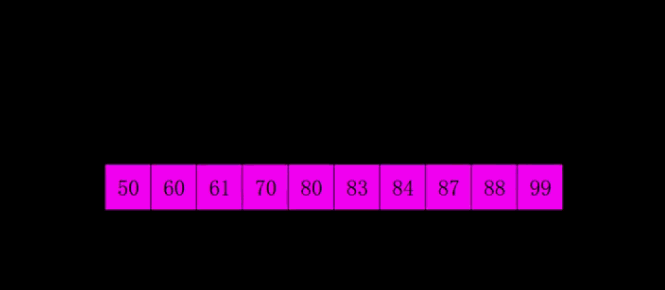
3、希尔排序
是插入排序的一种高速而稳定的改进版本。(第一个突破O(n^2)的排序算法;是简单插入排序的改进版;它与插入排序的不同之处在于,它会优先比较距离较远的元素)
①. 选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1;(一般初次取数组半长,之后每次再减半,直到增量为1)
②. 按增量序列个数k,对序列进行k 趟排序;
③. 每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
代码实现:
//3.希尔排序
int[] originArray = new int[]{84,83,88,87,61,50,70,60,80,99};
int gap = 1, i, j, len = originArray.length;
int temp;
while (gap < len / 2)
gap = gap * 2 + 1;
for (; gap > 0; gap /= 2) {
for (i = gap; i < len; i++) {
temp = originArray[i];
for (j = i - gap; j >= 0 && originArray[j] > temp; j -= gap)
originArray[j + gap] = originArray[j];
originArray[j + gap] = temp;
}
}
System.out.println(Arrays.toString(originArray));
}
运行结果:
[50, 60, 61, 70, 80, 83, 84, 87, 88, 99]
希尔排序重要之处在于步长gap的选择,已知的最好步长序列是由Sedgewick提出的(1, 5, 19, 41, 109,…)。这项研究也表明“比较在希尔排序中是最主要的操作,而不是交换。”
实现中是以默认的数组长度/2,只要最终gap为1(此时就是两两交换的插入排序,但大部分序列已经排好,可直接插入),均能实现排序,算法的时间、空间复杂度不同
4、选择排序
选择排序是一种简单直观的排序算法,在简单选择排序过程中,所需移动记录的次数比较少。
①. 从待排序序列中,找到关键字最小的元素;
②. 如果最小元素不是待排序序列的第一个元素,将其和第一个元素互换;
③. 从余下的 N - 1 个元素中,找出关键字最小的元素,重复①、②步,直到排序结束。
(红色表示当前最小值,黄色表示已排序序列,蓝色表示当前位置。)
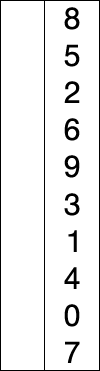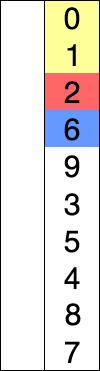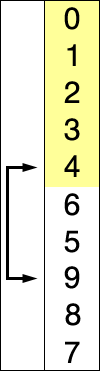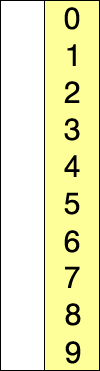
代码实现:
//4、选择排序
int[] originArray = new int[]{8,5,2,6,9,3,1,4,0,7};
for(int i = 0; i < originArray.length-1; i++){
int min = i;
for(int j = i+1; j < originArray.length; j++){ //选出之后待排序中值最小的位置
if(originArray[j] < originArray[min]){
min = j;
}
}
if(min != i){
int temp = originArray[min]; //交换操作
originArray[min] = originArray[i];
originArray[i] = temp;
}
}
System.out.println(Arrays.toString(originArray));
}
运行结果:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
5、快速排序
对冒泡排序的一种改进,使用分治策略来把一个序列(list)分为两个子序列(sub-lists)。步骤为:
①. 从数列中挑出一个元素,称为”基准”(pivot)。
②. 重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
③. 递归地(recursively)把小于基准值元素的子数列和大于基准值元素的子数列排序。
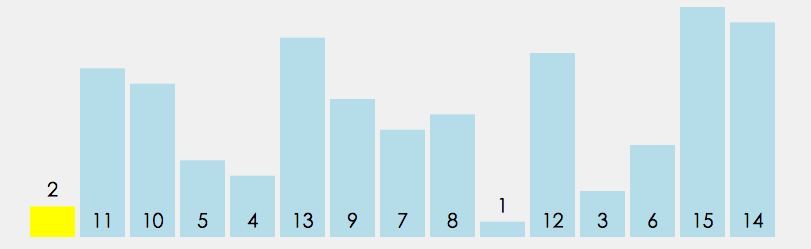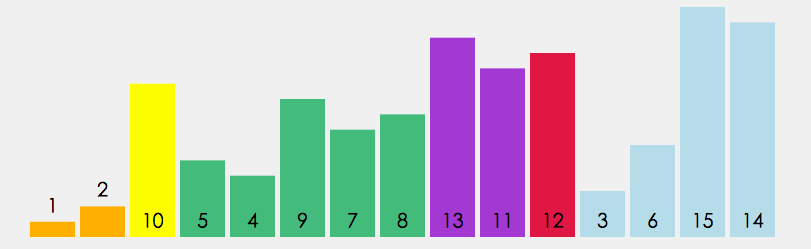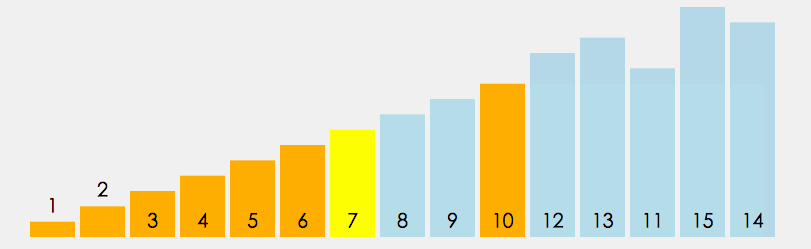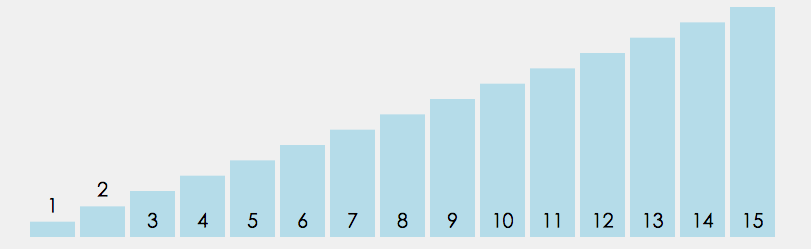
代码实现:
public static void quickSortByStack(int[] arr){
if(arr.length <= 0) return;
Stack<Integer> stack = new Stack<Integer>();
//初始状态的左右指针入栈
stack.push(0);
stack.push(arr.length - 1);
while(!stack.isEmpty()){
int high = stack.pop(); //出栈进行划分
int low = stack.pop();
int pivotIdx = partition(arr, low, high);
//保存中间变量
if(pivotIdx > low) {
stack.push(low);
stack.push(pivotIdx - 1);
}
if(pivotIdx < high && pivotIdx >= 0){
stack.push(pivotIdx + 1);
stack.push(high);
}
}
}
private static int partition(int[] arr, int low, int high){
if(arr.length <= 0) return -1;
if(low >= high) return -1;
int l = low;
int r = high;
int pivot = arr[l]; //挖坑1:保存基准的值
while(l < r){
while(l < r && arr[r] >= pivot){ //坑2:从后向前找到比基准小的元素,插入到基准位置坑1中
r--;
}
arr[l] = arr[r];
while(l < r && arr[l] <= pivot){ //坑3:从前往后找到比基准大的元素,放到刚才挖的坑2中
l++;
}
arr[r] = arr[l];
}
arr[l] = pivot; //基准值填补到坑3中,准备分治递归快排
return l;
}
public static void main(String[] args) {
int[] originArray = new int[]{2,11,10,5,4,13,9,7,8,1,12,3,6,15,14};
quickSortByStack(originArray);
System.out.println(Arrays.toString(originArray));
}
运行结果:
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]
6、归并排序
归并排序算法是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列。
一、自上而下递归法(假设序列共有n个元素):
①. 将序列每相邻两个数字进行归并操作,形成 floor(n/2)个序列,排序后每个序列包含两个元素;
②. 将上述序列再次归并,形成 floor(n/4)个序列,每个序列包含四个元素;
③. 重复步骤②,直到所有元素排序完毕。
二、迭代法
(暂未实现)
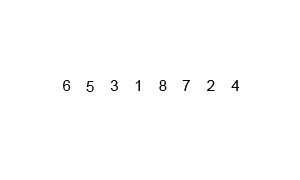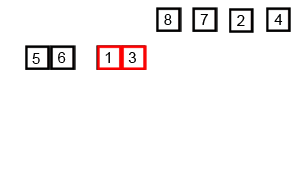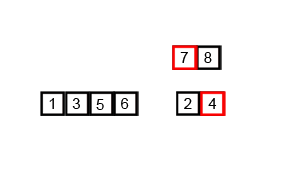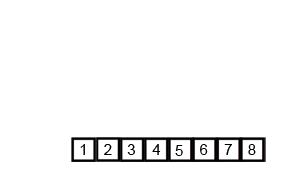
代码实现:
//5、归并排序
public static int[] mergingSort(int[] arr){
if(arr.length <= 1) return arr;
int num = arr.length >> 1;
int[] leftArr = Arrays.copyOfRange(arr, 0, num);
int[] rightArr = Arrays.copyOfRange(arr, num, arr.length);
return mergeTwoArray(mergingSort(leftArr), mergingSort(rightArr)); //不断拆分为最小单元,再排序合并
}
private static int[] mergeTwoArray(int[] arr1, int[] arr2){
int i = 0, j = 0, k = 0;
int[] result = new int[arr1.length + arr2.length]; //申请额外的空间存储合并之后的数组
while(i < arr1.length && j < arr2.length){ //选取两个序列中的较小值放入新数组
if(arr1[i] <= arr2[j]){
result[k++] = arr1[i++];
}else{
result[k++] = arr2[j++];
}
}
while(i < arr1.length){ //序列1中多余的元素移入新数组
result[k++] = arr1[i++];
}
while(j < arr2.length){ //序列2中多余的元素移入新数组
result[k++] = arr2[j++];
}
return result;
}
public static void main(String[] args) {
int[] originArray = new int[]{6,5,3,1,8,7,2,4};
System.out.println(Arrays.toString(mergingSort(originArray)));
}
运行结果:
[1, 2, 3, 4, 5, 6, 7, 8]
7、基数排序
将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列。
①. 取得数组中的最大数,并取得位数;
②. arr为原始数组,从最低位开始取每个位组成radix数组;
③. 对radix进行计数排序(利用计数排序适用于小范围数的特点);
代码实现:
int[] originArray = new int[]{3,44,38,5,47,15,36,26,27,2,46,4,19,50,48};
if(originArray.length <= 1) return;
//取得数组中的最大数,并取得位数
int max = 0;
for(int i = 0; i < originArray.length; i++){
if(max < originArray[i]){
max = originArray[i];
}
}
int maxDigit = 1;
while(max / 10 > 0){
maxDigit++;
max = max / 10;
}
//申请一个桶空间
int[][] buckets = new int[10][originArray.length];
int base = 10;
//从低位到高位,对每一位遍历,将所有元素分配到桶中
for(int i = 0; i < maxDigit; i++){
int[] bktLen = new int[10]; //存储各个桶中存储元素的数量
//分配:将所有元素分配到桶中
for(int j = 0; j < originArray.length; j++){
int whichBucket = (originArray[j] % base) / (base / 10);
buckets[whichBucket][bktLen[whichBucket]] = originArray[j];
bktLen[whichBucket]++;
}
//收集:将不同桶里数据挨个捞出来,为下一轮高位排序做准备,由于靠近桶底的元素排名靠前,因此从桶底先捞
int k = 0;
for(int b = 0; b < buckets.length; b++){
for(int p = 0; p < bktLen[b]; p++){
originArray[k++] = buckets[b][p];
}
}
base *= 10;
}
System.out.println(Arrays.toString(originArray));
}
运行结果:
[2, 3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50]
8、堆排序
堆的定义如下:n个元素的序列 {k1,k2,⋅⋅⋅,kn} 当且仅当满足下关系时,称之为堆。
{kiki⩽k2i⩽k2i+1或{kiki⩾k2i⩾k2i+1(i=1,2,⋅⋅⋅,⌊n2⌋)
把此序列对应的二维数组看成一个完全二叉树。那么堆的含义就是:完全二叉树中任何一个非叶子节点的值均不大于(或不小于)其左,右孩子节点的值。由上述性质可知大顶堆的堆顶的关键字肯定是所有关键字中最大的,小顶堆的堆顶的关键字是所有关键字中最小的。因此我们可使用大顶堆进行升序排序, 使用小顶堆进行降序排序。
①. 先将初始序列K[1…n]建成一个大顶堆, 那么此时第一个元素K1最大, 此堆为初始的无序区.
②. 再将关键字最大的记录K1 (即堆顶, 第一个元素)和无序区的最后一个记录 Kn 交换, 由此得到新的无序区K[1…n−1]和有序区K[n], 且满足K[1…n−1].keys⩽K[n].key
③. 交换K1 和 Kn 后, 堆顶可能违反堆性质, 因此需将K[1…n−1]调整为堆. 然后重复步骤②, 直到无序区只有一个元素时停止.

代码实现:
public static void heapSort(int[] arr){
for(int i = arr.length; i > 0; i--){
max_heapify(arr, i);
int temp = arr[0]; //堆顶元素(第一个元素)与Kn交换
arr[0] = arr[i-1];
arr[i-1] = temp;
}
}
private static void max_heapify(int[] arr, int limit){
if(arr.length <= 0 || arr.length < limit) return;
int parentIdx = limit / 2;
for(; parentIdx >= 0; parentIdx--){
if(parentIdx * 2 >= limit){
continue;
}
int left = parentIdx * 2; //左子节点位置
int right = (left + 1) >= limit ? left : (left + 1); //右子节点位置,如果没有右节点,默认为左节点位置
int maxChildId = arr[left] >= arr[right] ? left : right;
if(arr[maxChildId] > arr[parentIdx]){ //交换父节点与左右子节点中的最大值
int temp = arr[parentIdx];
arr[parentIdx] = arr[maxChildId];
arr[maxChildId] = temp;
}
}
}
public static void main(String[] args) {
int[] originArray = new int[]{91,60,96,13,35,65,46,65,10,30,20,31,77,81,22};
heapSort(originArray);
System.out.println(Arrays.toString(originArray));
}
运行结果:
[10, 13, 20, 22, 30, 31, 35, 46, 60, 65, 65, 77, 81, 91, 96]
