一.简介
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
我们建立一个网站或应用程序,并要添加搜索功能,但是想要完成搜索工作的创建是非常困难的。我们希望搜索解决方案要运行速度快,我们希望能有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON通过HTTP来索引数据,我们希望我们的搜索服务器始终可用,我们希望能够从一台开始并扩展到数百台,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。因此我们利用Elasticsearch来解决所有这些问题及可能出现的更多其它问题。
本篇博文环境为:Jdk1.8 Centos7 ElasticSearch5.4
二.单机版安装
对于在一台机器上安装,可分为以下步骤。
1.安装JDK(1.8)
从本地上传jdk的安装包到 /opt目录下进行解压
tar -zxvf jdk安装包名称 -C 解压到那个目录,默认是当前目录配置环境变量
vim /etc/profile
添加如下内容:JAVA_HOME根据实际目录来
JAVA_HOME=/opt/jdk1.8.0_60
PATH=/opt/jdk1.8.0_60/bin:$PATH
export PATH JAVA_HOME 安装完成后可进行 java 和 javac 命令验证是否安装成功,或编写java文件进行编译。
2.上传解压Elasticsearch-5.4.3
先创建 /bigdata /data 分别用来存放es的解压文件 和 数据文件
解压es
tar -zxvf elasticsearch-5.4.3.tar.gz -C /bigdata/
3.创建一个普通用户,然后将对于的目录修改为普通用户的所属用户和所属组
es的运行需要非root用户:
创建用户: useradd zj
创建用户密码: passwd zj
给创建的文件夹赋予zj权限: chown -R zj:zj /{bigdata,data}
若再出现权限的问题 ,再给bigdata下的es文件夹赋给zj权限(博主就遇到了这个问题,这样就可以解决)
4.修改配置文件/bigdata/es/config/elasticsearch.yml
vi /bigdata/elasticsearch-5.4.3/config/elasticsearch.yml找到 network.host: 192.168.195.130
将ip改成本机的ip ,特别要注意的是要讲前边的注释给去掉,不能忘记了。我就吃了这个亏
5.启动ES,发现报错
/bigdata/es/bin/elasticsearch
#出现错误
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决办法:
#用户最大可创建文件数太小
sudo vi /etc/security/limits.conf
添加
* soft nofile 65536
* hard nofile 65536
#查看可打开文件数量
ulimit -Hn #最大虚拟内存太小
sudo vi /etc/sysctl.conf
vm.max_map_count=262144
#查看虚拟内存的大小
sudo sysctl -p6重启linux
shutdown -r now
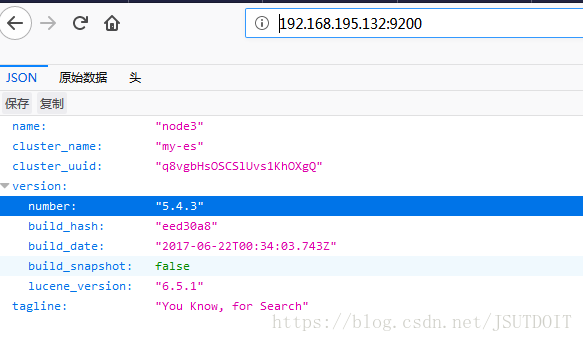
7.通过浏览器访问ES
http://192.168.195.132:9200/若出现无法访问,多半是防火墙的问题,解决办法:
service firewalld stop成功访问的结果:
三.es集群搭建
es的使用非常简单,单机版搞定集群就能很快搞定,与hadoop和sparkb不同的是,不需要zokeeper.
准备工作:
1.首先使用虚拟机进行克隆3台虚拟机
2.将上台虚拟机打开后,进行主机名的修改
查看主机名的命令:
hostname修改主机名
hostnamectl set-hostname 主机名 (es1,es2,es3)3.进行ip地址的修改
vi /etc/sysconfig/network-scripts/ifcfg-enthXXXDEVICE=eth0 #描述网卡对应的设备别名
BOOTPROTO=static #设置网卡获得ip地址的方式,选项可以为为static,dhcp或bootp
BROADCAST=192.168.1.255 #对应的子网广播地址
HWADDR=00:07:E9:05:E8:B4 #对应的网卡物理地址
IPADDR=12.168.1.80 #只有网卡设置成static时,才需要此字段
NETMASK=255.255.255.0 #网卡对应的网络掩码
NETWORK=192.168.1.0 #网卡对应的网络地址,也就是所属的网段
ONBOOT=yes #系统启动时是否设置此网络接口,设置为yes时,系统启动时激活此设备需要将BOOTPROTO改成static
然后添加IPADDR=“IP地址”
然后使用命令进行重启网卡:
service network restart4.ip主机名地址映射的修改
vi /etc/hosts
添加其余两台的ip地址对应关系
192.168.95.130 es1
192.168.95.131 es2
192.168.95.132 es35.进行配置文件的修改
vi /bigdata/elasticsearch-5.4.3/config/elasticsearch.yml
打开配置文件可见,要修改的部分如下:
(1)集群名称
#集群名称,通过组播的方式通信,通过名称判断属于哪个集群
cluster.name: my-es
(2)节点名称
#节点名称,要唯一
node.name: es1
(3)数据和日志存放的位置
#数据存放位置
path.data: /data/es/data
#日志存放位置(可选)
path.logs: /data/es/logs
(4)ip地址的绑定
#es绑定的ip地址
network.host: 192.168.10.16
(5)初始化选举点(***)
可修改ip或主机名的选项
#初始化时可进行选举的节点
discovery.zen.ping.unicast.hosts: ["es1", "es2", "es3"]7.使用scp拷贝到其他节点
进入es的config目录
scp elasticsearch-yml 目标主机的ip地址:$PWD
若出现错误,多半是ssh的相关配置没有设置好,可参考我的另一篇博客:ssh的配置
之后便可以进行配置文件的传送无秘钥进行
8.在其他节点上修改es配置,需要修改的有node.name和network.host
9.启动es(/bigdata/elasticsearch-5.4.3/bin/elasticsearch -h查看帮助文档)
/bigdata/elasticsearch-5.4.3/bin/elasticsearch -d (后台运行启动)
可使用jps命令查看当前Java相关的进程。
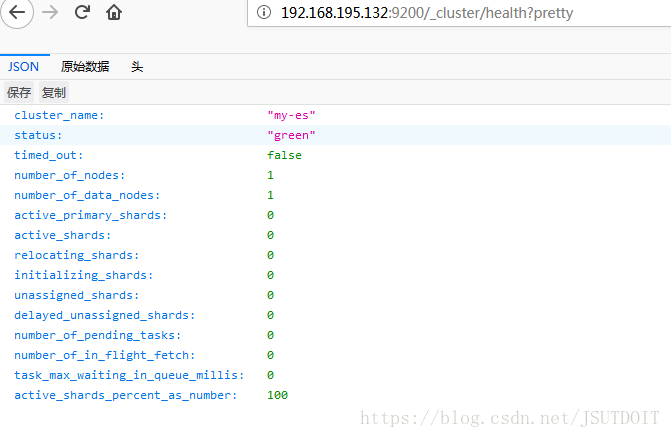
查看集群的状态:
curl -XGET 'http://192.168.10.16:9200/_cluster/health?pretty'(命令行)
http://192.168.10.16:9200/_cluster/health?pretty(浏览器)