文章目录
1.概述
2.7.9版本的Dubbo官方提供的负载均衡算法有5种,在2.6.*里面只有4种负载均衡算法。本文将详细的介绍这5种算法的底层实现。
2.随机+权重(random)
算法步骤
- 计算服务提供者的总权重,并维护一个前缀和数组。
- 基于第一步的结果,在0~总权重之间生成一个随机数。
- 随机数得到的一个权重,遍历前缀和数组,找到第一个比随机权重大的位置,即可确定选择的服务提供者。
- 如果所有服务提供者节点都没有分配权重,或者分配的权重都一样,那么就采用随机的选择一个服务提供者节点。
例子
三个服务提供者的权重分别是10,20,50
- 根据算法步骤1计算总权重的结果是10+20+50 = 80,前缀和数组为[10,30,80]
- 根据算法步骤2在0~80之间生成随机数,假设随机数为60
- 根据算法步骤3 遍历前缀和数组,找到第一个比60大的位置,也就是80,所以确定了第三个服务提供者用于处理请求。
Dubbo算法实现
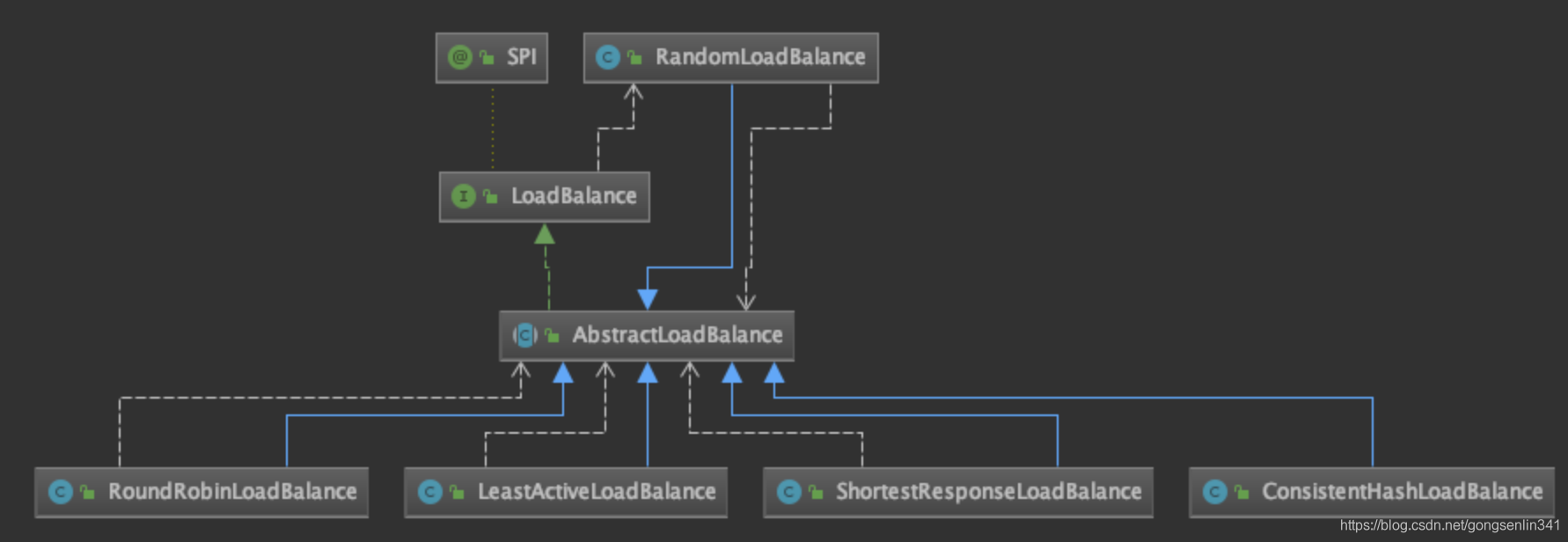
RandomLoadBalance中的doSelect方法
- totalWeight 用于计算总权重,weights用于记录权重前缀和,sameWeight标志位,用于判断是否所有节点都相同。
- 第一个for循环,用于计算总权重和记录权重前缀和。同时判断是否所有的节点权重都相同。
- 如果总权重大于0,并且至少有一个节点分配的权重和别的不一样。那么在0~totalWeight之间生成一个随机数,然后遍历前缀和数组,找到第一个比随机数大的位置,返回其对应的服务提供者用于处理当前请求。
- 如果所有的节点都没有分配权重,或者分配了权重但是全部都相等,那么就随机选择一个服务提供者。
3.轮询+权重(roundrobin)
算法步骤
- 计算服务提供者的总权重。
- 每个服务提供者除了始终不变的固定权重以外,需要记录服务提供者当前权重。
- 每次请求,更新所有的服务提供者的当前权重,当前权重 = 当前权重 + 固定权重。
- 从上一步得到的结果中,选择一个当前权重最大的服务提供者用于处理请求,如果存在多个,那么就看遍历的过程中先遇到哪个服务提供者就是哪一个。并且,选中的权重最大的服务提供者更新其当前权重 = 当前权重 - 总权重
例子
三个服务提供者的固定权重分别是10,20,50,假设其当前权重依次为0,0,0
- 计算总权重 10+20+50 = 80
- 当请求来了,更新三个服务提供者的当前权重,当前权重 = 当前权重+固定权重,依次结果为10,20,50.
- 从中选择最大的一个,也就是第三个用于处理请求,同时将其当前权重更新:当前权重 = 50 - 80 = -30
- 所以此时三个服务提供者的当前权重依次为10,20,-30
- 当第二个请求来的时候,更新三个服务提供者的当前权重,当前权重 = 当前权重+固定权重,依次结果为20,40,20
- 从重选择最大的一个,也就是第二个用于处理请求,同时将其当前权重更新:当前权重 = 40 - 80 = -40.
- 依次类推。
Dubbo算法实现
先来看一下WeightedRoundRobin对象,一个服务提供者节点,对应一个WeightedRoundRobin对象,该对象记录了服务提供者的权重,当前的权重以及上一次权重更新的时间。

RoundRobinLoadBalance中的doSelect方法如下:

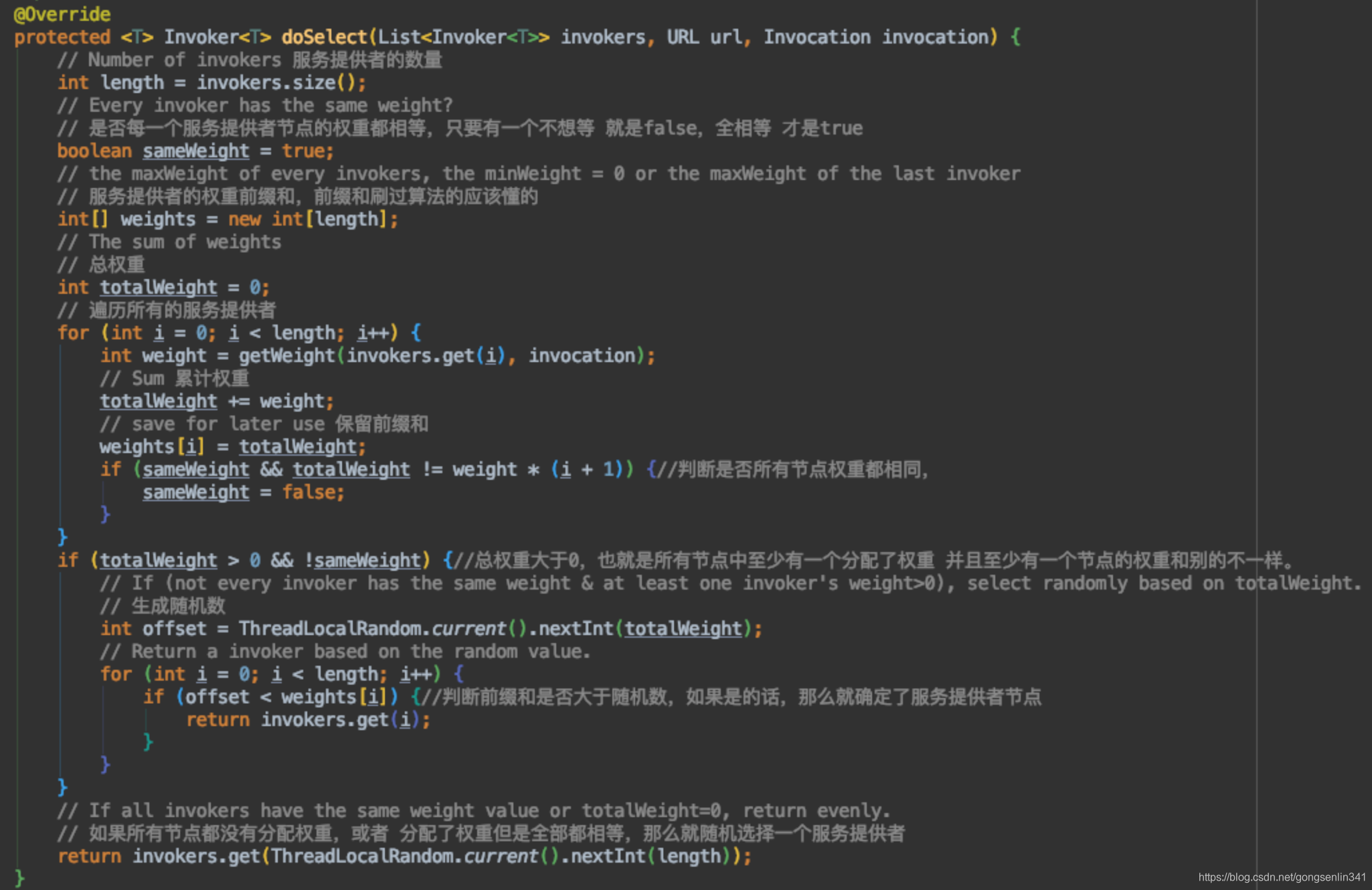
- methodWeightMap 方法权重Map用于保存服务方法提供者集群的WeightedRoundRobin对象集合。一个服务方法提供者对应一个WeightedRoundRobin。key是服务提供者的身份信息,value是WeightedRoundRobin对象。
- 遍历所有的服务提供者,
- 根据它的身份信息以及服务提供者的权重。
- 基于身份信息得到WeightedRoundRobin对象,如果没有的话new一个。
- 若缓存中的WeightedRoundRobin的权重 不等于刚得到的weight,那么就更新WeightedRoundRobin中的weight。
- WeightedRoundRobin中的当前权重自增,当前权重 = 当前权重 + 固定权重,并设置更新的时间。
- 记录当前权重最大的节点的信息。
- 统计总权重
- 若服务提供者列表和map的大小不一致,说明有服务提供者挂了,那么根据WeightedRoundRobin中的lastUpdate字段,判断是否存活,移除挂了的服务提供者。
- 对找到的最大的当前权重的服务提供者进行更新当前权重,它的当前权重 = 当前权重 - 总权重。
- 返回最大的服务提供者节点。
4.最少连接(leastactive)
算法步骤
- 客户端存在一个计数器,记录当前通过某个服务提供者的请求还未完成的总数。
- 选择计数最少的那一个用于处理当前请求,并将计数器+1
- 如果存在多个相同的计数,那么使用随机+权重的方式进行(前提是服务器提供者要分配权重,且权重不相同)
- 否则从多个最少的服务提供者当中随机的选择一个处理当前请求。
例子
该算法比较简单,就不举例子了。直接看代码
Dubbo算法实现
LeastActiveLoadBalance的doSelect方法
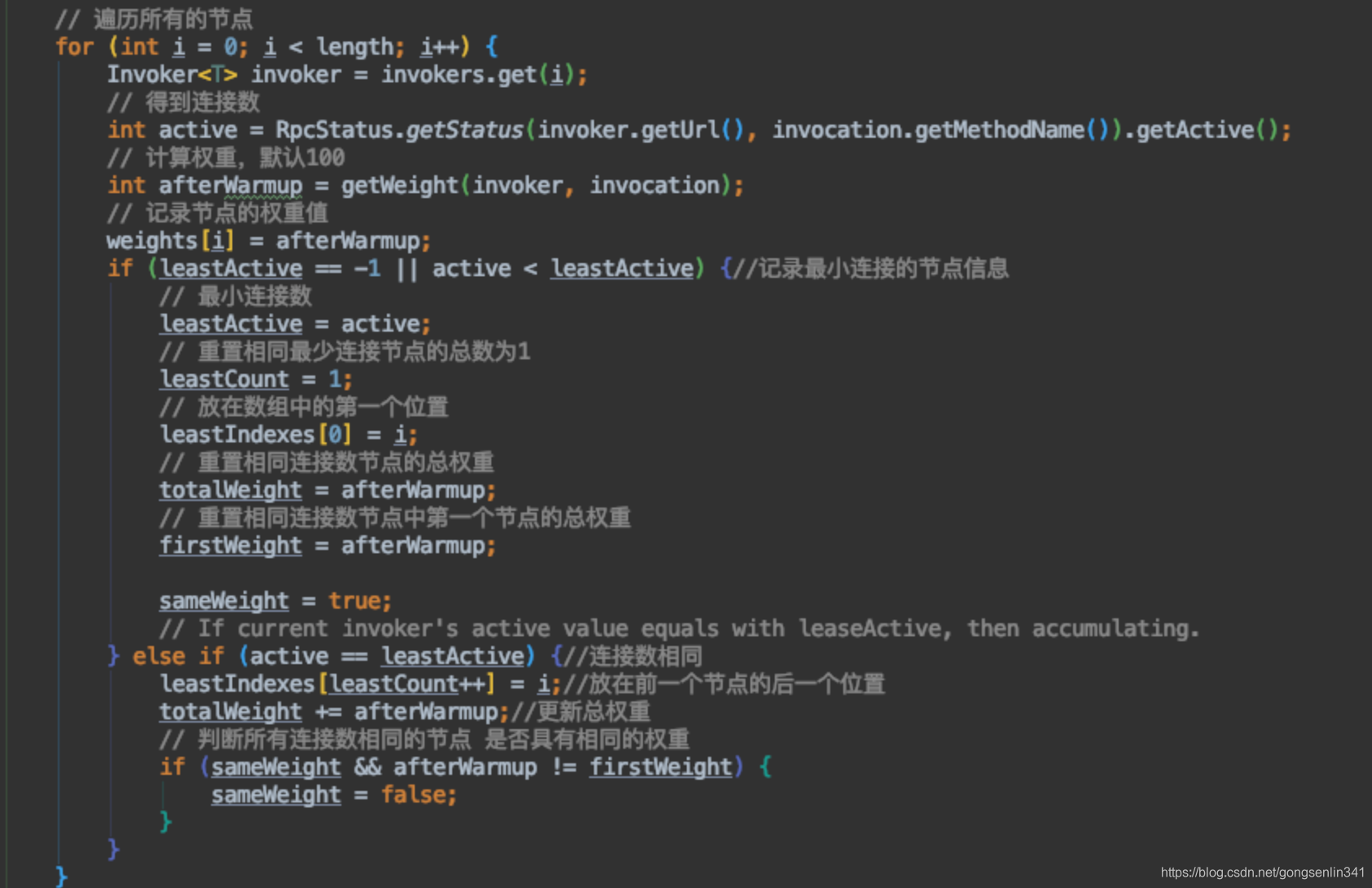

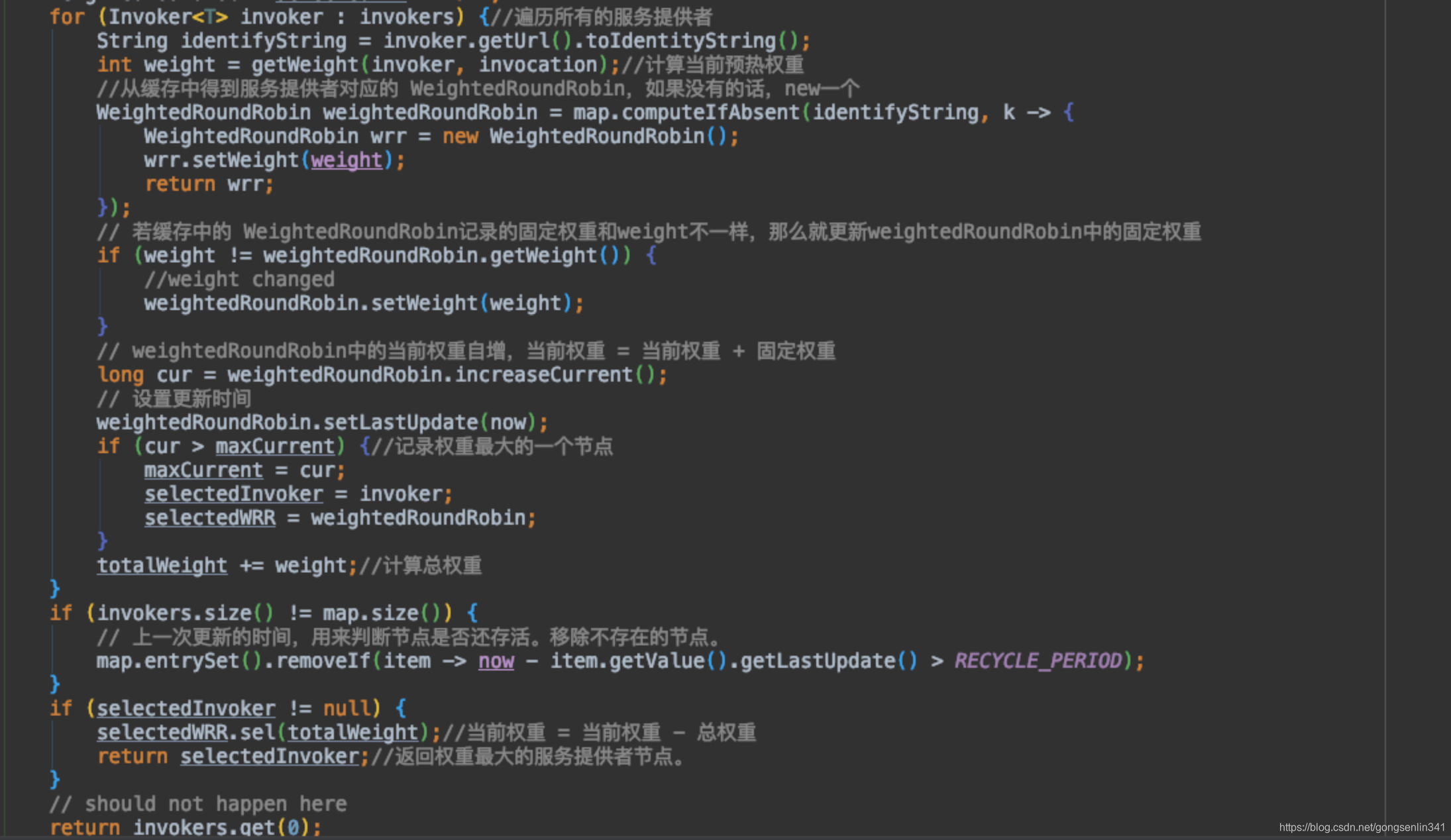
- 遍历所有的服务提供者节点,找到最少的连接数的节点。
- 如果只有一个直接返回。
- 如果有多个,若所有连接数量相同的节点的权重相同或都为0,那么就从中随机返回一个。
- 否则就从0~totalWeight-1中生成一个随机数,然后遍历相同连接数的节点,更新随机数,确认返回的服务提供者。
5.最短响应(shortestresponse)
该算法是在上一个算法的基础上的改进,根据服务提供者的实际的表现来更加合理的分配请求。
算法步骤
- 除了存在计数器以外,还需要统计历次请求处理成功的平均时间。注意是成功的处理不包括失败的。
- 每个服务提供者都可以根据 计数器 * 历次请求处理成功的平均时间 得到一个结果。
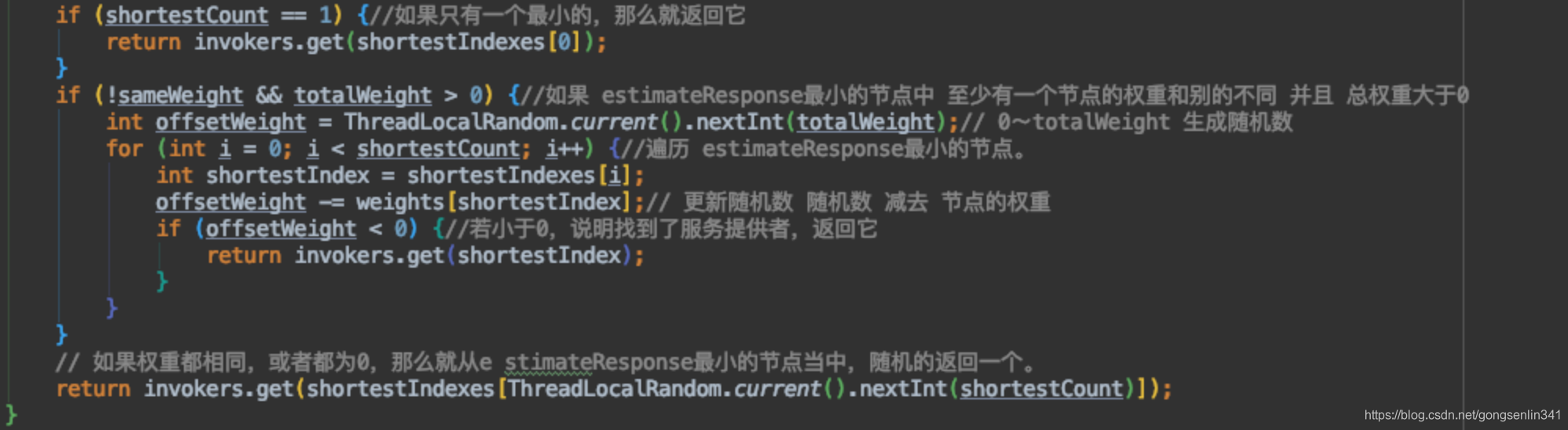
- 从中选择一个最小值对应的服务提供者用于处理当前请求。
- 若存在多个结果相同的最小值,那么采取的策略和上面一种的策略一样,能使用随机+权重就使用,不行就随机。
直接看代码
Dubbo算法实现
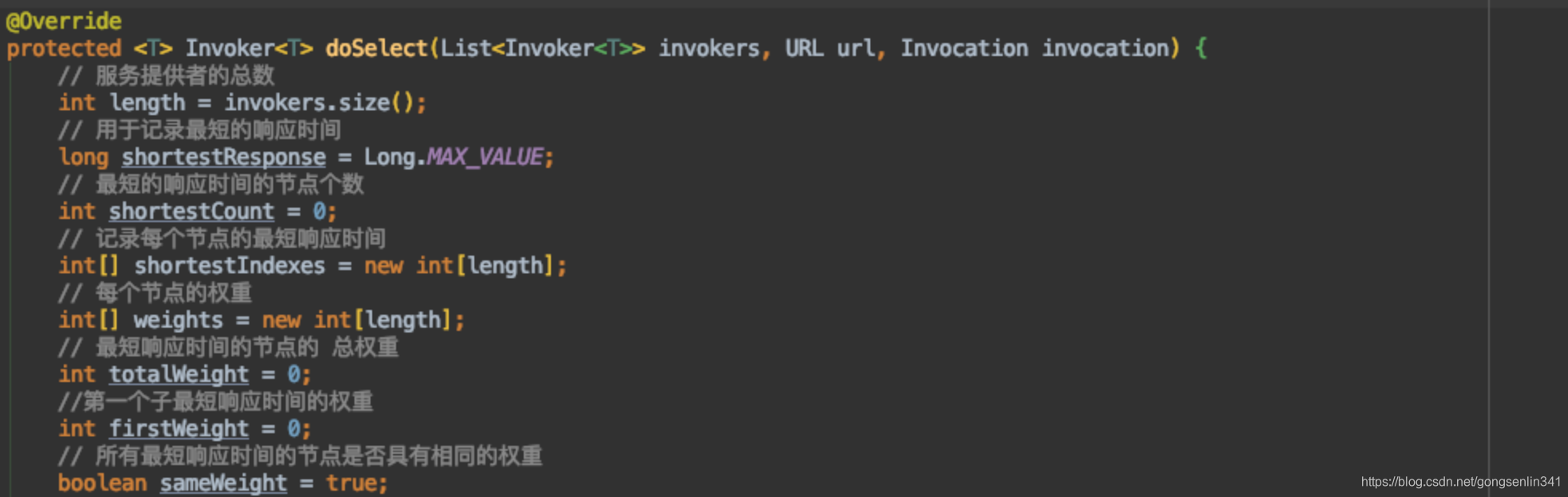
ShortestResponseLoadBalance中的doSelect方法
-
每个服务提供者节点都关联了一个RpcStatus对象,该对象记录的信息如下:
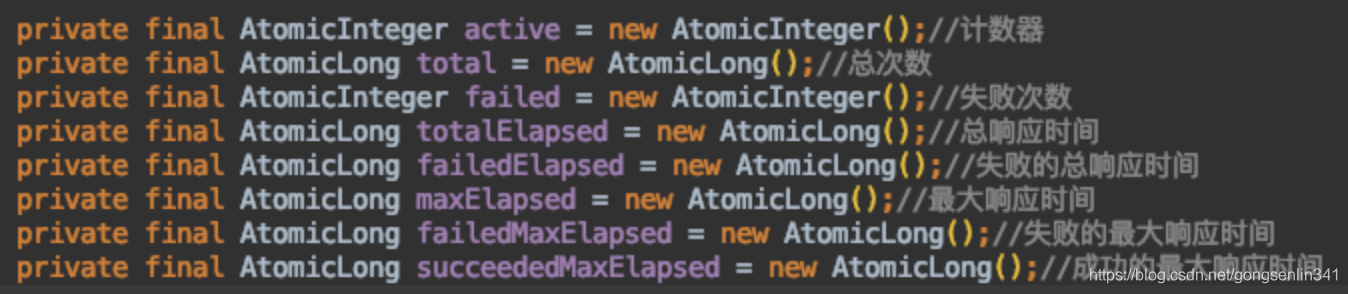
-
shortestIndexes用于记录 最短响应时间的节点,可能存在相同的,所以是一个数组。
-
weights用于记录 最短响应时间的节点的权重
-
totalWeight 用于记录 最短响应时间的节点的权重总和
-
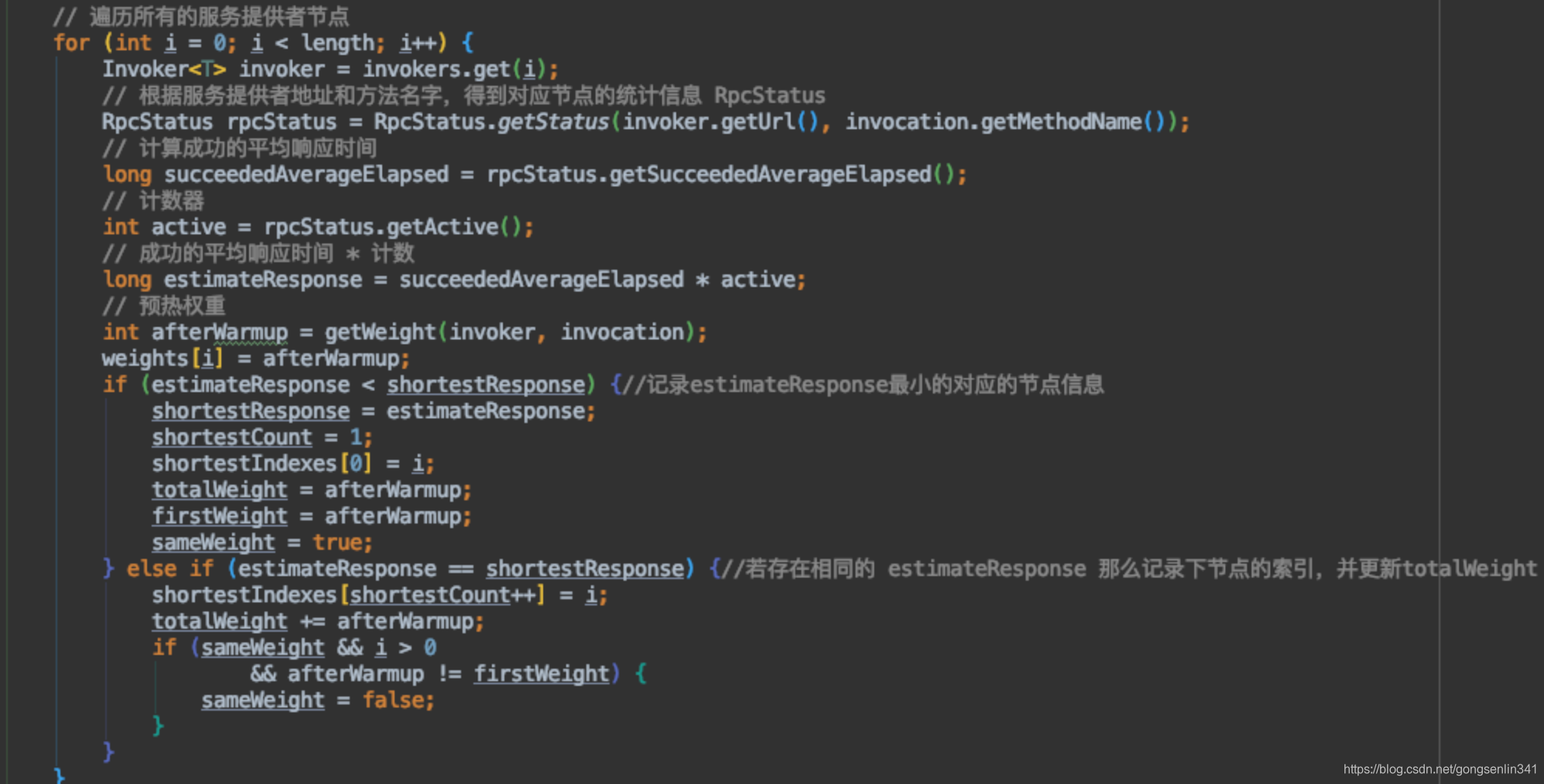
遍历所有的服务提供者节点,得到器对应的统计信息。
-
根据 成功响应的平均时间 * 计数 得到estimateResponse
-
过程和上面的类似,只是基于比较的值不同而已。不再赘述
6.一致性哈希(consistenthash)
算法步骤
- 对服务提供者的地址,分段式递增hash,hash值是32位的。
- 也就是将服务提供者均匀的分布在一个环上,环的最大值为2的32次方-1
- 一个服务提供者最多会有默认的160个分身,可以根据参数hash.nodes来调配,注意这要配置在DubboService。
- 当请求来了,根据请求的方法参数,计算hash值,找到第一个环中比它大的hash值对应的服务提供者用于处理请求。
- 用于计算hash值的方法参数可以通过hash.arguments来配置,同样也是配置在DubboService,例如“0,1"表示使用第1个和第二个参数计算hash。默认是使用第一个参数来计算。
例子
例如现在服务提供者有两个,它们的地址是不一样的,假设现在hash.nodes和hash.arguments均适用默认的参数。
一个服务器提供者通过分段式递增hash可以计算出160个点,分布在0~2的32次方-1之间。这样两个服务器最多可以有320个点,较均匀的交叉分布在整个所谓的环上。较均匀是因为并不是ABABAB这样,可能是AABABBAABBABAB…
这样就算初始化好了服务提供者在环上的位置。
当请求来的时候,根据第一个参数计算出hash值,然后从环上找到第一个比他大的hash值,得到对应的服务器提供者的地址进行请求的处理。
Dubbo算法实现
算法分为两部分,
第一部分是初始化服务提供者的分身节点。也就是初始化我们所谓的环,将服务提供者节点均匀的分布在环上
第二部分是请求来的时候,是如何选择服务提供者节点的逻辑。
先来看第一部分
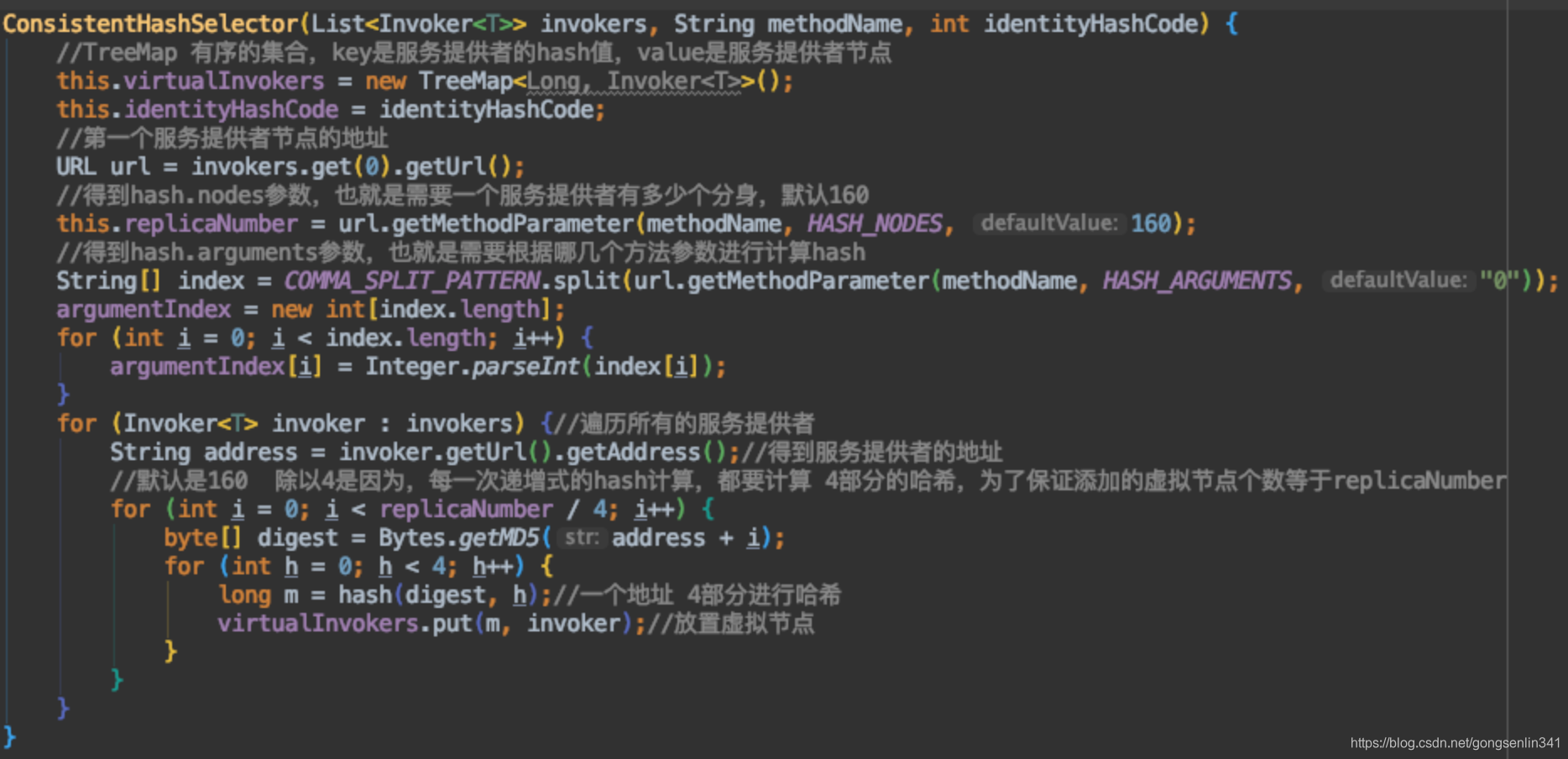
- 构造一个TreeMap,有序集合用于存储服务提供者节点
- 得到服务提供者节点的分身数量以及之后方法请求的时候用于计算hash值的参数的索引。
- 遍历所有的服务提供者,根据分身数量,进行分段式递增hash。这个分段式递增hash是我自己起的名字,根据原来的地址加上一个新的值i,而这个i是递增的,所以叫他递增式。里面的4次的for循环,将digest分成了4段,分别的计算hash值,所以叫他分段式。hash方法的代码如下,结果是只保留了低32位。所以服务提供者节点分布在0~2的32次方-1上。
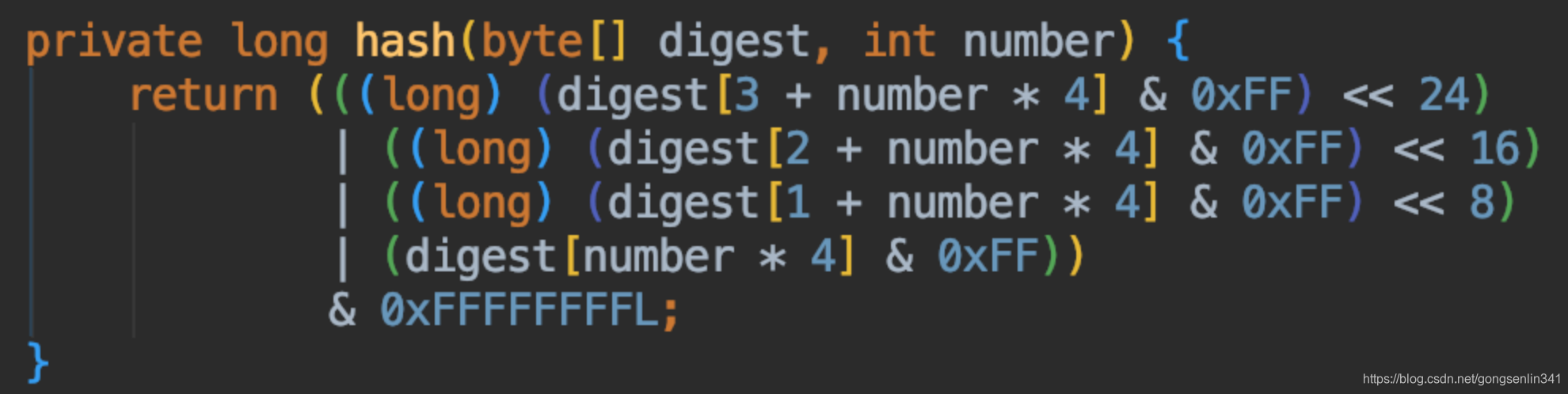
- 至此服务提供者分布的位置都已经初始化完毕。
假设提供了2个服务提供者,debug的结果如下:
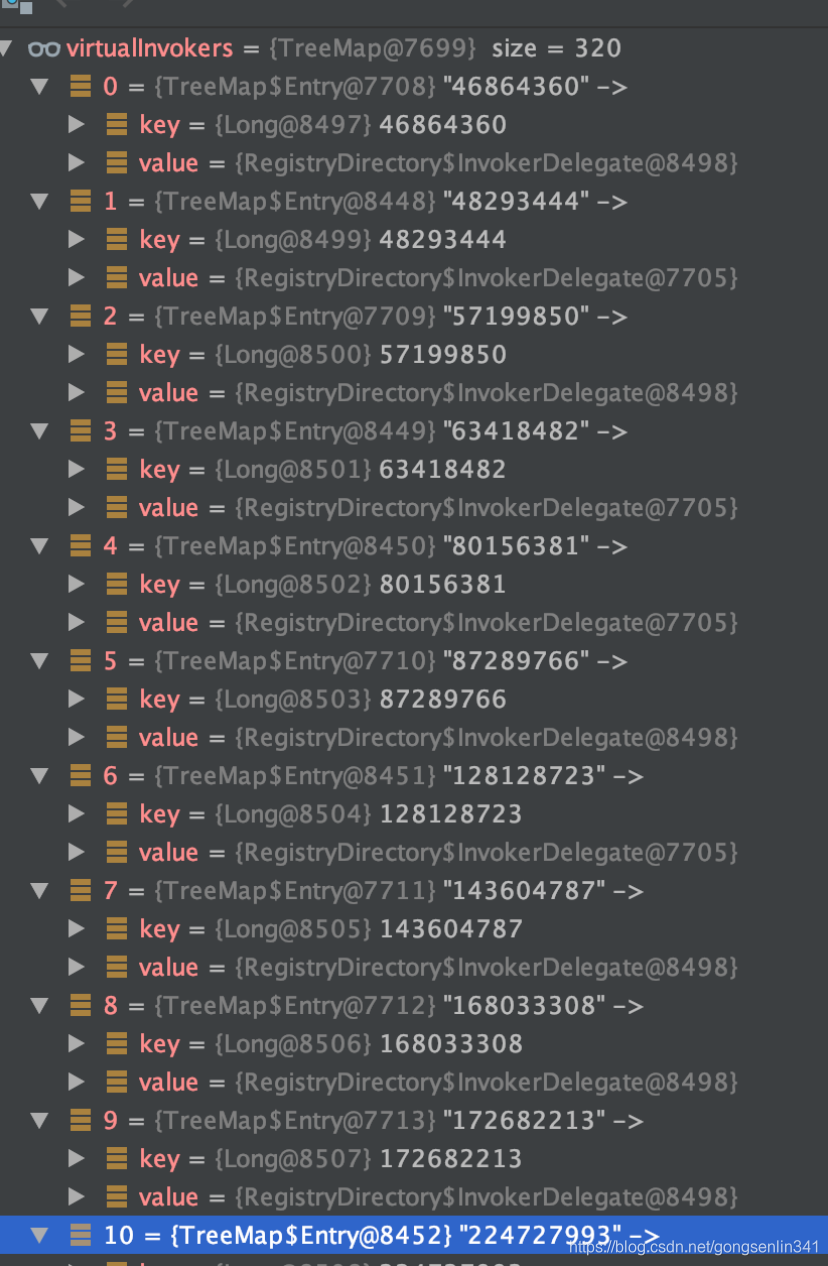
可以看到这里有两个服务提供者,一共有320个分身,分布较为均匀。
第二部分,判断请求的服务提供者节点
调用ConsistentHashLoadBalance当中的doSelect方法
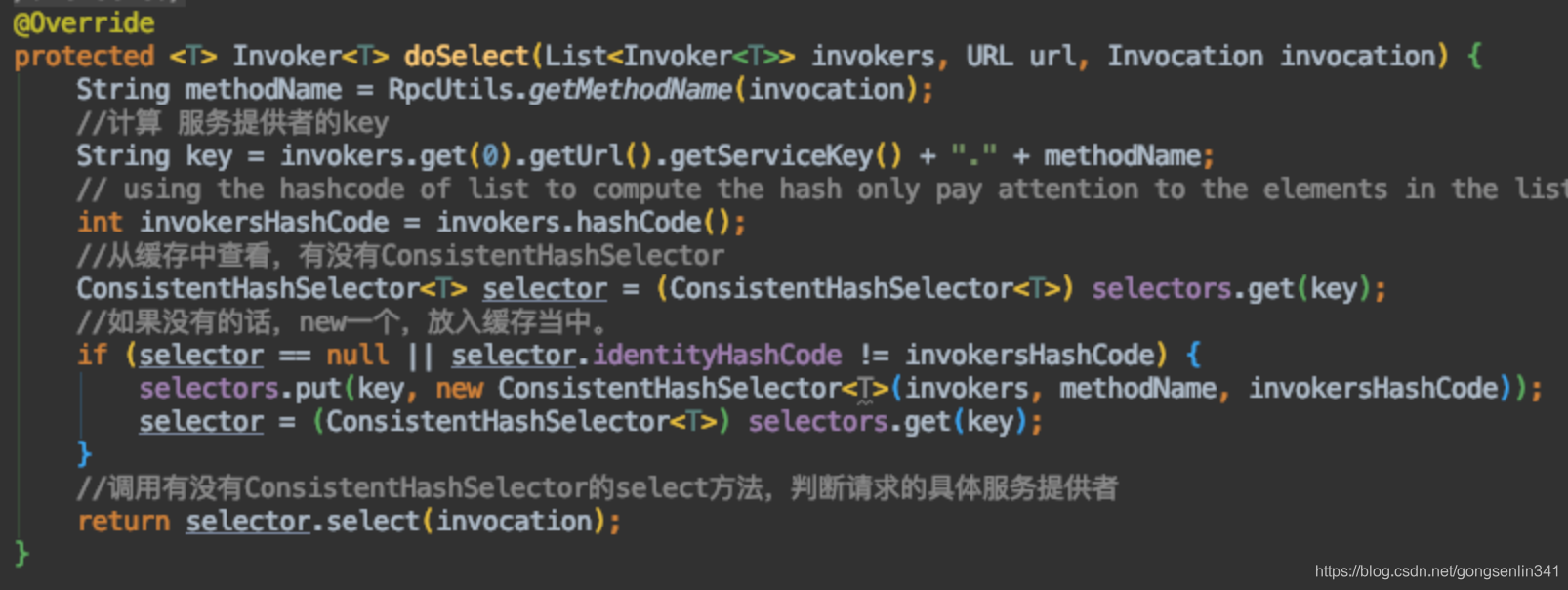
此处先确认要访问的服务提供者集群是哪个,具体的服务提供者节点,要看ConsistentHashSelector的select方法的执行结果。
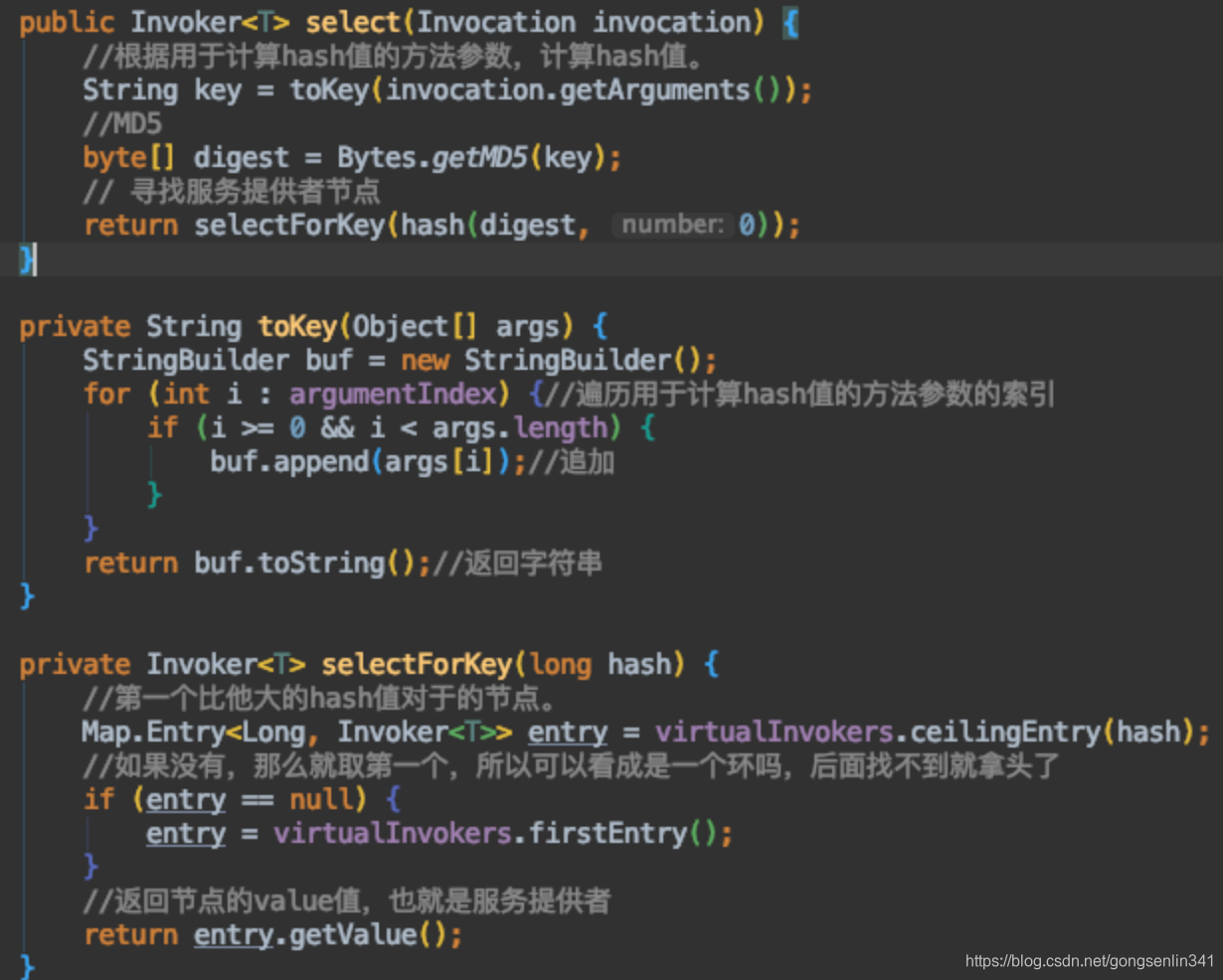
这里的逻辑还是比较简单的,就是根据给定的方法参数,计算hash值,然后从treeMap当中找到第一个比他大的节点,如果没有,那么就返回treeMap当中的第一个节点。返回节点的value值也就是服务提供者。