一.简介
BloomFilter底层是一个位图(位数组)的数据结构,通过k个hash函数将这个元素映射到位数组的k个点,将他们设置为1。检索时,我们查看这k个点是否都为1就能够判断元素是否在BloomFilter中(会有一定的误差率);如果k个点有一个点不为1,那么这个元素肯定不在BloomFilter里面。大致的数据结构:

二.使用场景
1.海量数据的去重
2.处理缓存穿透的场景,用于校验请求的key是否存在
三.使用demo
guava的BloomFilter包
package com.vip.learn.guava;
import com.google.common.hash.BloomFilter;
import java.nio.charset.Charset;
/**
* Created by andrew.huang on 2019/6/3
*/
public class BloomFilterMain {
public static void main(String[] args) {
BloomFilter<String> bloomFilter = BloomFilter.create((from, into) -> {
into.putString(from, Charset.defaultCharset());
}, 32 * 1024 * 1024L, 0.01d);
for(int i = 0;i < 10;i++){
bloomFilter.put(Thread.currentThread().getName() + i);
}
System.out.println(bloomFilter.mightContain("1"));
System.out.println(bloomFilter.mightContain(Thread.currentThread().getName() + "1"));
}
}
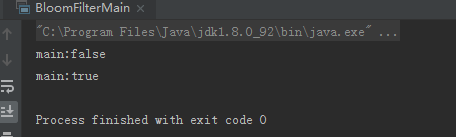
输出结果:
四.guava bloomFilter原理
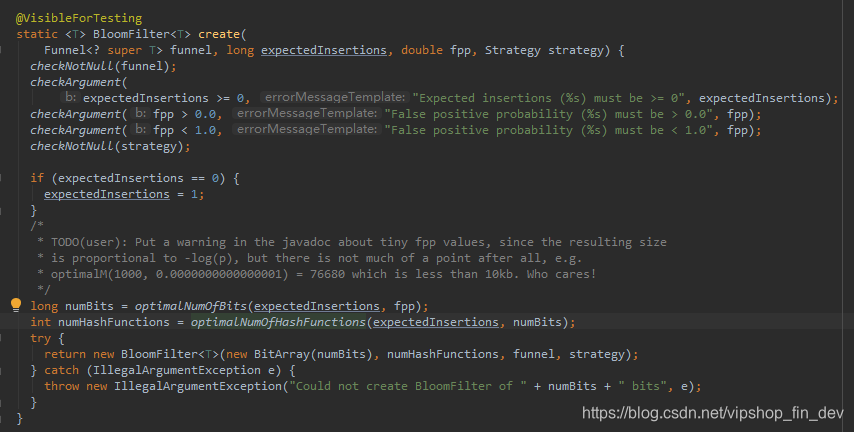
1.BloomFilter.create()
(1)先看看官方api文档对create四个方法的解释
主要的三个参数:
*funnel:你要怎么插数据到bloomFilter
*expectedInsertions:期待bloomfilter里面包含的元素个数
*fpp(false positive probability):错误容忍率

(2)探索下底层bloomfilter根据这几个参数是怎么处理的
可以看到BloomFilter这里使用了一个BloomFilterStrategies.MURMUR128_MITZ_64的策略类
里面的获取numBits和numHashFunctions都是依据数学理论计算出来,有兴趣可以了解https://blog.csdn.net/v_JULY_v/article/details/6685894

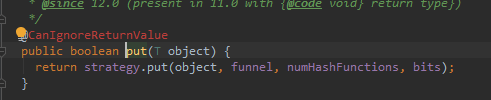
2.BloomFilter.put()方法
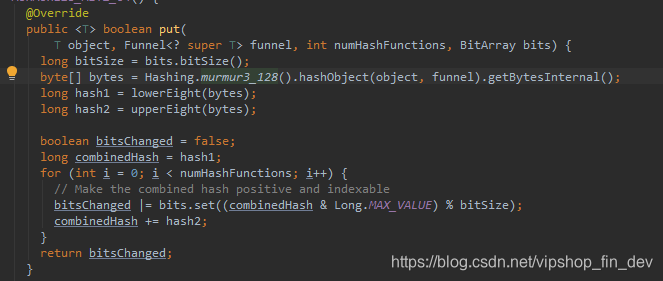
可以看到BloomFilter实际上是通过strategy类去实现,真正的put方法是
点进去可以看到,这个类主要是通过一个murmur3_128的hash函数去获取hash,根据hash函数的个数,去执行k次hash算法将值put进去
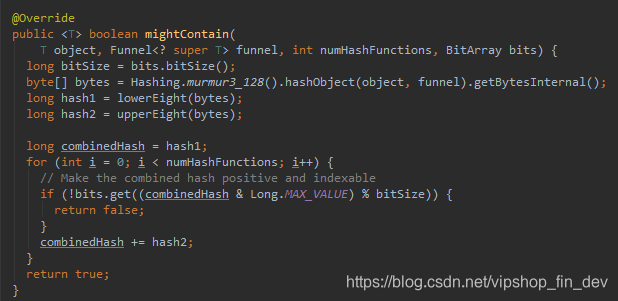
3.BloomFilter.mightContains()方法
可以看到通过k个hash算法,只要有一个BitArray.get()得到的返回值不为true(也就是在那个元素位置上不为1),那么就会返回false
4.guava BloomFilter的缺点
不能删除元素,必须在预估好容量之后再去设置BloomFilter
五.总结
BloomFilter的实现关键在于位数组容量的大小,容错率的数值和hash函数的选择,在可以容忍一定概率的错误率情况下,能够高效的处理海量数据的去重和判重。
from:andrew.huang
