直接上代码
import os
from pybloom_live import BloomFilter
from scrapy.exceptions import DropItem
class BloomCheckPipeline(object):
def __int__(self):
file_name = 'bloomfilter'
def open_spider(self, spider):
file_name = 'bloomfilter'
is_exist = os.path.exists(file_name + '.blm')
if is_exist:
self.bf = BloomFilter.fromfile(open('bloomfilter.blm', 'rb'))
print('open blm file success')
else:
self.bf = BloomFilter(100000, 0.001)
print('didn\'t find the blm file')
def process_item(self, item, spider):
#我是过滤掉相同url的item 各位看需求
if item['url'] in self.bf:
print('drop one item for exist')
raise DropItem('drop an item for exist')
else:
self.bf.add(item['url'])
print('add one success')
return item
def close_spider(self, spider):
self.bf.tofile(open('bloomfilter.blm', 'wb'))
这已经是二次爬取了 多次爬取防止有遗漏的
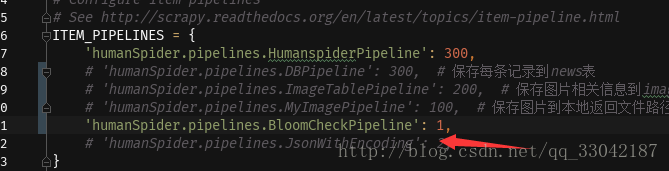
对了不要忘记 在setting里面添加这个pipeline