1. 题目来源
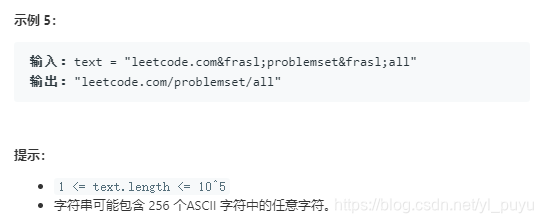
2. 题目说明

3. 题目解析
方法一:字符串替换+坑点注意+常规解法
这题本来对于 java、py 选手来讲,直接库函数 replace 一行搞定了…对于 C++ 选手就老老实实的进行字符串匹配、替换吧。简单说下思路:
- 首先利用
map将HTML字符实体与对应字符进行一个匹配存储 - 双重循环,首先遍历
map中所有的字符实体,再遍历字符串text进行匹配查找 - 这里匹配查找使用
string对象的substr方法进行快速定位查找,匹配成功则直接用replace方法进行替换即可
思路很明确,几个 API 的熟练应用也是需要掌握的
但是:这个题暴露出的注意点很多很多…
- 首先,
text.size() - s + 1字符串对象的size()方法返回值类型是unsigned int这就直接导致了运算结果为负数时判断条件的失效,是一个很易错的知识点 - 下面的写法会导致
">"由于&的替代嵌套到下一层,导致继续替代,导致结果为>。这显然是错误的输出,一开始竞赛时好像这个测试用例是存在的。后来经过修正了。这个需要注意,而我在这采用的方法就是给{"&","&\t"}增加后续的标志位,再对结果进行删除即可。但是这个方法需要标志位不能与原有效数字起冲突,这个需要注意。这是一个简单的处理方法,也正是因为它的简单,导致了其并不安全。例如:采用一般的后缀标志位如:@、#均是无法通过测试样例的。
参见代码如下:
// 执行用时 :1992 ms, 在所有 C++ 提交中击败了100.00%的用户
// 内存消耗 :16.6 MB, 在所有 C++ 提交中击败了100.00%的用户
class Solution {
public:
map<string,string> m={{""","\""},
{"'","'"},
{">",">"},
{"<","<"},
{"⁄","/"},
{"&","&\t"}};
string entityParser(string text) {
for (auto e : m) {
string c = e.first;
int s = c.size();
int n = text.size();
if (s > n) continue;
// 每次替换size会变化,不能使用 n
// text.size() - s + 1时无符号整数,负数会很大,使得判断失效
for (int i = 0; i < (int)(text.size() - s + 1); ++i) {
if (c == text.substr(i, s)) {
text = text.replace(i, s, e.second);
}
}
}
text.erase(remove(text.begin(), text.end(), '\t'), text.end());
return text;
}
};
