1.k-medoids聚类算法
https://www.cnblogs.com/feffery/p/8595315.html 还是比较好理解的,在之前又复习了一下kmeans,它是根据重心来不断移动中心点。
它能够削弱异常值的影响,需要遍历每一个点,在第一次计算出分类结果后,在每个类中遍历除预先确定的中心点外的点,计算类中所有点之间的准则函数,这里的准则函数也就是到所有点的平均距离吧,然后计算出来之后,得出来新的中心点,然后再根据距离重新分类。
再利用刚刚看到的kmeans的一个例子,计算过程也是很好理解,假设最一开始选取p1和p2,那么一轮过后中心点可能就会变为p1和p4了。
2.GMVAE具体是怎么实现的呢?
多元高斯在代码中是怎么体现出来的?
![]()
定义模型,并给出各个维度的参数,给出了有多少个中心点,即有多少类。

定义了ZINB分布的参数,这里的k类dropout和为1? 所以对每一类都有一个单独的ZINB分布了?

初始化模型中的GMM参数,用的sklearn中的?迷惑:
from sklearn.mixture import GaussianMixture
https://scikit-learn.org/stable/modules/generated/sklearn.mixture.GaussianMixture.html 这个搜了很多,反正就是讲解的不详细,
fit函数:使用EM算法估计模型参数,https://www.cnblogs.com/dahu-daqing/p/9456137.html 这个讲的还蛮好的,讲了它的计算过程,非常好。

EM算法迭代,先计算出每个样本的得分?score不太明白,predict就是计算出每个样本属于每个子高斯模型的概率:

比如上面这个4个子高斯模型,那么是233,
总之经过fit就能够得出每个样本属于哪一个子高斯分布的概率。
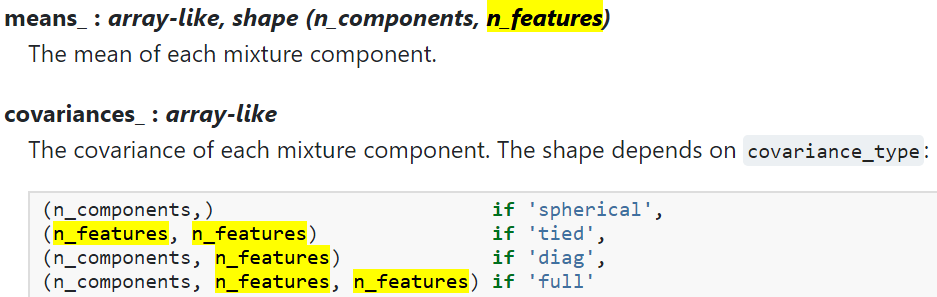
这里的n_features应该是指z的维度吧,比如说z有10维,分3个类,那么返回的means_,size就是[3,10],每一类中对应每一个维度都有一个均值和方差,方差如果是diag那么size也是一样的。那么现在拟合这个函数了。
之后调用model.fit函数里直接计算损失?其实我不太明白这个fit函数有啥用?为什么不forward呢?emm应该是因为如果直接forward的话那就还要外围再写训练的for循环吧。
![]()
损失函数中会直接计算, 出来损失,

下面看一下encoder是如何建立的?

可以发现,encoder的定义也是非常简单,但是我感觉build_mlp这个第一个参数有点问题啊,我试验了一下,h_dim只是一个数怎么能和[]直接相加呢?
def fun(lay): for l in lay: print(l) dim=[1,2] [x,y]=dim fun([x]+y) #输出: fun([x]+y) TypeError: can only concatenate list (not "int") to list
反正我大体知道代码表达的是什么意思就ok了。
下面是GaussianSample类,可以发现,它的in特征数目是隐层数目,然后对μ和方差都构建了一个线性输出层,在forward时,分别进行重采样。
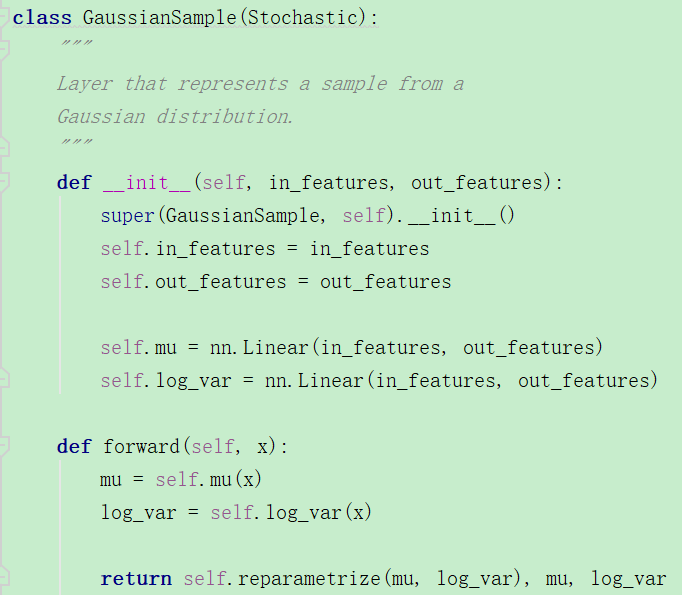
这里和普通的vae没什么差别啊。