今天字节客户端三面问了这道题,没做出来。第一,之前没见过lfu,第二,要求O(1)时间,条件苛刻一点。只能说无缘字节。
言归正传,LFU算法:least frequently used,最近最不经常使用算法。
什么意思呢:对于每个条目,维护其使用次数cnt、最近使用时间time。
cache容量为n,即最多存储n个条目。
那么当我需要插入新条目并且cache已经满了的时候,需要删除一个之前的条目。删除的策略是:优先删除使用次数cnt最小的那个条目,因为它最近最不经常使用,所以删除它。如果使用次数cnt最小值为min_cnt,这个min_cnt对应的条目有多个,那么在这些条目中删除最近使用时间time最早的那个条目(举个栗子:a资源和b资源都使用了两次,但a资源在5s的时候最后一次使用,b资源在7s的时候最后一次使用,那么删除a,因为b资源更晚被使用,所以b资源相比a资源来说,更有理由继续被使用,即时间局部性原理)。
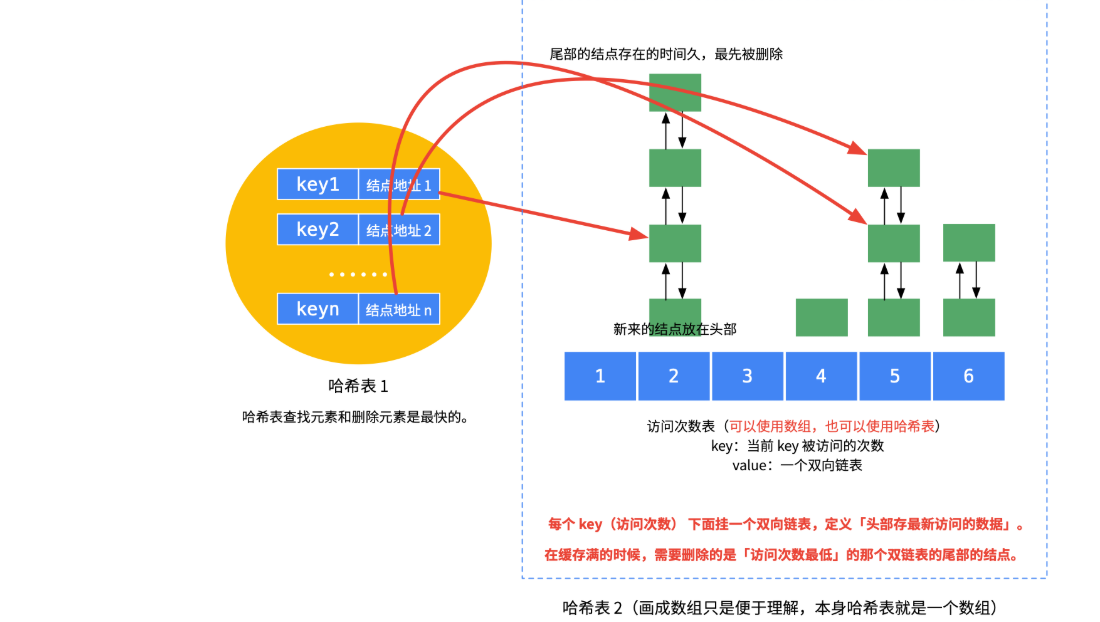
类似lru算法的想法,利用哈希表加链表。链表是负责按时间先后排序的。哈希表是负责O(1)时间查找key对应节点的。
还是用一个哈希表,用来O(1)时间查找key对应的节点。
另外由于lfu算法是按照两个维度:引用计数、最近使用时间来排序的。所以一个链表肯定不够用了。解决办法就是按照下图这样,使用第二个哈希表,key是引用计数,value是一个链表,存储使用次数为当前key的所有节点。该链表中的所有节点按照最近使用时间排序,最近使用的在链表头部,最晚使用的在尾部。这样我们可以完成O(1)时间查找key对应节点(通过第一个哈希表);O(1)时间删除、更改某节点(通过第二个哈希表)。
注意:get(查询)操作和put(插入)操作都算“使用”,都会增加引用计数。
所以get(key)操作实现思路:如果第一个哈希表中能查到key,那么取得相应链表节点。接下来在第二个哈希表中,把它移到其引用计数+1位置的链表头部,并删除之前的节点。
put(key,value)操作实现思路:如果第一个哈希表中能查找key,那么操作和get(key)一样,只是把新节点的value置为新value。
如果查不到key,那么我们有可能需要删除cache中的某一项(容量已经达到限制):直接找到第二个哈希表中最小引用计数的链表,删除其末尾节点(最晚使用)。
之后再添加新节点即可。
注意点:1.容量超限需要删除节点时,删除了第二个哈希表中的项的同时,第一个哈希表中对应的映射也应该删掉。
2.需要保持一个min_cnt整型变量用来保存当前的最小引用计数。因为容量超限需要删除节点时,我们需要O(1)时间找到需要删除的节点。
题目:
请你为 最不经常使用(LFU)缓存算法设计并实现数据结构。它应该支持以下操作:get 和 put。
get(key) - 如果键存在于缓存中,则获取键的值(总是正数),否则返回 -1。
put(key, value) - 如果键已存在,则变更其值;如果键不存在,请插入键值对。当缓存达到其容量时,则应该在插入新项之前,使最不经常使用的项无效。在此问题中,当存在平局(即两个或更多个键具有相同使用频率)时,应该去除最久未使用的键。
「项的使用次数」就是自插入该项以来对其调用 get 和 put 函数的次数之和。使用次数会在对应项被移除后置为 0 。
进阶:
你是否可以在 O(1) 时间复杂度内执行两项操作?
示例:
LFUCache cache = new LFUCache( 2 /* capacity (缓存容量) */ );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // 返回 1
cache.put(3, 3); // 去除 key 2
cache.get(2); // 返回 -1 (未找到key 2)
cache.get(3); // 返回 3
cache.put(4, 4); // 去除 key 1
cache.get(1); // 返回 -1 (未找到 key 1)
cache.get(3); // 返回 3
cache.get(4); // 返回 4
解答:
struct p{ int key,value,cnt; p(int a,int b,int c):key(a),value(b),cnt(c){} }; class LFUCache { public: unordered_map<int,list<p>::iterator> mp_key; unordered_map<int,list<p>> mp_cnt; int min_cnt=1; //key,value,cnts int n; LFUCache(int capacity) { n=capacity; } int get(int key) { if(n==0){return -1;} //cout<<"get begin "; if(mp_key.count(key)){//命中 auto iter=mp_key[key]; int cnt=iter->cnt,val=iter->value; mp_cnt[cnt+1].push_front(p(iter->key,val,cnt+1));//放到cnt+1的链表头部 mp_cnt[cnt].erase(iter); //删除之前节点 if(min_cnt==cnt and mp_cnt[cnt].size()==0){//更新min_cnt min_cnt++; } mp_key[key]=mp_cnt[cnt+1].begin(); //更新mp_key //cout<<"get end"<<endl; return val; } //cout<<"get end"<<endl; return -1; } void put(int key, int value) { if(n==0){return;} //cout<<"get begin "; if(mp_key.count(key)){//命中 auto iter=mp_key[key]; int cnt=iter->cnt; mp_cnt[cnt+1].push_front(p(key,value,cnt+1)); mp_cnt[cnt].erase(iter); mp_key[key]=mp_cnt[cnt+1].begin(); if(min_cnt==cnt and mp_cnt[cnt].size()==0){ min_cnt++; } } else{//插入新节点 if(mp_key.size()>=n){//需要删除cnt最小的list中最早出现的(mp_cnt[min_cnt].back()) int deleteKey=mp_cnt[min_cnt].back().key; mp_cnt[min_cnt].pop_back(); mp_key.erase(deleteKey); } mp_cnt[1].push_front(p(key,value,1)); mp_key[key]=mp_cnt[1].begin(); min_cnt=1;//插入新节点了,最小cnt一定是1 } //cout<<"put end"<<endl; } };
