- yolov1: Redmon J , Divvala S , Girshick R , et al. You Only Look Once: Unified, Real-Time Object Detection[J]. 2015.
- Redmon, Joseph, and Ali Farhadi. “YOLO9000: better, faster, stronger.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
- Redmon, Joseph, and Ali Farhadi. “Yolov3: An incremental improvement.” arXiv preprint arXiv:1804.02767 (2018).

1 FPN(Feature Pyramid Network)(FCN全卷积网络名字易混分割使用)
该网络融合了不同层的特征,较好的改善了多尺度检测问题
(对于深层的特征分辨率小,感受野大,利于大尺度的目标检测,而不利于检测小目标。思路1输入图像为多尺度就可得到多尺度特征图;思路2不同深度的特征图可看作不同尺度的语义特征图融合之后得多尺度特征图)
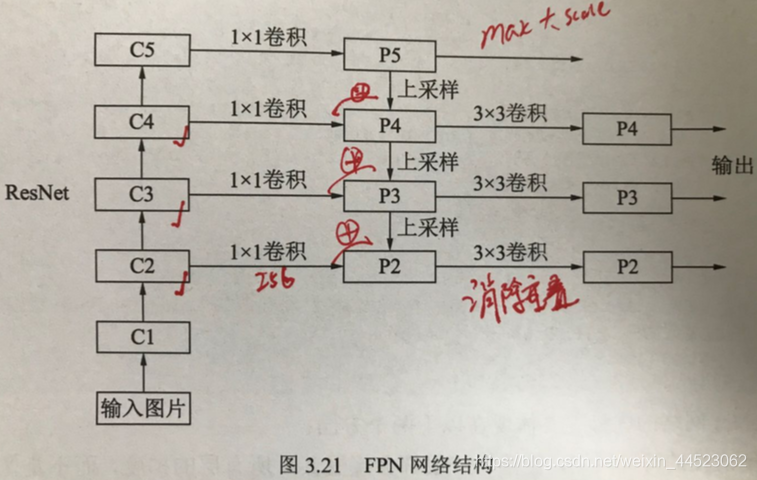
- 1自下而上: resnet
- 2自上而下:上采样最近临上采样(复制近邻元素)
- 3横向连接:上采样的高层和浅层(1x1到256通道)元素相加得到p2,p3,p4
- 4卷积融合:再用3x3卷积核提取特征,消除上采样的重叠效应
https://blog.csdn.net/WZZ18191171661/article/details/79494534
2 SSD:Single Shot Multibox Detector
- 借鉴fasterrcnn和yolo思想
- 固定框进行区域生成(提升速度),多特征信息融合(提升精度)

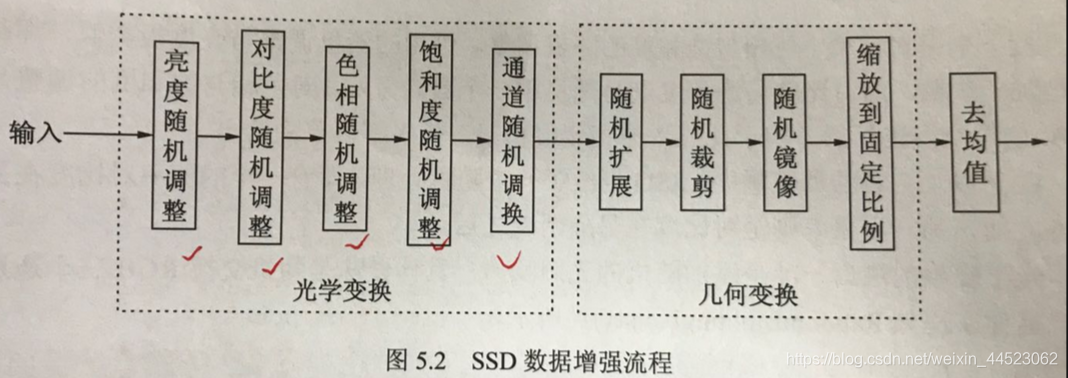
特点 - 1数据增强(光学、几何)
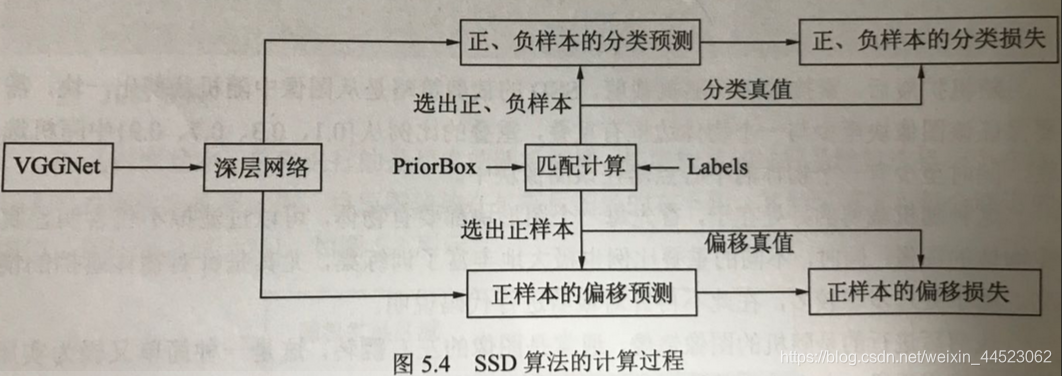
- 2vggnet+4个卷积模块,形成不同尺寸与感受野
- 3 priorBox与多层特征图:固定框在6个尺度上特征图进行预选区建立(浅层小框,深层大框)
- 4 正负样本和损失:预测box和GT求iou判断正负,然后计算分类和回归损失
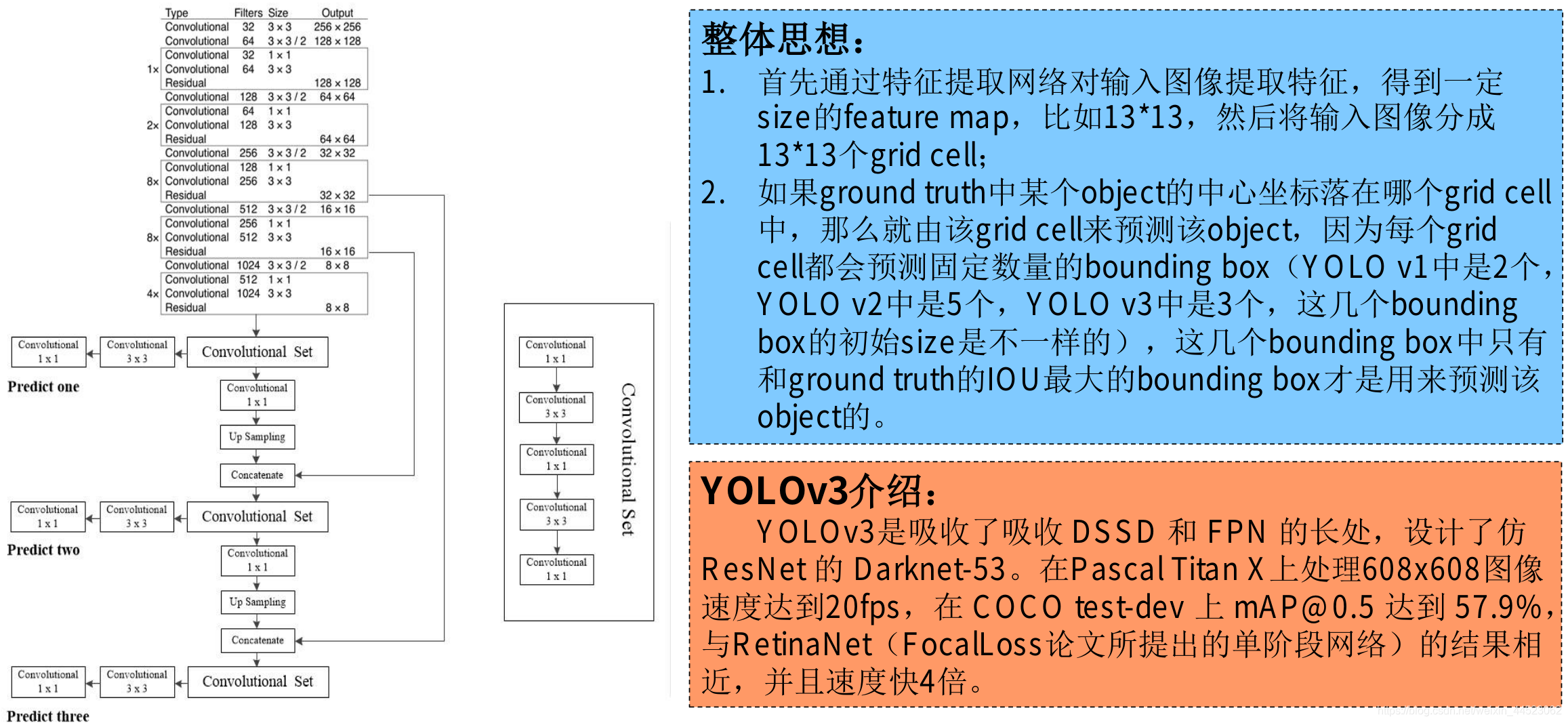
3 yolov1(无anchor预测)(45fps)
- 得到30个通道的77特征图:24卷积+2fn==》7x7x30

- 对特征图分配预测的框:49个点对应感受野,每个感受野预测2个框=98框
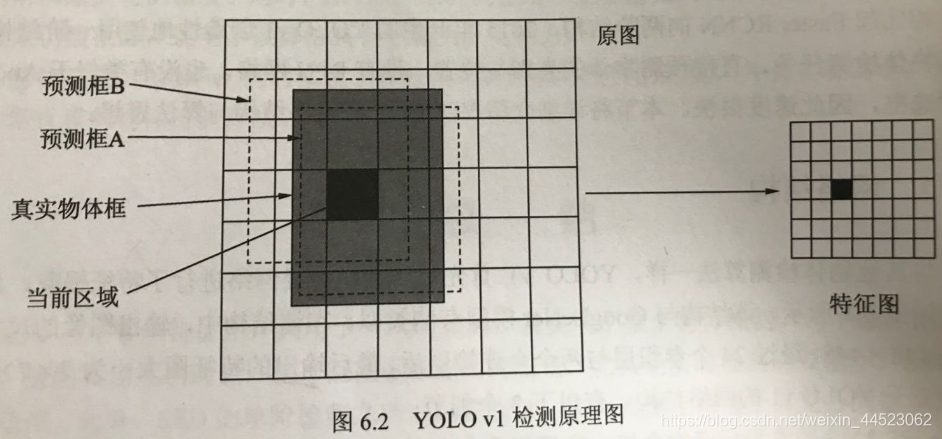
- 预测的框与真实框计算IOU,预测框是直接回归。(因为区域本身就定位在感受野内)。一个感受野实际上只预测一个类别,所以训练时选IOU大的框继续cls分类; 测试时选择框置信度高的预测cls
- 输出预测 20cls+2x(4-bbox+1confi)=28
- 20cls是栅格内包含目标的类别:两个bbox中IOU大的那个框的类别预测
- 置信度表示是否包含物体的概率(前景or背景)类似与frcnn的将背景算在类别里)
- 置信度针对预测的两个bbox是不是有物体的自信,其中是物体根据IOU最大的框判断为正
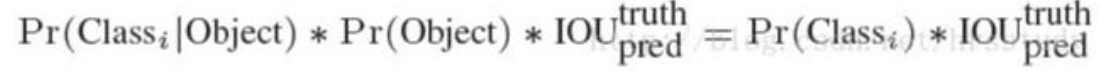
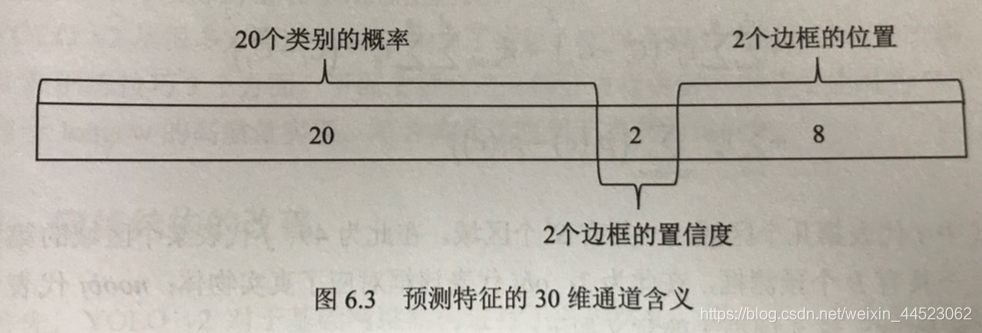
- 类别与置信度分开预测(且不含背景)
- 损失函数
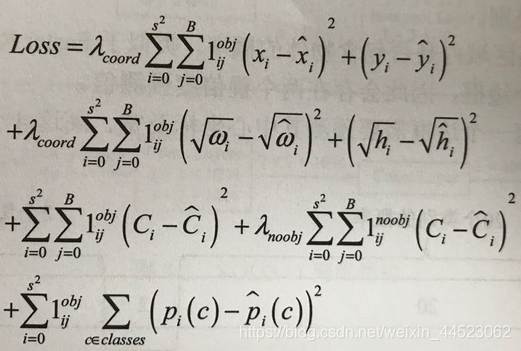
正负样本的判断:1 如果区域内有物体则取IOU大的边框为目标正样本=1,其他为负样本。负样本只有置信度损失。
- 第一项:正样本中心损失(权重设置为5,提高位置损失的比重)
- 第二项:宽高损失(因为目标尺度多变,为降低损失对尺度的敏感先开平方)
- 第三四项:正样本和负样本置信度损失(c帽的值:通过IOU最大的为正则=1,其他为0)
- 第五项:类别损失
缺点
- 1 每个区域之检测2个框的预测,类别只有一个,因此限制了检出率,和小物体检测困难
- 2 没有anchor先验,下采样较大(从原图到特征图的对应关系)导致精度底
- 3 损失函数中大物体和小物体的损失比重相同,但是小物体损失值本来就小,反响传播不明显导致小物体定位不准确
4 yolov2 (带anchor)
改进
- 1 增加anchor,预测偏移值(中心和尺度wh),降低预测难度,提升定位精度
- 先验框的得出:k-means事先对框通过IOU距离聚类(d=1-iou)得到前5个
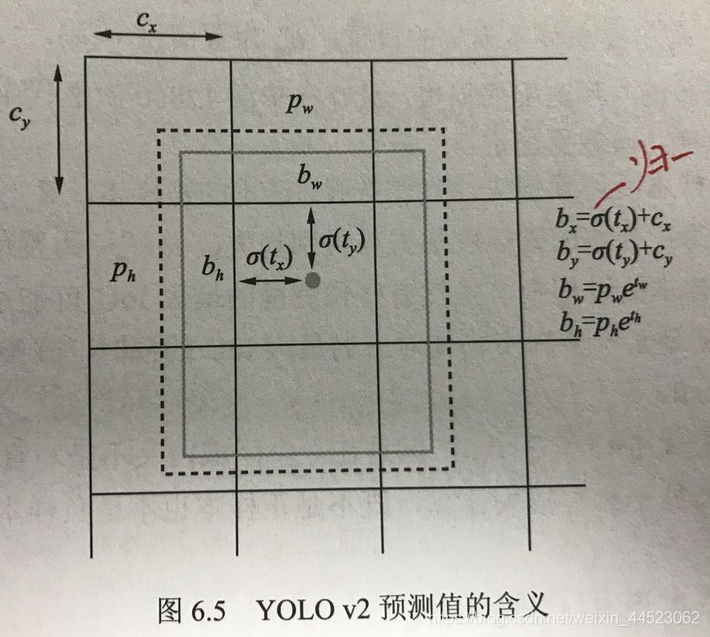
- 优化偏移公式虚线先验框,实线预测框sigmoid(tx)\ty是中心预测(cx和cy已知)
- 注意:通过sigmoid可以将中心坐标偏移量化到(0,1)利于收敛
- tw和th宽高偏移预测(pw和ph是先验聚类得到的宽高,tw/h需要取e的指数得到)
- 这里将yolov1中的置信度取sigmoid函数作为置信度
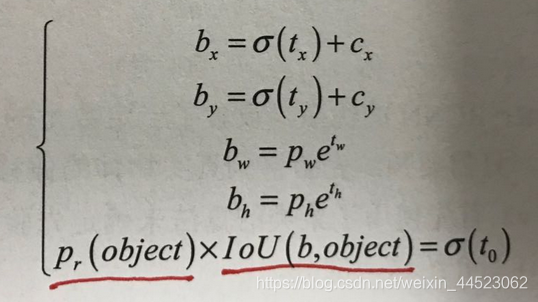
- 2 darknet(3X3和1x1卷积)19卷积和5个池化;passthrough融合的深浅特征图提升小物体检测率
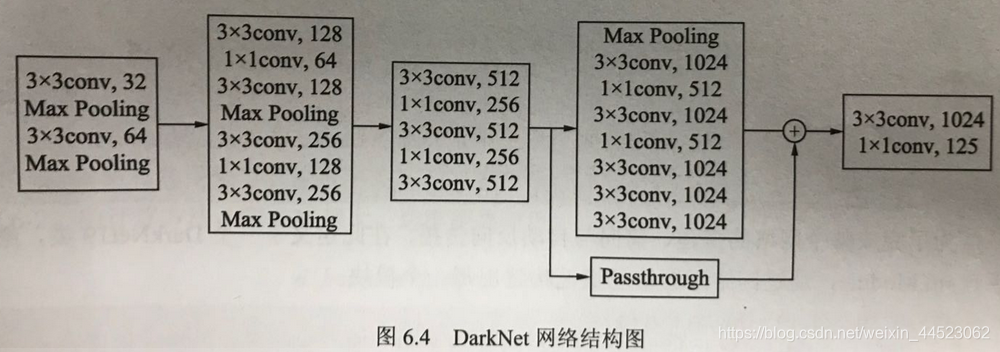
- 3 每个区域预测5个边框,每个区域输出向量=5 x [(4+1)+20]=125
- 4 注意:对上置信度预测公式其中类别预测是每个框单独的类别概率
- 5损失函数
- 正样本IOU大于0.6
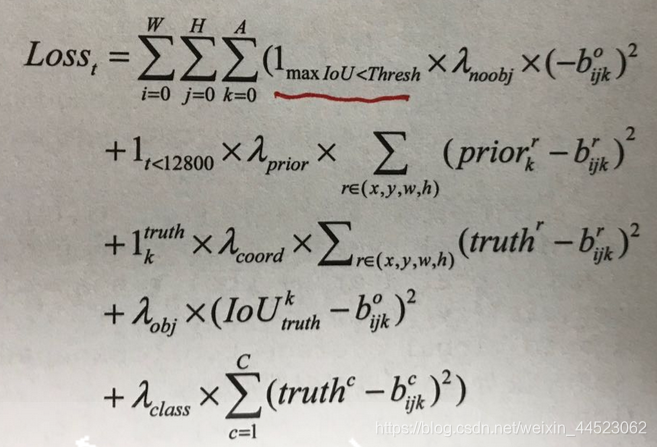
第一项负样本置信度损失
第二项先验框和预测框的损失(先在前12800次迭代中使得预测回归到聚类的先验框中)
第三项预测和真实位置损失
第四项置信度损失
第五项类别损失
- 正样本IOU大于0.6
5 yolov3(anchor+多尺度特征融合)
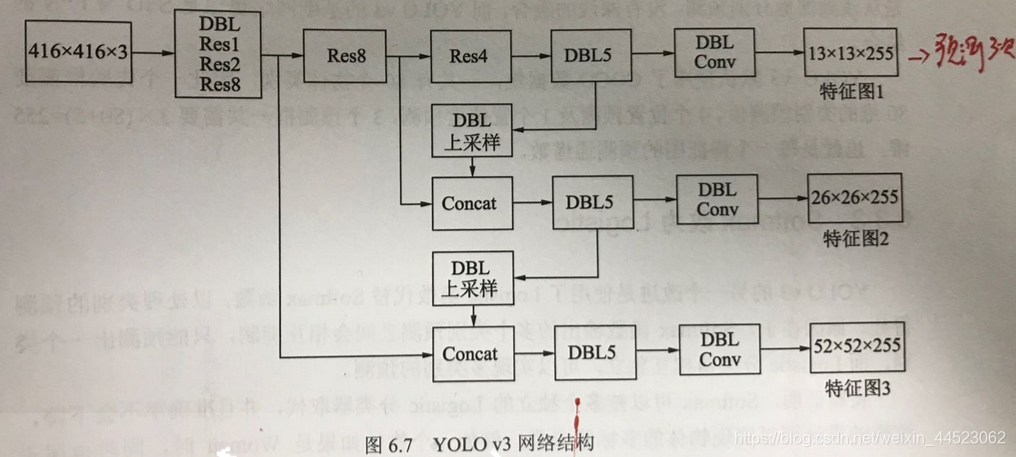
改进
- DBL: darkenet53 bn Leaky Relu
- 上采样:上池化(元素复制)、无池化(都是卷积步长为2代替)
- concat:深浅特征通道拼接(不是fpn的相加多特征)
- 输出三个尺度的特征图可以预测三次(分别检测大尺度、中尺度、小尺度的目标)
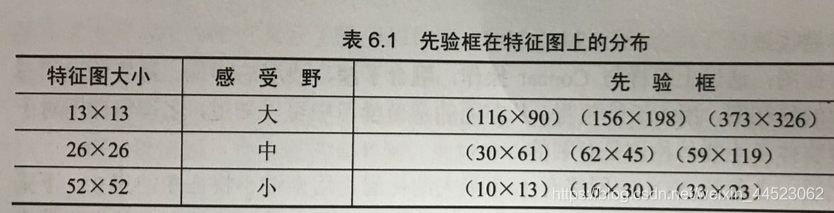

- yolov3使用coco数据,80类别一个先验框(80维度+4位置+1置信度)x3=255维度,每个特征图可以预测255
- 用logistic回归代替softmax(可以一个框可以预测多种类:person、women)(binary cross entropy loss)
实验yolov3
coco数据集 train17万,val 500
epoch17的权重参数test可以达到mAP11%
用作者的test进行验证mAP 52%
