原文地址: https://arxiv.org/abs/1512.02325
Object Detection的输入、输出、评价指标、常见数据集。
Classification:ImageNet composed of millions of classified images, (partially) utilized in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC)annual competition.
Localization:找到物体的定位,可以和classification结合
Object segmentation: 一个object的花粉,找到pixel mask of object
Object location的输出和loss fun:
vector y:
y[0] = Pc: is there any object:
- y[1~5]: bx, by, bh, bw
- y[5:8]: c1, c2, c3, 如果Pc是1,c1, c2, c3有一个是1,代表里面的东西的种类
Loss func:
- y==0时:之际算预测的y_pred[0] - y_true[0]的平方差(如果用squared error)
- y==1时:不加以区分,y_pred-y_true 所有的点的参查平方和
Landmark
- 定义:图片上的特征,which你希望DL学习出来
- 找到所有脸上的特征点
- image->conv->output = y, y[0] = is there a face, y[1,2] = the first point,
- 如果有64个landmark,len(output) = 129
=> object detection:
- 定位+classification
- 输入是一张图片
- 输出是变长的。
- finding and classifying a variable number of objects on an image.
- 应用:
- 人脸定位
- counting,把非结构化数据变成结构化数据
- Planet and Descartes Labs
- 特点:变长的输出,我们过去用的是平移窗口的方式,拿到一个窗口中所有的点的fixed-sized的特征。
Historically, the variable number of outputs has been tackled using a sliding window based approach, generating the fixed-sized features of that window for all the different positions of it. After getting all predictions, some are discarded and some are merged to get the final result.
- 特点2:不同大小的物体的识别:用不同大小的窗口,但是时间复杂度很高
- 特点3:同时解决两个问题:location + classification
之前ML的做法:
- Viola-Jones framework:proposed in 2001 by Paul Viola and Michael Jones in the paper Robust Real-time Object Detection.
- pros:快,可以时时解决ideo中的人脸识别
- 做法:
- generating different (possibly thousands) simple binary classifiers using Haar features.
- These classifiers are assessed with a multi-scale sliding window in cascade
- and dropped early in case of a negative classification.
- Use Histogram of Oriented Gradients(HOG) features and Support Vector Machine (SVM) for classification.
- It still requires a multi-scale sliding window
- and even though it’s superior to Viola-Jones
- it’s much slower.
之前DL的做法:https://tryolabs.com/blog/2017/08/30/object-detection-an-overview-in-the-age-of-deep-learning/
- OverFeat:from NYU published in 2013
- a multi-scale sliding window algorithm using Convolutional Neural Networks (CNNs).
- a multi-scale sliding window algorithm using Convolutional Neural Networks (CNNs).
- Regions with CNN features or R-CNN
- from Ross Girshick, et al. at the UC Berkeley
- 首先使用了Selective search吗?
- was published which boasted an almost 50% improvement on the object detection challenge.
- What they proposed was a three stage approach:
- Extract possible objects using a region proposal method (the most popular one being Selective Search).
- Extract features from each region using a CNN.
- Classify each region with SVMs.(用SVM来评分他识别出来的box)
- from Ross Girshick, et al. at the UC Berkeley
- Fast R-CNN
- Ross Girshick (now at Microsoft Research) published Fast R-CNN.
- 和R-CNN对比:不再使用非NN的selective search, 而是使用NN来做regional proposal(这里是NN而不是CNN)
- cons:还是再用 selective search(1st step),是算法的瓶颈
- 做法(vs R-CNN): (看不懂阿)
- instead of extracting all of them independently and using SVM classifiers
- it applied the CNN on the complete image and then used both Region of Interest (RoI) Pooling on the feature map with a final feed forward network for classification and regression.
- Not only was this approach faster, but having the RoI Pooling layer and the fully connected layers allowed the model to be end-to-end differentiable and easier to train.
-
-
paper published by Joseph Redmon (with Girshick appearing as one of the co-authors).
-
YOLO proposed a simple convolutional neural network approach which has both great results and high speed,
-
allowing for the first time real time object detection.
-
-
-
authored by Shaoqing Ren (also co-authored by Girshick, now at Facebook Research),
-
the third iteration of the R-CNN series.
-
Faster R-CNN added what they called a Region Proposal Network (RPN),
-
in an attempt to get rid of the Selective Search algorithm and make the model completely trainable end-to-end.
- 做法:
- output objects based on an “objectness” score.
- These objects are used by the RoI Pooling and fully connected layers for classification.
- 还是没有看懂这三个R-CNN的变迁。。。
-
- Single Shot Detector (SSD)
- takes on YOLO by using multiple sized convolutional feature maps achieving better results and speed
- Region-based Fully Convolutional Networks (R-FCN)
- takes the architecture of Faster R-CNN but with only convolutional networks.
- takes the architecture of Faster R-CNN but with only convolutional networks.
Sliding window detection 的方法:
- 因为输出的长度是变化的,var,所以location detection的单一长度输出并不使用,但可以作为词方法的pre-trained模型1
- 首先训练一个classifation的模型,比如一个picture是不是车,得到模型1
- 在sliding window中,用一个sliding的window里面的图片然后放入模型1中可以得到sub window是不是一个car
- 然后再resize这个region,再次放入模型1中,再resize。。。
- 只要car在image中,就存在一个window能够识别出来。
- cons:时间太长,如果用step的话性能变差,尤其是在convnet中更加复杂。
Overfeat的做法:
- 把FC变形成conv(应用1*1等)
- 思路:不再把不同的区域做不同的forward prop,因为他们可以共享参数!比如原来的sliding有4个window,有四种可能的class,最终的输出变为2*2*4,2*2分别代表4个区域,4代表4个可能的class的可能性
- 问题:bounding box的position不精准!
YOLO的方法:
- 在图片上放一个grid, eg 19*19 grid,在每一个grid中分别使用classifacation & location detection的方法
- labels for each grid cell: y = [Px, bx, by, bh, bw, c1, c2, c3] len(y) = 8, 问题,一个gird中有两个物体怎么办!
- 一共有3*3的gird,每个gird有一个长度为8的label,所以此曾的输出的output size = [3*3*8]
- 最终通过pooling&convlayers输出[3*3*8]的矩阵
- label的选取:只放到label中心属于的gird中,只可能被分配到一个gird中!
- gird更精准的话两个物体在同一个框框中的概率会更小!
- 关于bx, by:是box的中心,位置都是gird的相对位置(百分比),bh, bw也是一个比例,bxby应该在0~1之间,bh, bw可以>1
IoU: Intersection over Union 交并比(就是算overlap比例)
- 准确的size/全部区域的size,> 0.5 (convention)
- 用来判断模型的准确率(精确度)
Non- max suppression
- 目的:如果有很多overlap的框框都说这里有车,这里可能只有一辆车,所以找出来Pc(y[0])最大的框框就行了
- 过程:去掉所有Pc<0.6的点,然后找到Pc最大的框框,然后再找所有跟他的IoU>0.6的框框,去掉他们!保留这一个,再去找除了这个框框之外的Pc最大的框框,再看IoU再去掉...
Anchor box: 解决一个box只能检测出一个object的问题
- Multi-box???
- 实践中,两个东西出现在同一个gird里概率很小,但是anchor box还是要解决一下这个问题
- 但是只解决有两个东西在一个框里的情况,如果有三个,那就不好办了
- 把原来长度为8的output vector变成长度为16(2*8)的vector, 这样输出就是3*3*16了。
- 另外还定义两个anchor box,分别代表人和车,横向和纵向
- 识别的结果是(grid cell, anchor box)
- 如果输出的结果是Pc比较大,就看他和anchor box1, anchor box2的IoU,把他放入IoU大的anchor box对应的物体中。可以识别两个物体重叠的情况。
- 弱点:
- 不能解决三个物体重叠
- 不能解决两个anchor box形状相似
- 不能有效解决在一个框框中只有一个物体,就是output vector一列是0,另外一列有数字的情况
- 所以有了YOLO
YOLO:是上述算法的结合
- 如果有n个anchor box, 有c个类别,如果有 g*g个gird,那么输出的output应该是 g*g * n * (1 + 4 + c)
- label:如果对于每一个子vector, 第一个值=0时候剩下的7个(eg, c = 3)都是' doesn't matter' 的value
- output: 首先去掉所有Pc小于一定值的gird,然后分别对于每个anchor box的结果:(
- 每个grid都会输出n个框框,是bounding box
- 进行non-max suppression, 选取出最终的该种类的边框
- 难以理解的地方:为什么anchor box的数量和class的数量不同?那么最终的3*3*2*8是不是只能表示出来前两种物体的识别结果,而不能表示出来第三种物体在哪里?
- 并不是每个anchor box对应一个class!!anchor box的位置是不确定的,他只代表一个gird里面有两个或者一个物体,但是并不会写死在这里比如0-8是车,9-16是人
- 所以一个gird里面有三个东西句没办法了(但是概率很小!)
- 最终输出也都是所有box一视同仁的!先看pc够不够大,然后看他的形状更像哪个anchor box就知道他是哪个类的了,所以c=3时其实有3个anchor box,模型会根据每个gird的情况取其中两个??
RPN 系列:Regional proposal network
R-CNN:
- 使用selective search:首先把图片分成不同的区域,然后从中选取形状比较合适的,再做CNN的classification
- 对每个选中的区域,输出一个label和一个bounding box,label代表class的种类
- cons:太慢了!
Fast R-CNN:
使用Overfeat的conv的implementation of sliding windows to classify all the proposed regions
Fast R-CNN:
- 用conv network to propose regions
可以参考的link:https://blog.csdn.net/u014380165/article/details/72824889
| 一些基本概念 |
|
|
| Inference |
|
|
| Training |
|
|
| Data Aug | Data Aug: 随机裁剪[0.1-1]相当于放大图像
采样的 patch 是原始图像大小比例是 [0.1,1],aspect ratio 在12与2之间。 当 groundtruth box 的 中心(center)在采样的 patch 中时,我们保留重叠部分。 在这些采样步骤之后,每一个采样的 patch 被 resize 到固定的大小,并且以 0.5 的概率随机的 水平翻转(这真的不是放大图片到不同尺寸的trick吗?是,但是不知道这样好不好) |
有裁剪,翻转,还有数据增强:S光照旋转等等,这也是它最被argue的点 对Fast & Faster没有帮助吗?因为他们有feature pooling stage, 就是ROI layer接受了feature map和他上面的RPN的proposal的结果,所以对大小的图片可能都一视同仁,大的图片就propose大的区域了,所以物体的大小对他并没有影响?????(对,踏对图形的变化比较robust了!) more iterations |
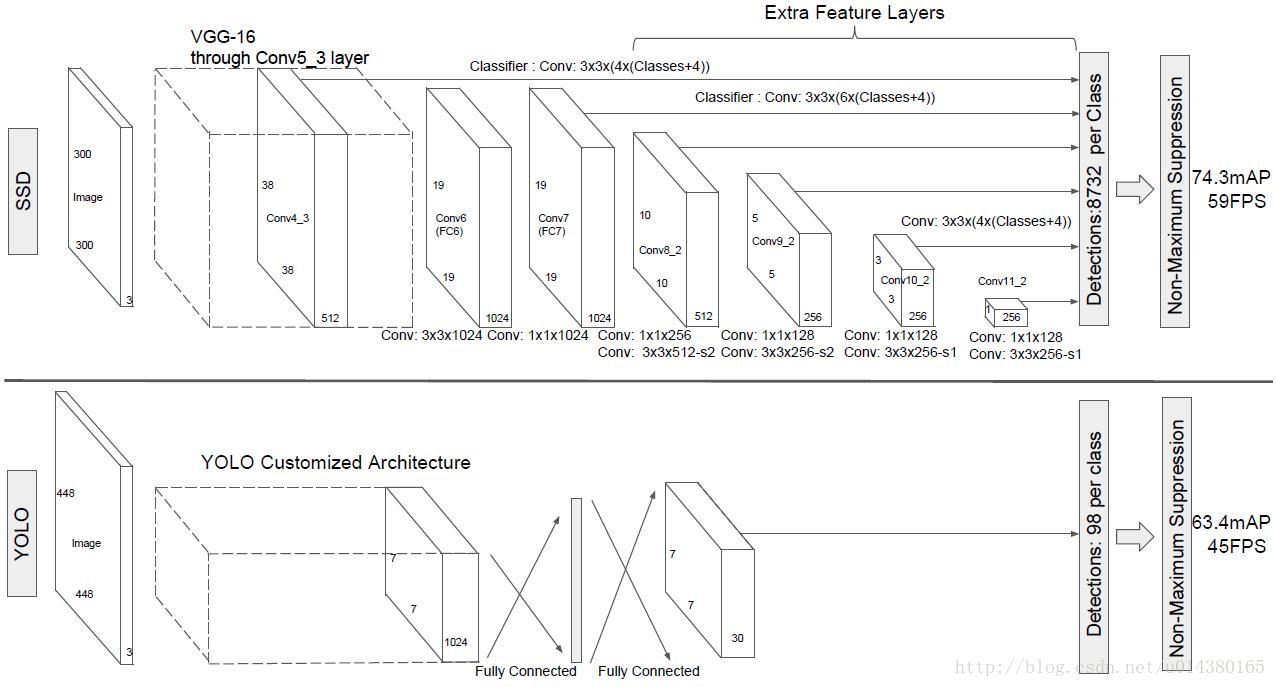
| 框架大纲 | 下图是SSD算法和YOLO算法的结构图对比。YOLO算法的输入是448*448*3,输出是7*7*30,这7*7个grid cell一共预测98个bounding box。SSD算法是在原来VGG16的后面添加了几个卷积层来预测offset和confidence(相比之下YOLO算法是采用全连接层),算法的输入是300*300*3,采用conv4_3,conv7,conv8_2,conv9_2,conv10_2和conv11_2的输出来预测location和confidence。 |
|
| 结构详解 | 详细讲一下SSD的结构,可以参看Caffe代码。SSD的结构为conv1_1,conv1_2,conv2_1,conv2_2,conv3_1,conv3_2,conv3_3,conv4_1,conv4_2,conv4_3,conv5_1,conv5_2,conv5_3(512),fc6:3*3*1024的卷积(原来VGG16中的fc6是全连接层,这里变成卷积层,下面的fc7层同理),fc7:1*1*1024的卷积,conv6_1,conv6_2(对应上图的conv8_2),……,conv9_1,conv9_2,loss。然后针对conv4_3(4),fc7(6),conv6_2(6),conv7_2(6),conv8_2(4),conv9_2(4)的每一个再分别采用两个3*3大小的卷积核进行卷积,这两个卷积核是并列的(括号里的数字代表default box的数量,可以参考Caffe代码,所以上图中SSD结构的倒数第二列的数字8732表示的是所有default box的数量,是这么来的38*38*4+19*19*6+10*10*6+5*5*6+3*3*4+1*1*4=8732),可能大物体和小物体不占大多数,所以Conv4_3 Conv 10_2 Conv11_2都只有4个scale,而且Conv4_3太大了,scale太多box太多了。这两个3*3的卷积核一个是用来做localization的(回归用,如果default box是6个,那么就有6*4=24个这样的卷积核,卷积后map的大小和卷积前一样,因为pad=1,下同),另一个是用来做confidence的(分类用,如果default box是6个,VOC的object类别有20个,那么就有6*(20+1)=126个这样的卷积核)。如下图是conv6_2的localizaiton的3*3卷积核操作,卷积核个数是24(6*4=24,由于pad=1,所以卷积结果的map大小不变,下同):这里的permute层就是交换的作用,比如你卷积后的维度是32*24*19*19,那么经过交换层后就变成32*19*19*24,顺序变了而已。而flatten层的作用就是将32*19*19*24变成32*8664,32是batchsize的大小。 |
|
| 模型特点 | TODO | |
| 实验时需要调整的超参数 |
|
|
| 参数初始化方法 |
|
|
| pool5变化的原因 |
|
|
| 在conv4_3上放了4个db的原因 |
|
|
| 实验结果如何 |
|
|
| 算法性能为什么好 |
|
|
| 和别的算法的不同 |
|
|
| 优点 |
|
|
| 为什么速度更快 |
|
|
| benchmark |
|
|
| 基本概念 |
|
|
| 缺点 |
|
ref:https://blog.csdn.net/baobei0112/article/details/78285152 小物体:
|
| 实验设计存在的问题 |
|
|
| 附加了解的问题 | feature map的尺寸越来越小:大多数cnn越深feature map 的尺寸(size)会越来越小。
|


相关工作
下面包含各种观点:
- 分为两大类:sliding window 和 region proposal classification
- 在CNN之前:state of art 分别是DPM (Deformable(可变形) Part Model) 和 Selective Search
在论文发表时的state of art?
-
- 因为R-CNN的诞生,后者成为主流
- 首先运用selective search得到的region proposals的结果
- 把上面的结果尺寸变幻放入AlexNet中
- 保留上面f7的输出特征再对针对每个类别训练一个SVM的二分类器,label就是是否属于该类别
测试阶段最后再通过svm的分类器对之前的proposal进行训练,得到每个类别修正之后的bounding box
- 也就是把卷积网络的输出做svm的分类,结合了Selective search 和 conv network based post-classification
- R-CNN = Selective search + AlexNet + SVM
- R-CNN的第一次升级:speed up post-classification, 因为post-classification这个过程十分耗时消耗内存,因为他要将几千个image的裁剪结果进行分类。
- SPPnet:
- pros: 发明了spatial pyramid pooling layer, 对区域的大小和规模更加robust
- 并且让classification layers 复用之前在不同的分辨率的feature map上学习到的特征。
- SPP layer(ROI pooling layer是SPP layer的特例:相当于只有一层的空间金字塔):把不同尺寸的featrue map上的框框的pooling为相同的,固定大小的feature。
- 框框从不同到相同的过程:做不同level的pooling,然后把他们pooling的结果串在一起!
- Fast R-CNN:
- 运用了SPP layer,去掉SVM部分,把AlexNet最后一层的输出链接到ROI pooling layer上(SPP的特例!),让他尺寸固定。
- 再把这个固定size的输出分叉,一个去softmax,一个去bbox的回归。
- loss fun不再是分开的,loss = bounding box regression + conf, 实现了end-to-end tuning
Fast R-CNN = Selective search + AlexNet + ROI pooling + 分叉实现两个pred,loss结合两个loss
- SPPnet:
- R-CNN系列的第二次升级:改善regional proposal:using deep neural networks
- MultiBox:
- Selective search的缺点:用的是low level的feature
- 所以用一个seperate的神经网络替代
- pros:regional proposal 准确率更高
- cons: 太复杂了,两个网络要结合在一起训练比较复杂。
- Faster R-CNN
- 利用了RPN:region proposal network
- 把RPN引用到Fast R-CNN上
- RPN中包含了anchor box(fixed)的概念,很想ssd的default box
- Faster R-CNN = RPN + Fast R-CNN(原来是ss)
- cons: RPN+Fast R-CNN太复杂了,要分别预训练
- RPN中的anchor box是为了提取特征(pool feature),生成feature map,再把feature map放到RPN里面得到每个fixed anchor是否有物体,然后把结果放到classification layer里面,找出他的class和bounding regression。
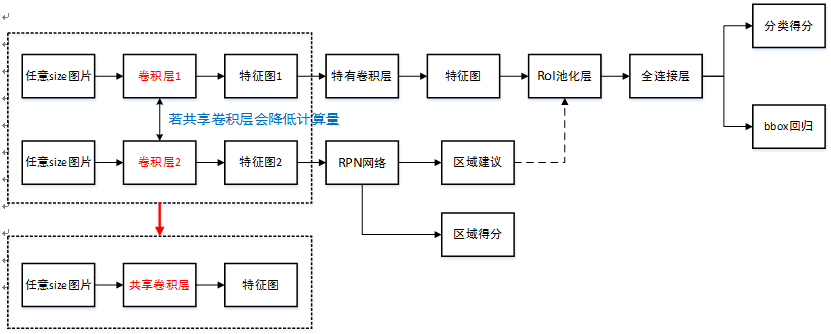
- 但是SSD是通过default box同时预测出这一个box中所有种类的box的confidence。
- MultiBox:
- 另一个系列:sliding window和ssd是一个系列的,
- 去掉了proposal的阶段!
- 直接预测位置+不同种类的object的confidence
- Overfeat:
- 把sliding window的过程换成了conv layer,最后的输出是2*2*4的话代表左上右上左下右下分别是四个class的confidence
- 缺点:loc的精确度太低了
- Yolo:
- 使用top most feature map(就是lower feature map,没有经过conv的size收缩)同时提取bbox & all class conf
- 问题:没有考虑anchor box的不同的aspect ratio
- SSD vs Overfeat:
- Oerfeat只用了topmost feature map
- Overfeat没有使用multi aspect ratio的default box(retio=1)
- SSD s YOLO:
- Yolo只用了topmost feature map
- Yolo没有使用multi aspect ratio的default box
YOLO:each grid cell only predicts two boxes,不像ssd那么多而且还可以有不同的ratio
YOLO:can only have one class, 但是SSD的一个default box可以和任何一个IoU > 0.5 的gt match
把上面结果整理到:
SSD在不同的特征层中考虑不同的尺度,RPN在一个特征层考虑不同的尺度。 唯一的能达到0.7mAP的实时检测模型 |
||||
| anchor | 有anchor | default box 类似Faster中的anchor,但是box是在不同scale上的feature上取的 | ||
| data aug | 水平翻转 | |||
| layer | fc | fc | 小的卷积进行分类回归(暴力回归) | SSD的分类和坐标回归都是全卷积的,不需要roipooling,因为faster rcnn是两步先有rpn对anchor进行2分类和回归然后修正anchor后的proposal需要重新映射到feature上取feature进行后面的细分类和回归,而SSD是一步到位的, |
数据补充
Datasets Overview:
| ImageNet | 450k | 200 | 2015 | ||
| COCO | 120K | 80 | 2014 | ||
| Pascal VOC | 12k | 20 | 2012 | ||
| Oxford-IIIT Pet | 7K | 37 | 2012 | ||
| KITTI Vision | 7K | 3 | 2014 |
那些paper厘的表格,整理好
| Faster R-CNN (VGG16) | 73.2 | 7 | ~6000 | ~1000 x 600 |
| YOLO (customized) | 63.4 | 45 | 98 | 448 x 448 |
| SSD300* (VGG16) | 77.2 | 46 | 8732 | 300 x 300 |
| SSD512* (VGG16) | 79.8 | 19 | 24564 | 512 x 512 |
下面是实验的结果:
- ps feature resample是不是就是ROI pooling,把region对应到原图然后再更改尺寸到same size然后再classification,所以想大概于小物体放大的过程了,(faster R-CNN)
- future work:
- 超参数tiling of default box(ratio & scale主要是scale在不同layer的选取)的design方式可能对优化有帮助!同时这也是weakness因为不好调参
TODO:把上面的实验整理成表格:
VOC07 SSD300 |
4952 images | 数据集小 | 4_3, 10_2, 11_2 {1, 3, 1/3, _}其他都是6个db |
40k 10^-3; 10k -4; 10k -5 |
0.2 | 0.1 |
|
|
||
| SSD512 | 12_2 for pred | 0.15 | 0.07 |
|
||||||
| VOC07+12 | 07 12(21503) | 12(10991) | 60K 10^-3; 20k -4 |
|
(不确定) 数据规模: Fast Faster- 600 YOLO- 448*448 |
|||||
| SSD512 | 0.1 | 0.04 | 为什么图片越大反而这个scale越小? | |||||||
| COCO | trainval35k | test-dev2015 | object都很小! | 160K 10^-3; 40K -4; 40K -5 | 0.15 | 0.07 (21pixels for 300*300) | 所以让scale更加精细(怎么设置scale:要找到object size和param size的trade off,不能让模型性能更差因为more db,也要考虑小物体需要更加精细的db) 对于小的物体,faster R-CNN更好:因为他有两次box refinement的过程:第一次在RPN,第二次在最后微调的时候。 |
|||
| SSD512 | 0.1 | 0.04 | ||||||||
| ILSVRC | train & val | val2 |
|
320K 10^-3; 80K -4; 40K -5 | 43.4mAP |


模型性能分析:
- data aug
- ratio aug
- atrous is faster, mAP growth
- prune boundary box
- (t2)(fig4)
- result analysis(fig3)
- more output layers at different resolution更好的证明
关于实验的问题:
- data aug 的 trick:增加了数据量+放大图片各种aug让各种算法依然有可比性吗? 相同的图片,不同的尺寸,有可比性吗?(所以测试集是不是也相当于不同了阿)
- 证明atrous更快的时调整了太多变量了把
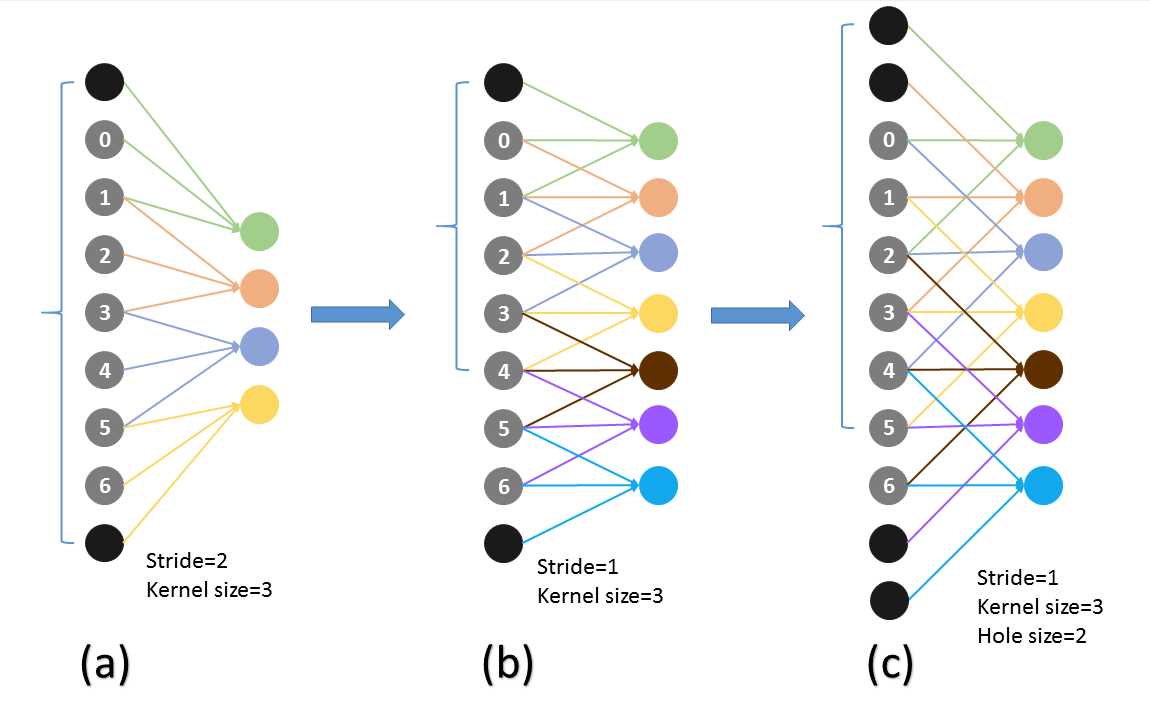
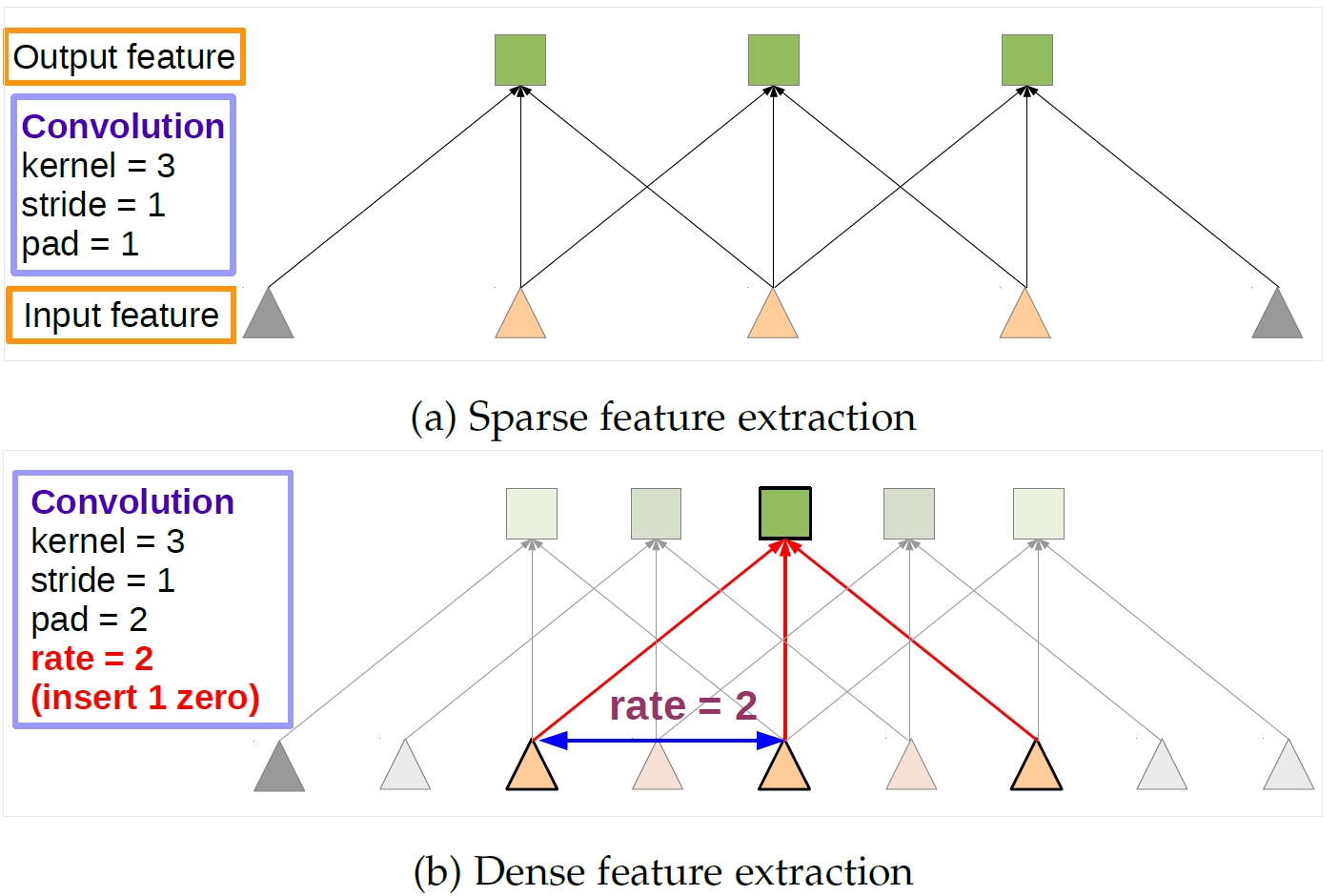
- conv5_3 for prediction is added
- 2*2 s2 的pool5被保留了
- 没有subsample FC6FC7的param(subsample这里是在做什么?)
- 是先有了3*3 s1才有的atrous,所以应该在3*3 s1的基础上不加atrous且没有conv5_3的pred对照实验吧?
- 关于为什么lower resolution解决更好:没有ROI pooling里面的collapsing bins prolbme(for low-resolution feature maps) 是什么????
- why 2*2-s2 -> 3*3-s1
- 为了让feature map更加精细吗?(可以感受野更小了)为了让feature map size更大吗?(这样有更多的default box是不是)
- why atrous: 让感受野放大,否则比原来的POOL5要更小了,为什么要让感受野放大
- why drop all the dropout layers?因为没有了fc所以参数更少所以不太容易过拟合了吗
- data aug zoom out 的过程没有看懂
- fig 5的-。5,-。5:0.95是什么意思?
- SSD512中为什么图片越大反而这个scale越小?
- LR的change的原因,s_min变化的原因,conv4_3变化的原因?
- 为什么related works放在最后了?
- match strategy是不是box只可能有一个gt?
- 如果一个box可以对应多个gt,then在计算SmoothL1(box, gt)的时候是不是要计算很多个相同的box-不同的gt?
- L1 smooth 为什么在转换w,h相对比例的时候用了log?(在计算loss func时,公式(2))
- 为什么alpha设置成了1(论文里说for cross validation但不是很懂。。)(公式1,loss function)
- 为什么计算aspect ratio的方块时候要开根号(就是公式(4)下面那一段里计算bounding box长宽的方式)
- 作者证明更多aspect ratio更好:(page10)
- 问题,没有保证#box数量不变
- atrous is faster:(page10)
- 问题,似乎更改的变量很多:
- POOL5 2*2 -s2 vs 3*3-s1,
- atrous vs no-atrous
- conv5_3 pred vs no-conv5_3 pred
- 为什么要使用atrous在POOL5上
- 每个box的感受野会被放大(为什么要放大)
- 为什么要在POOL5上做 2*2-s2 -> 3*3 s1的变动
- 排列default box(tiling)来优化模型的方法(open problem)
- conv4_3 用了 L2 norm调整scale,how?(跳过)
更新:
- 不同大小的image在mAP的对比上有影响吗
- data aug增加了数据量对模型对比有影响吗
- 训练集不同测试集相同模型对比有可信度吗 (train, trainval, trainval35k)
- 性能提升幅度比较小,小于两个标准差,可信度降低 - paper中是不是看不出来
- SSD这些性能有没有调参调好的结果
本文涉及了以下内容(含源码解释)- 关于Scale的计算
- 代码上的conv detector是怎么实现的(流程)
- 每一个conv detector是什么结构
- 每一个feature map对应scale怎样计算
- 怎样生成原图中的scale框框
- step是什么,怎么计算
- 每一个feature map对应一个min_size, max_size都是怎么算的
- 最终default box的数量,confidence的数量怎么计算
以conv4_3为例

上图解释(conv detector是怎么实现的):
在conv4_3 feature map网络pipeline分为了3条线路:
- 经过一次batch norm+一次卷积后,生成了[1, num_class*num_priorbox, layer_height, layer_width]大小的feature用于softmax分类目标和非目标(其中num_class是目标类别,SSD 300中num_class = 21,即20个类别+1个背景)
- 经过一次batch norm+一次卷积后,生成了[1, 4*num_priorbox, layer_height, layer_width]大小的feature用于bounding box regression(即每个点一组[dxmin,dymin,dxmax,dymax],参考Faster R-CNN 2.5节)
- 生成了[1, 2, 4*num_priorbox]大小的prior box blob,其中2个channel分别存储prior box的4个点坐标和对应的4个variance
ref: https://blog.csdn.net/u014380165/article/details/72824889 有很具体的conv detector的讲解!
# conv4_3上设置的4个不同的比例,feature上每个点对应4个default(prior) box
layer {
name:
"conv4_3_norm_mbox_conf"
type:
"Convolution"
bottom:
"conv4_3_norm"
top:
"conv4_3_norm_mbox_conf"
convolution_param {
num_output: 84 # 21*4 feature上每个点对应4个
default
(prior) box, 21个类别
pad: 1
kernel_size: 3
stride: 1
}
}
layer {
name:
"conv4_3_norm_mbox_loc"
type:
"Convolution"
bottom:
"conv4_3_norm"
top:
"conv4_3_norm_mbox_loc"
convolution_param {
num_output: 16 # 4*4 feature上每个点对应4个
default
(prior) box, 4个坐标
pad: 1
kernel_size: 3
stride: 1
}
}
|
ref: https://blog.csdn.net/u013010889/article/details/78670672 计算scale
ref: https://blog.csdn.net/u013010889/article/details/78658135 FPN


mbox_source_layers = [
'conv4_3'
,
'fc7'
,
'conv6_2'
,
'conv7_2'
,
'conv8_2'
,
'conv9_2'
]
# in percent %
min_ratio = 20
max_ratio = 90
step =
int
(math.
floor
((max_ratio - min_ratio) / (len(mbox_source_layers) - 2)))
min_sizes = []
max_sizes = []
for
ratio in xrange(min_ratio, max_ratio + 1, step):
min_sizes.append(min_dim * ratio / 100.)
max_sizes.append(min_dim * (ratio + step) / 100.)
min_sizes = [min_dim * 10 / 100.] + min_sizes
max_sizes = [min_dim * 20 / 100.] + max_sizes
print min_sizes
print max_sizes
''
'
conv4_3特殊对待了
[30.0, 60.0, 111.0, 162.0, 213.0, 264.0]
[60.0, 111.0, 162.0, 213.0, 264.0, 315.0]
''
'
|
''
'
default
box的生成
'feature_maps'
: [38, 19, 10, 5, 3, 1],
'min_dim'
: 300,
'steps'
: [8, 16, 32, 64, 100, 300],
'min_sizes'
: [30, 60, 111, 162, 213, 264], # 这相当于featuremap上每个单元对应的receptive field, 最大最小的产生是因为有不同的aspect ratio!终于明白featuremap上的bounding box是怎么生成的了,它的作用yu是在原图上的!!!
'max_sizes'
: [60, 111, 162, 213, 264, 315],
'aspect_ratios'
: [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
''
'
for
k, f in enumerate(self.feature_maps):
for
i, j in product(range(f), repeat=2):
f_k = self.image_size / self.steps[k]
# unit center x,y
cx = (j + 0.5) / f_k
cy = (i + 0.5) / f_k
# aspect_ratio: 1 # ratio=1时候有两个!
# rel size: min_size
s_k = self.min_sizes[k] / self.image_size
mean += [cx, cy, s_k, s_k] # 假设原图的左上角是(0,0),右下角是(1,1),eg:[0.5,0.6,0.7,0.7]代表这个bounding box的左上角在图片中心,长宽分别占整张原图的70%。类似于Faster R-CNN
# aspect_ratio: 1
# rel size: sqrt(s_k * s_(k+1))
s_k_prime =
sqrt
(s_k * (self.max_sizes[k] / self.image_size))
mean += [cx, cy, s_k_prime, s_k_prime]
# rest of aspect ratios
for
ar in self.aspect_ratios[k]:
mean += [cx, cy, s_k *
sqrt
(ar), s_k /
sqrt
(ar)]
mean += [cx, cy, s_k /
sqrt
(ar), s_k *
sqrt
(ar)]