HTMLParser为Python的常用内建模块,使用时经常是继承HTMLParser并重写其方法。
其中常用方法如下:
handle_starttag(tag, attrs)处理开始标签,比如<input type="text" value="3">,tag即为input,attrs为储存对应属性,值的元组(tuple)列表(list):[('type':'text'),('value':'3')]
handle_endtag(tag)处理结尾标签
handle_data(data)处理标签内容
handle_startendtag(tag, attrs)处理<img src="" />这类标签
handle_comment(data)处理注释内容#例子
from html.parser import HTMLParser
class MyHTMLParser(HTMLParser):
def __init__(self):
HTMLParser.__init__(self)
def handle_starttag(self, tag, attrs):
"""
recognize start tag, like <div>
:param tag:
:param attrs:
:return:
"""
print("Encountered a start tag:", tag)
print(attrs)
def handle_endtag(self, tag):
"""
recognize end tag, like </div>
:param tag:
:return:
"""
print("Encountered an end tag :", tag)
def handle_data(self, data):
"""
recognize data, html content string
:param data:
:return:
"""
print("Encountered some data :", data)
def handle_startendtag(self, tag, attrs):
"""
recognize tag that without endtag, like <img />
:param tag:
:param attrs:
:return:
"""
print("Encountered startendtag :", tag)
def handle_comment(self,data):
"""
:param data:
:return:
"""
print("Encountered comment :", data)
parser = MyHTMLParser()
parser.feed('<html><head><title>Test</title></head>'
'<body><h1>Parse me!</h1><img src = "" /><input type="text" value="3"></input>'
'<!-- comment --></body></html>')
parser.close()
#输出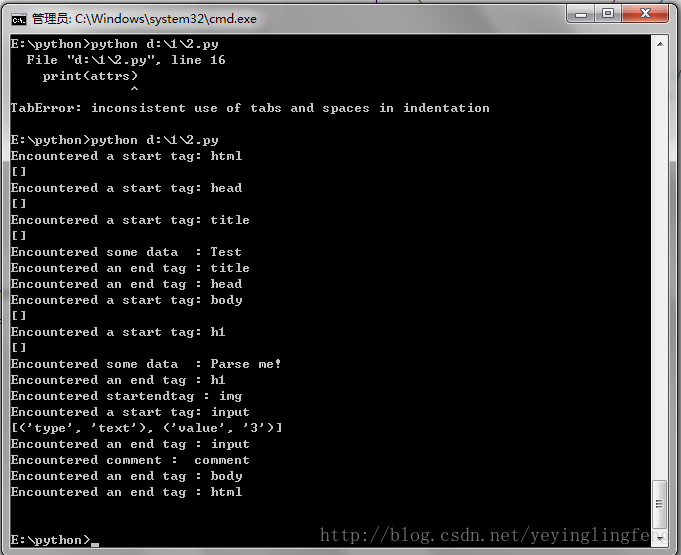
简单实际用例
从csdn博客视图列表中获取所有自己博文的名字+url
http://blog.csdn.net/yeyinglingfeng?viewmode=contents
主要思路就是利用各个函数的执行顺序
#查看网页源代码后可知所需数据在下面的html中,url在<a>标签中的href中,标题在内容中,因为HTMLParser在检索html时是按照出现的先后顺序触发各个方法的,所以在触发handle_starttag函数后,只要有内容,就会触发handle_data函数,所以可以利用这点来绑定url和title并存入list。PS:我这里多加的锁定可能有点多余。
<h1>
<span class="link_title"><a href="/yeyinglingfeng/article/details/78332515">
(1)Python笔记:抓取CSDN博文
</a>
</span>
</h1>#从csdn博客视图列表中获取所有自己博文的名字+url
#http://blog.csdn.net/yeyinglingfeng?viewmode=contents
#coding:utf-8
from html.parser import HTMLParser
import urllib.request
import re
import sys
class MyHTMLParser(HTMLParser):
def __init__(self):
HTMLParser.__init__(self)
self.articleStr = []
self.check='N'
self.num=0
def handle_starttag(self, tag, attrs):
if tag =='a':
if len(attrs)==1 and attrs[0][0]=='href' and '/yeyinglingfeng/article/details/' in attrs[0][1] and '#comments' not in attrs[0][1]:
self.check='Y'
article={}
article['url']='http://blog.csdn.net'+attrs[0][1]
self.articleStr.append(article)
self.num+=1
def handle_endtag(self, tag):
pass
def handle_data(self, data):
if self.check=='Y':
self.articleStr[-1]['articleTitle']=data.replace('\r\n','').strip()
self.check='N'
def handle_startendtag(self, tag, attrs):
pass
def handle_comment(self,data):
pass
def getHtmlInfo(url):
print('url:'+url)
return str(urllib.request.urlopen(url).read(),'utf-8')
def saveInfo(info):
try:
with open('d:\\1\\csdnList.txt','w',encoding='utf-8') as file_write:
file_write.write(info)
except:
print('error:something faile')
html=getHtmlInfo("http://blog.csdn.net/yeyinglingfeng?viewmode=contents")
parser = MyHTMLParser()
parser.feed(html)
parser.close()
allInfo=''
for each in parser.articleStr:
allInfo+=each['articleTitle']+' url:'+each['url']+'\n'
#print(allInfo)
saveInfo(allInfo)
print(str(parser.num))保存的txt文件