对train_a的心音数据MFCC特征提取后,使用HMM进行异常识别
训练集:1-29
测试集:270-299
实验
实验结果

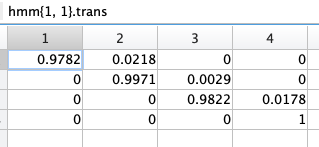

分析讨论
1.初值设定影响
采用的HMM训练方法( Baum- Welch算法)本质上是一种梯度下降方法,在训练过程中有可能到达局部最小值。因此,初值的选取比较重要,好的初值可以避免局部极小问题。可以加入一定的优化方法来选取初值(如可采取人工免疫算法在某个初值设定区间中选取一组最优参数作为初值,再用Baum- Welch算法进行训练)。在离散HMM中,参数B对系统的性能有很大影响,超过了参数A和π。所以也可以单独对参数B初值的选取采用一定的优化方法。
2.训练数据量影响
连续隐马尔可夫模型需要较少的训练数据,但对于离散HMM,要求的训练数据量较大。为了训练出可靠的参数模型,必须加大训练集的数据。本次实验,由于硬件速度原因,仅选用了30组训练集,未能训练出可靠的参数模型。之后,考虑增加训练集的样本数,系统识别率应能大幅度提高。
3.输出概率矩阵的平滑问题

原理
3个关键问题

3个解决方法

代码
clear all;
% 读入训练数据集train.mat
load train.mat;
N = 4; % hmm的状态数
M = [3,3,3,3]; % 每个状态对应的混合模型成分数
for i = 1:length(D) % 数字的循环
fprintf('\n计算标号%d的mfcc特征参数\n',i);
for k = 1:length(D{i}) % 样本数的循环
obs(k).sph = D{i}{k}; % 数字i的第k个语音
obs(k).fea = mfcc(obs(k).sph); % 对语音提取mfcc特征参数
end
fprintf('\n训练标号%d的hmm\n',i);
hmm_temp=inithmm(obs,N,M); %初始化hmm模型
hmm{i}=baum_welch(hmm_temp,obs); %迭代更新hmm的各参数
end
fprintf('\n训练完成!\n');
% 读入待识别语音
fprintf('开始识别\n');
accuracy=[0,0];
for i=1:length(C)
add=0;
for k = 1:length(C{i}) % 样本数的循环
rec_sph=C{i}{k}; % 待识别语音
rec_fea = mfcc(rec_sph); % 特征提取
% 求出当前语音关于"正常、异常"hmm的p(X|M)、
for m=1:2
pxsm(m) = viterbi(hmm{m}, rec_fea);
end
[d,n] = max(pxsm); % 判决,将该最大值对应的序号作为识别结果
if n == i
add=add+1;
end
end
accuracy(i) =add/length(C{i})*100;
end
fprintf('识别正常心音的概率%6.4f\n',accuracy(1))
fprintf('识别异常心音的概率%6.4f\n',accuracy(2))
train——BW方法
EM算法是一种解决存在隐含变量优化问题的有效方法。EM算法是期望极大(Expectation Maximization)算法的简称,EM算法是一种迭代型的算法,在每一次的迭代过程中,主要分为两步:即求期望(Expectation)步骤和最大化(Maximization)步骤。

根据前向后向算法,计算出的alpha,beta
根据转移概率公式,计算ksai
%-----------计算转移概率ksai-------
%对于观测序列,在时刻t从状态Si转移到转台Sj的转移概率ksai
ksai=zeros(T-1,N,N);
for t=1:T-1
denom=sum(alpha(t,:).*beta(t,:));
for i=1:N-1
for j=i:i+1
nom=alpha(t,i)*trans(i,j)*mixture(mix(j),O(t+1,:))*beta(t+1,j);
ksai(t,i,j)=c(t)*nom/denom;
end
end
end
根据B-W重估公式计算^a/b

%----重估转移概率矩阵A
for i=1:N-1
demon=0;
for k=1:K
tmp=param(k).ksai(:,i,:);
demon=demon+sum(tmp(:)); %对时间t,j求和
end
for j=i:i+1
nom=0;
for k=1:K
tmp=param(k).ksai(:,i,j);
nom=nom+sum(tmp(:)); %对时间t求和
end
hmm.trans(i,j)=nom/demon;
end
end

function [prob,q]=viterbi(hmm,O)
%Viterbi算法
%输入:
%hmm--hmm模型
%O--输入观察序列,T*D,T为帧数,D为向量维数
%输出:
%prob--输出概率
%q--状态序列
init=hmm.init; %初始概率
trans=hmm.trans; %转移概率
mix=hmm.mix; %高斯混合
N=hmm.N; %HMM的状态数
T=size(O,1); %语音帧数
%计算log(init)
ind1=find(init>0);
ind0=find(init<=0);
init(ind1)=log(init(ind1));
init(ind0)=-inf;
%计算log(trans);
ind1 = find(trans>0);
ind0 = find(trans<=0);
trans(ind0) = -inf;
trans(ind1) = log(trans(ind1));
%初始化
delta=zeros(T,N); %帧数×状态数
fai=zeros(T,N);
q=zeros(T,1);
%t=1;
for i=1:N
delta(1,i)=init(i)+log(mixture(mix(i),O(1,:)));
end
%t=2:T
for t=2:T
for j=1:N
[delta(t,j),fai(t,j)]=max(delta(t-1,:)+trans(:,j)');
delta(t,j)=delta(t,j)+log(mixture(mix(j),O(t,:)));
end
end
%最终概率和最后节点
[prob q(T)]=max(delta(T,:));
%回溯最佳状态路径
for t=T-1:-1:1
q(t)=fai(t+1,q(t+1));
end
感谢
《MATLAB在语音信号分析和合成中的应用》[宋知用][[北京航空航天出版社][2013.11]
《语音信号处理实验教程》 [梁瑞宇,赵力,魏昕编][机械工业出版社][2016.03]
《数字语音处理及MATLAB仿真 第2版》 [张雪英][电子工业出版社][2016.05]
HMM学习最佳范例——我爱自然语言处理网站翻译
链接:HMM笔记(备份) 密码:x30v(只对自己有用)
