本文着重介绍一下哈希表的两种实现方式,链地址法和线性探测法(除余留数)。
1.链地址法
我们先来看一下链地址法是怎样解决冲突的。

假如我们要插入一个元素15,15%7 = 1.所以应插入到索引为1的链表。插入后的链表为:

如果我们继续插入一个元素22,22%7=1,所以还插在索引为1的链表,插入后的结果为:

相信大家已经了解了链地址法到底是怎么解决冲突和存储的,接下来看下代码实现(无限扩容的hash表):
#pragma once
# include<iostream>
# include<vector>
#include<list>
using namespace std;
// 计算哈希值的类
template<typename T>
class CHash
{
public:
int operator()(const T& val)
{
// 默认用除留余数法
return val;
}
};
template<typename T,typename hashType = CHash<T>>
class HashTable
{
public:
HashTable(int size = 3, double lf = 0.75)
:_loadFactor(lf)
{
// 给哈希表开辟数组空间的
_hashVec.resize(size);
}
//插入操作
void Put(const T& value)
{
//计算当前的装载因子是否满足条件
int len = 0;
for (list<T> ele : _hashVec)
{
if (!ele.empty())
{
++len;
}
}
//不满足条件进行扩容,元素调整
if ((double)(len + 1) / _hashVec.size() >= _loadFactor)
{
//扩容为以前的大小的2倍
int size = _hashVec.size();
_hashVec.resize(2 * size);
//记录以前的元素
vector<T> temp;
for (list<T> &ele : _hashVec)
{
for (T value : ele)
{
temp.push_back(value);
}
//将链表清空
ele.clear();
}
//重存以前的元素
for (auto ele : temp)
{
int index = _hash(ele) % _hashVec.size();
_hashVec[index].push_back(ele);
}
}
int index = _hash(value) % _hashVec.size();
_hashVec[index].push_back(value);
}
//删除操作
void Remove(T value)
{
int index = _hash(value) % _hashVec.size();
if (find(_hashVec[index].begin(), _hashVec[index].end(),value)== _hashVec[index].end())
{
cout << "查无此元素" << endl;
return;
}
_hashVec[index].remove(value);
}
//查询操作
void Querry(T value)
{
int index = _hash(value) % _hashVec.size();
if (find(_hashVec[index].begin(), _hashVec[index].end(), value) == _hashVec[index].end())
{
cout << "查无此元素" << endl;
return;
}
auto it = find(_hashVec[index].begin(), _hashVec[index].end(), value);
cout << "存在于第" << index << "条链表"<< endl;
}
//打印操作
friend ostream& operator<< <>(ostream& out, const HashTable<T>& tmp);
private:
vector<list<T>> _hashVec;
double _loadFactor;//记录加载因子
hashType _hash; // 专门计算T类型对象的哈希值的
};
template<typename T>
ostream& operator<< <>(ostream& out, const HashTable<T>& tmp)
{
int i = 0;
for (list<T> ele : tmp._hashVec)
{
cout << "第" << i << "条链的内容为:";
for (T value : ele)
{
cout << value << ends;
}
cout << endl;
++i;
}
return out;
}
int main()
{
HashTable<int> hashTable;
hashTable.Put(1);
cout << "插入1次" << endl;
cout << hashTable << endl;
hashTable.Put(2);
hashTable.Put(3);
hashTable.Put(4);
cout << hashTable << endl;
hashTable.Querry(4) ;
hashTable.Remove(4);
cout << hashTable << endl;
return 0;
}运行结果如下图所示:

2.线性探测法
来来来,一图明所有:
扫描二维码关注公众号,回复:
10712651 查看本文章


代码实现:
# include<iostream>
# include<string>
# include<vector>
using namespace std;
# define MAX 100
// 计算哈希值的类
template<typename T>
class CHash
{
public:
int operator()(const T& val)
{
// 默认用除留余数法
return val;
}
};
// 线性探测法实现的哈希表结构
template<typename T, typename HashType = CHash<T>>
class CHashTable
{
public:
CHashTable(int size = 3, double lf = 0.75)
:_loadFactor(lf)
{
// 给哈希表开辟数组空间的
_hashVec.resize(size);
}
void put(const T& val)
{
//计算当前的装载因子是否满足条件。
int size = _hashVec.size();
int len = 0;
int index = 0;
for (int i = 0; i < size; ++i)
{
if ((_hashVec.begin() + i)->_data != T())
{
++len;
}
}
if ((double)((len + 1) / _hashVec.size()) >= _loadFactor)
{
_hashVec.resize(2 * _hashVec.size());
_loadFactor /= 2.0;
//按照新的_hashVec.size()将元素的存储位置进行调整
T tmp[MAX];
int count = 0;
for (int i = 0; i < size; ++i)
{
if (_hashVec[i]._state == STATE_USE)
{
tmp[count] = _hashVec[i]._data;
++count;
_hashVec[i]._data = T();
_hashVec[i]._state = STATE_UNUSE;
}
}
//重存扩容以前的元素
for (int i = 0; i < count; ++i)
{
index = _hash(tmp[i]) % _hashVec.size();
for (int j = index;; j = (j + 1) % _hashVec.size())//因为hash表一直在扩容,所以只要有元素就一定能放下。
{
// STATE_UNUSE STATE_USE STATE_USE
//将元素按照规则放入哈希表。
if (_hashVec[j]._state == STATE_UNUSE || _hashVec[j]._state == STATE_USED)
{
_hashVec[j]._data = tmp[i];
_hashVec[j]._state = STATE_USE;
break;
}
}
}
}
index = _hash(val) % _hashVec.size();
for (int i = index;; i = (i + 1) % _hashVec.size())//因为hash表一直在扩容,所以只要有元素就一定能放下。
{
// STATE_UNUSE STATE_USE STATE_USE
//将元素按照规则放入哈希表。
if ((_hashVec.begin() + i)->_state == STATE_UNUSE || (_hashVec.begin() + i)->_state == STATE_USED)
{
(_hashVec.begin() + i)->_data = val;
(_hashVec.begin() + i)->_state = STATE_USE;
_loadFactor = (double)(len + 1) / _hashVec.size();
return;
}
}
}
T out(T val)
{
int len = 0;
for (int i = 0; i < _hashVec.size(); ++i)
{
if ((_hashVec.begin() + i)->_data != T())
{
++len;
}
}
int index = _hash(val) % _hashVec.size();
for (int i = index;; i = (i + 1) % _hashVec.size())//因为hash表一直在扩容,所以只要有元素就一定能放下。
{
// STATE_UNUSE STATE_USE STATE_USE
//将元素按照规则放入哈希表。
if ((_hashVec.begin() + i)->_state == STATE_UNUSE)
{
return -100;
}
if ((_hashVec.begin() + i)->_data == val)
{
T a = (_hashVec.begin() + i)->_data;
(_hashVec.begin() + i)->_state = STATE_USED;
(_hashVec.begin() + i)->_data = T();
_loadFactor = (double)(len - 1) / _hashVec.size();
return a;
}
}
}
friend ostream& operator<< <>(ostream& out, const CHashTable<T, CHash<T>>& tmp);
private:
// STATE_UNUSE 删除 STATE_USED 0
enum STATE { STATE_UNUSE, STATE_USE, STATE_USED };
struct Node
{
Node(T data = T())
:_data(data), _state(STATE_UNUSE)
{}
T _data;
STATE _state;
};
vector<Node> _hashVec;
double _loadFactor; // 记录加载因子
HashType _hash; // 专门计算T类型对象的哈希值的
};
template<typename T, typename HashType = CHash<T>>
ostream & operator<< <>(ostream & out, const CHashTable<T, CHash<T>> & tmp)
{
for (auto it : tmp._hashVec)
{
out << it._data << " ";
}
return out;
}
int main()
{
CHashTable<int, CHash<int>> hash(6, 0.75);
hash.put(1);
cout << hash << endl;
hash.put(2);
cout << hash << endl;
hash.put(3);
cout << hash << endl;
hash.put(4);
cout << hash << endl;
hash.put(5);
cout << hash << endl;
hash.put(6);
cout << hash << endl;
hash.put(7);
cout << hash << endl;
hash.out(6);
cout << hash << endl;
hash.out(5);
cout << hash << endl;
hash.out(4);
cout << hash << endl;
hash.out(3);
cout << hash << endl;
hash.out(2);
cout << hash << endl;
hash.out(1);
cout << hash << endl;
system("pause");
return 0;
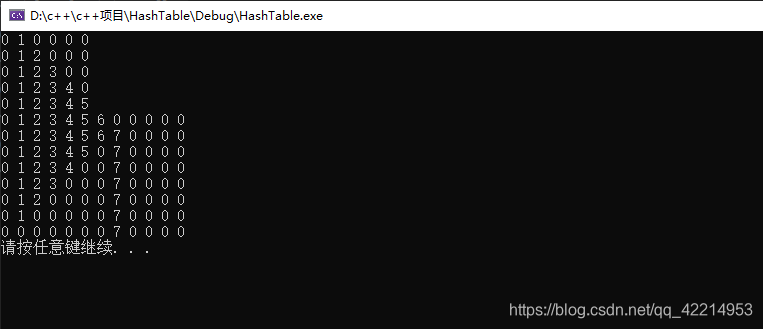
}测试结果: