紧接着之前获取完文章标题标签完之后的操作
使用完nltk分词对文章标题分类之后
延续之前的思路开始实现
过程中遇到的一些问题
获取方法的问题
python方面
如果是采用方法1手写的ngram标签采集方法,那么可以很方便的获取词频以及标签
如果是方法2,Text.collocations()方法返回的是none
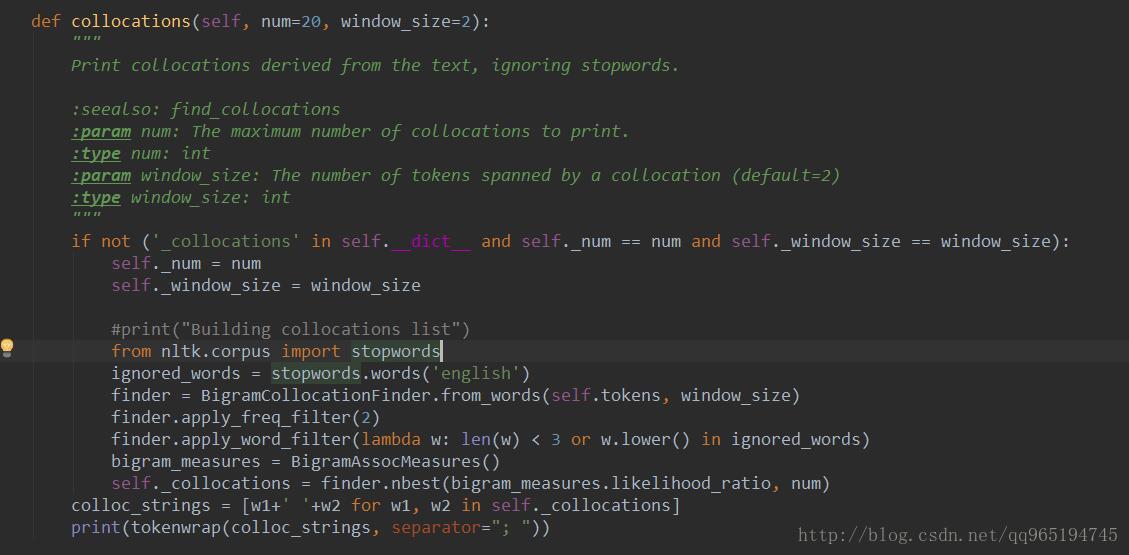
源码中可以很清楚的看到其实现用了比方法1更科学的分析方法,但是其并没有返回那个2gram集合出来,而是打印到了控制台上。
mongo方面
要求对文章标题精确检索到含有标签的,不重复的加上标签
解决方法
对于Text.collocations(),在百度获取控制台的输出无果之后,研究了两个英文文档
http://nltk.readthedocs.io/en/latest/api/nltk.html#
https://stackoverflow.com/questions/4128583/how-to-find-collocations-in-text-python
特别是第二篇的

这个骚操作令我眼前一亮,先执行一次Text.collocations(),然后Text类中就保存好了_collocations这个成员变量,还有这种操作,那个函数不返回值的方法解决了,虽然这并不面向对象
数据库方面
查阅官方文档
使用到了三种命令的组合
文本索引
标签不重复添加
updateMany
完整代码
from pymongo import MongoClient
import util
class ArticleTag():
def __init__(self) -> None:
print("#数据库连接启动")
super().__init__()
self.__client = MongoClient(util.MONGODB, 27017)
self.__db = self.__client.ccf
def __del__(self):
print("#数据库连接关闭")
self.__client.close()
def getTag(self, num=20, window_size=2):
print("#开始获取文章的标签")
data = self.__client.ccf.article.find() # 连接上mongo数据库
text = ""
for a in data: # 将标题拼接成一个文本
text += " " + a['title']
from nltk import word_tokenize
# 使用nltk Python 自然语言处理库
from nltk import Text
text = text.lower() # 将文本转换为小写方便去重
text = word_tokenize(text) # 分词
text = Text(text) # 构造成nltk文本
text.collocations(num=num, window_size=window_size)
list = text._collocations
return list
def label(self, tags: list):
print("#开始写入文章标签")
db = self.__db
for tag in tags:
# db.arryindex.updateMany({"$text": {"$search": "\"west\" "}}, {"$addToSet": {"tag": "kailin"}})
print(tag)
db.article.update_many({"$text": {"$search": "\"" + tag + "\""}}, {"$addToSet": {"tag": tag}})
测试结果
数据量是400多条文章标题

速度挺快的
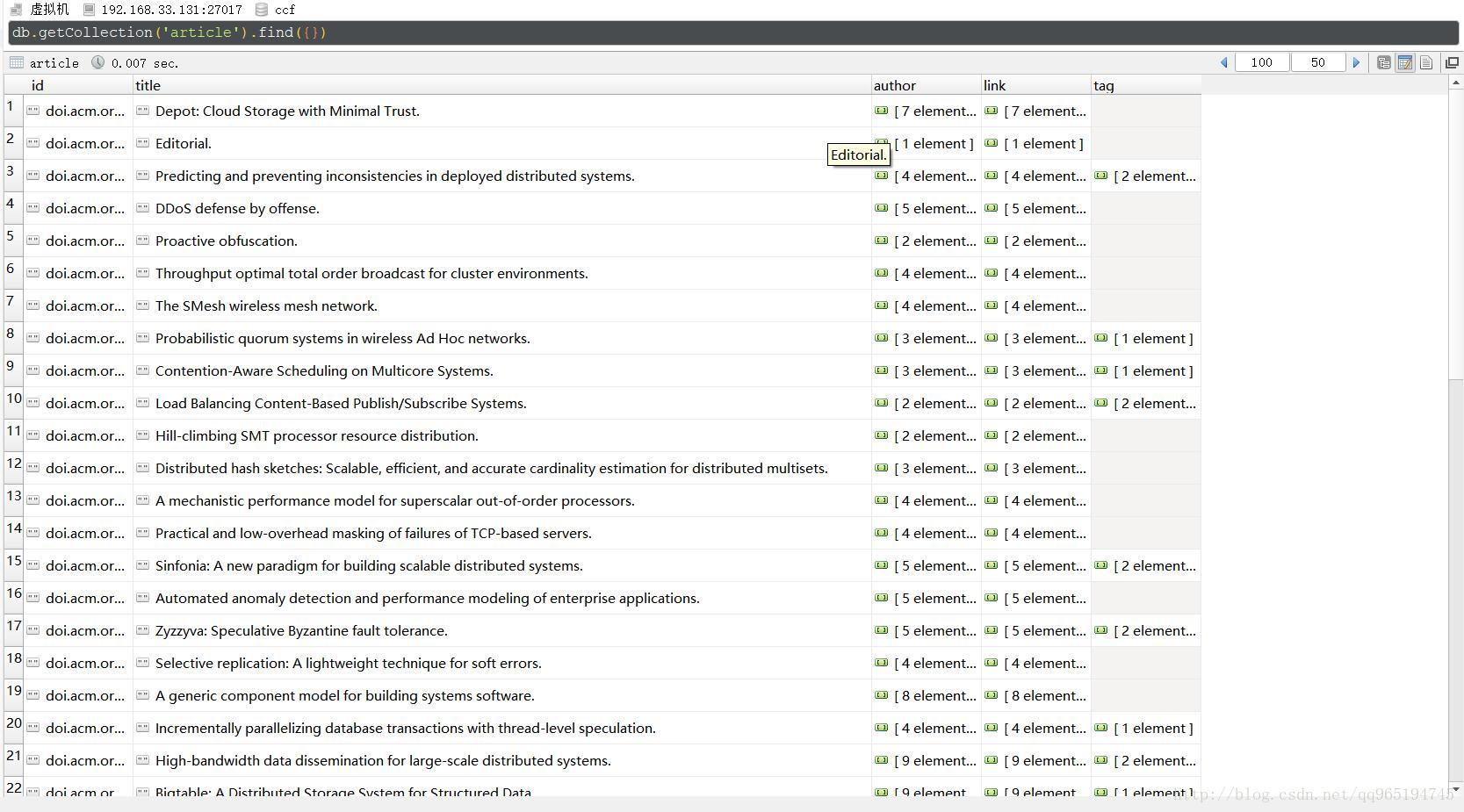
文章也相应的被打上了标签,有些文章因为没有其他文章跟其有相同的关键词,就没有没打上标签,在数据量足够大的情况下,没有标签的文章会少很多
扫描二维码关注公众号,回复:
1071017 查看本文章
