前言
昨天写完了二叉树、平衡二叉树、红黑树的一部分,今天把剩余的B-Tree、以及B+Tree整理出来。
1、B-Tree
1.1定义:
B-tree(多路搜索树,并不是二叉的)是一种常见的数据结构。使用B-tree结构可以显著减少定位记录时所经历的中间过程,从而加快存取速度 。 ----------百度百科
与二叉树相比,B-Tree利用多个分支(二叉树只有2个分支)节点,减少了获取记录时所经历的节点数,从而达到节省存取时间的目的。
B-Tree结构的数据可以让系统高效的找到数据所在的磁盘块。所以B-Tree一般使用在磁盘等外存储设备中的存储结构中。
1.2结构:
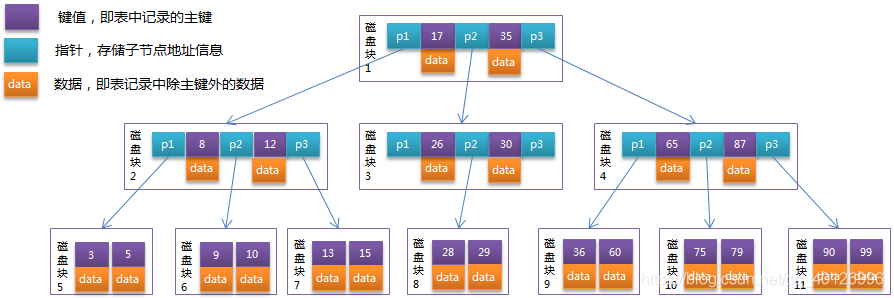
图片摘自:https://blog.csdn.net/hao65103940/article/details/89032538
1.3分析:
- 从上图的结构中我们可以看到在B-Tree中每个结点存储了
键值和数据两部分,同时在连接左右结点时通过指针进行连接。 - 并且我们可以看到在B-Tree中每个结点到叶子结点的
高度都是相同的,因此对于B-Tree来说,查询效率稳定的。 - 每个结点就是对应的键值,这样在获取数据时,只要找到键值就可以获取到对应的数据,不需要再进行定位数据的位置,加快了速度。
- 查询数据时先通过键值定位到所在的
磁盘块,在磁盘块中查询对应的数据。
1.4特点:
- 每个节点最多有m个孩子(m代表阶数)
- 除了根节点和叶子节点外,其它每个节点至少有Ceil(m/2)个孩子
- 若根节点不是叶子节点,则至少有2个孩子
- 所有叶子节点都在同一层,且不包含其它关键字信息
- 非叶子结点的关键字个数, ki(i=1,…n)为关键字,且关键字升序排序(
k[i]<k[i+1]) - 非叶子结点的关键字个数=指向儿子的指针个数-1
- 非叶子结点的指针:P[1], P[2], …,P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1],K[i])的子树
1.5操作:
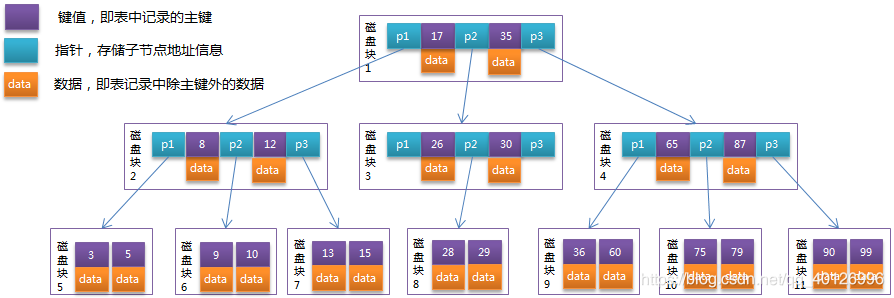
查询:在B-Tree中,进行查询操作时通过关键字就可以实现获取到对应的数据。
查询结构中的28:
- 首先在磁盘块1中进行查找,找到对应的磁盘指针P2,
- 通过P2进入磁盘块3,
- 在磁盘块3中进行判断找到P2,
- 通过P2找到磁盘块8,
- 在磁盘块8中查询关键字为28的数据。
新增:在B-Tree中进行新增结点时需要进行裂变。
新增结点18:
- 首先在磁盘块1中判断18对应的是P2
- 通过P2进入磁盘块3
- 在磁盘块中找到P1
- 在P1中新增叶子结点磁盘块12
- 将关键字18以及对应的数据存放在磁盘块12中
删除:删除操作和新增操作类似也可能发生裂变。
1.6总结:
- 插入或者删除元素都会导致节点发生裂变反应,如此才让B树能够始终保持多路平衡,这是B-Tree的一个优势:自平衡。
- B树主要应用于文件系统以及部分数据库索引,如MongoDB,大部分关系型数据库索引则是使用B+树实现。
- B-Tree所经过的结点数量要比平衡二叉树少很多,因此可以减少磁盘的IO,这对性能的提升很大。
2、B+Tree
2.1定义:
B+tree 是在 B- tree基础上的优化,是一种更适合存储索引的数据结构。
2.2结构:
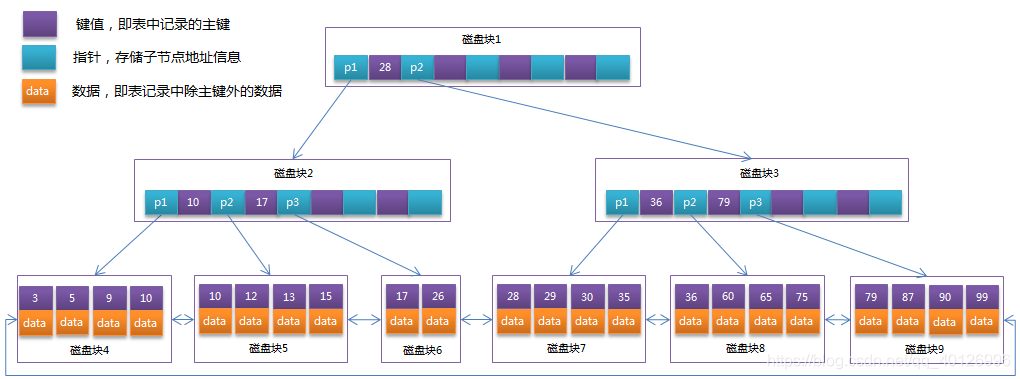
图片摘自:https://blog.csdn.net/hao65103940/article/details/89032538
2.3特点:
在B+Tree中,它的结构和B-Tree很像,但是它有如下自己的特征:
- 非叶子结点只存储自己的关键字信息
- 数据记录都存放在叶子节点中
- 所有叶子节点之间有一个链指针
2.4总结:
- 那为什么要将数据只存储在叶子结点呢,这是因为在磁盘中,
页是最小单位,每页的存储空间是有限的,因此如果data数据较大,就导致B-Tree的深度较大,因此当数据量很大时增多了磁盘的IO次数,影响查询效率。 - 为了解决这个问题,实现了B+Tree,在B+Tree中,所有数据记录节点都是按照
键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储key值信息,这样可以大大加大每个节点存储的key值数量,降低B+Tree的高度。 - 所有叶子节点形成一个有序链表(
链式环结构),便于范围查询。 - innodb存储引擎使用B+Tree做索引结构。
- 数据库中的B+Tree索引可以分为聚集索引(clustered index)和辅助索引(secondary index)。上面的B+Tree示例图在数据库中的实现即为聚集索引,聚集索引的B+Tree中的叶子节点存放的是整张表的行记录数据。
- 辅助索引与聚集索引的区别在于辅助索引的叶子节点并不包含行记录的全部数据,而是存储相应行数据的聚集索引键,即主键。当通过辅助索引来查询数据时,InnoDB存储引擎会遍历辅助索引找到主键,然后再通过主键在聚集索引中找到完整的行记录数据。
结语:
以上就是自己对B-Tree以及B+Tree的整理和总结,总结的不完善,也不够深度,是最简单的理解性总结,所以也是帮助自己加深对这部分知识的认识,以后了解的更多了也会继续记录。
我是走在学习路上、膜拜大佬的程序员!

