基本环境及软件:
| 软件版本 | 软件包 |
|---|---|
| centos-6.4 | |
| JDK-1.8 | jdk-8u191-linux-x64.tar.gz |
| hadoop-2.6.0 | hadoop-2.6.0-cdh5.7.0.tar.gz |
| scala-2.11.8 | scala-2.11.8.tgz |
| spark-2.2.0 | spark-2.2.0-bin-2.6.0-cdh5.7.0.tgz |
软件安装包官网下载地址 :http://archive-primary.cloudera.com/cdh5/cdh/5/
安装scala
1.将scala安装包scala-2.11.8.tgz上传到虚拟机的/usr/local/app目录下
2.对scala-2.11.8.tgz进行解压缩:
# tar -zxvf scala-2.11.8.tgz
3.配置scala相关的环境变量
# vim ~/.bashrc
#set sscala environment
export SCALA_HOME=/usr/local/app/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/bin
# source ~/.bashrc
4.查看scala是否安装成功:
# scala -version
出现下面的结果,表示安装成功


安装spark
注意:安装之前需要先安装Hadoop,请参考另一篇文章:https://blog.csdn.net/weixin_39689084/article/details/84548507
下载saprk有两种方式:
- 第一种方式:下载可执行tar包,直接解压
- 第二种方式:下载源码包,编译后解压
这儿用到的事第二种方式,具体怎么编译在这儿不做详细介绍,自行百度,下面介绍按章方法:
local模式搭建
1.将编译好的saprk安装包spark-2.2.0-bin-2.6.0-cdh5.7.0.tgz 上传到虚拟机的/usr/local/app目录下
2、解压缩spark包:
# tar -zxvf spark-2.2.0-bin-2.6.0-cdh5.7.0.tgz
3、重命名spark目录:
# mv spark-2.2.0-bin-2.6.0-cdh5.7.0/ spark-2.2.0
4、修改spark环境变量
# vim ~/.bashrc
#set spark environment
export SPARK_HOME=/usr/local/app/spark-2.2.0
export PATH=$PATH:$SPARK_HOME/bin
# source ~/.bashrc
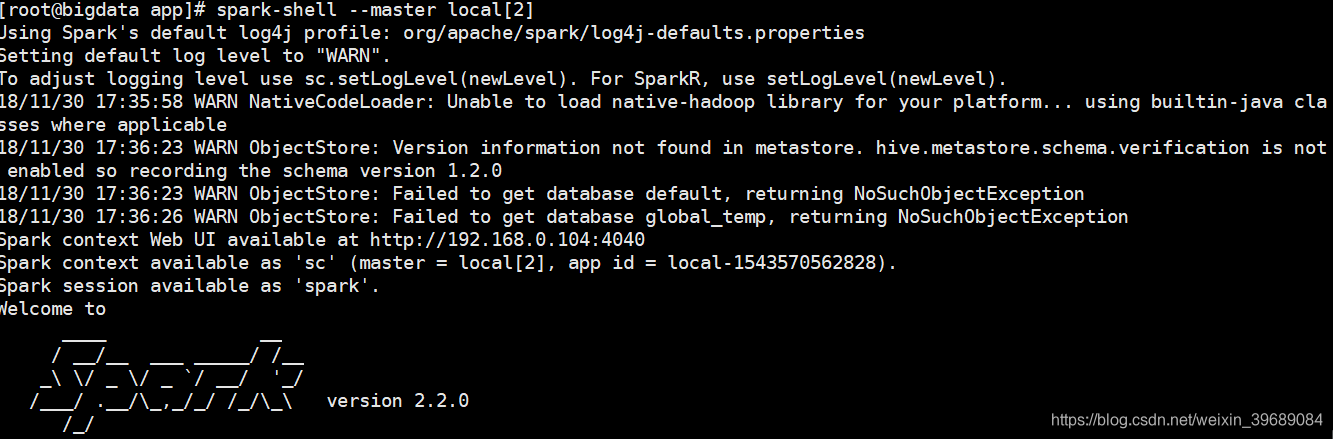
5.测试:
# spark-shell --master local[2]
standalone模式搭建
1、进入到/usr/local/app/spark-2.2.0/conf目录下
# cd /usr/local/app/spark-2.2.0/conf
# cp spark-env.sh.template spark-env.sh
# vi spark-env.sh
在spark-env.sh文件最后进行配置
SPARK_MASTER_HOST=hadoop000
SPARK_WORKER_CORES=2
SPARK_WORKER_MEMORY=2g
SPARK_WORKER_INSTANCES=1
配置解释
SPARK_MASTER_HOST, to bind the master to a different IP address or hostname
SPARK_WORKER_CORES, to set the number of cores to use on this machine
SPARK_WORKER_MEMORY, to set how much total memory workers have to give executors (e.g. 1000m, 2g)
SPARK_WORKER_INSTANCES, to set the number of worker processes per node
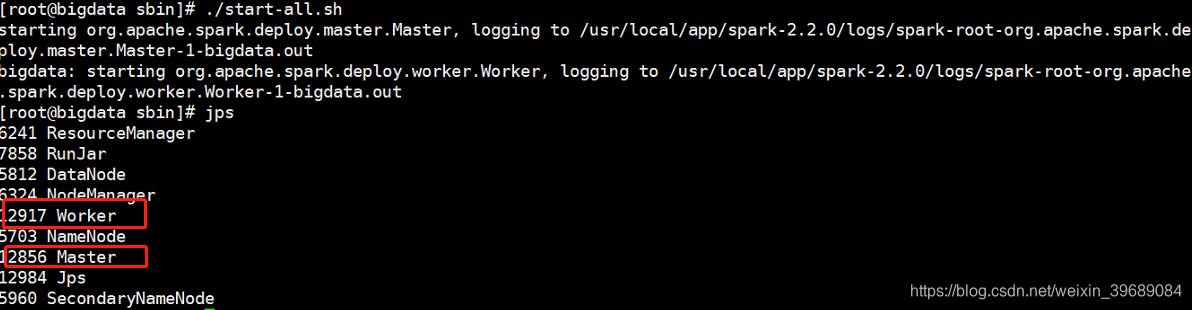
启动:
# cd /usr/local/app/spark-2.2.0/sbin
# ./start-all.sh
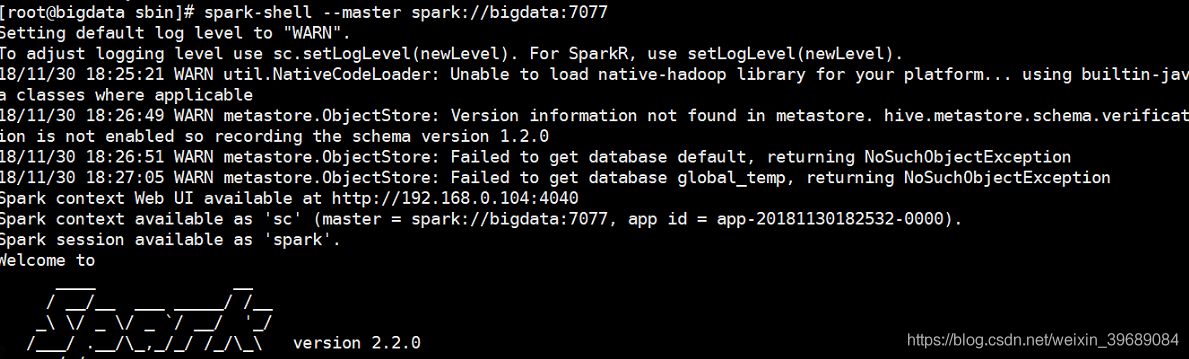
测试:
# spark-shell --master spark://bigdata:7077
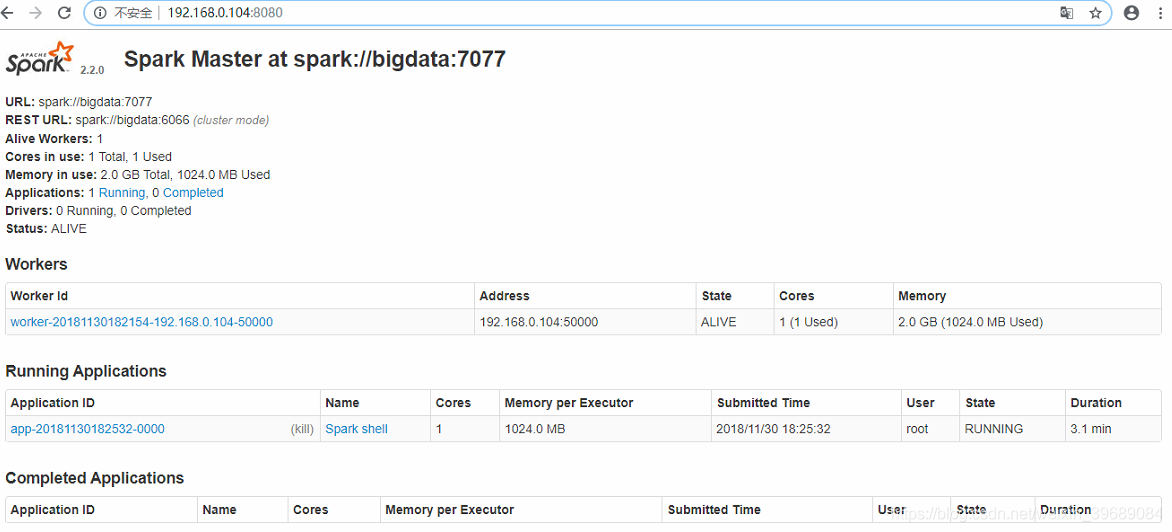
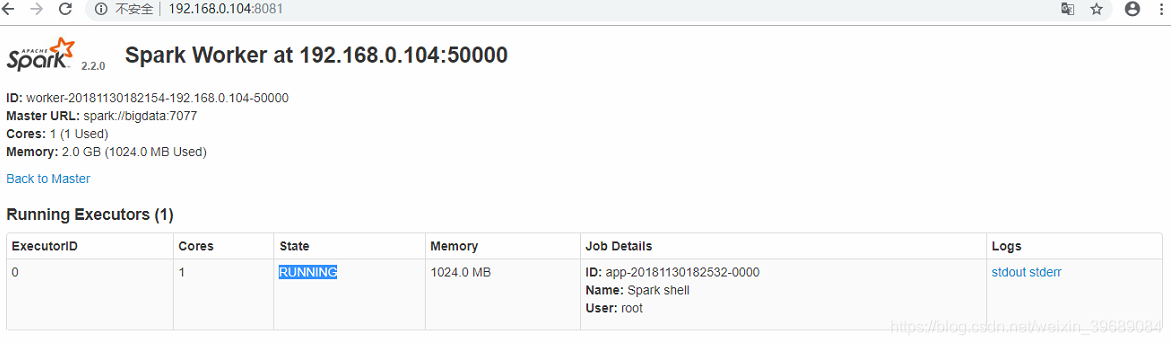
页面访问