导入库的几种形式
1)import 库名
使用函数时:库名.函数名() 或 库名.模块名.函数名()
import numpy
list = [1, 2, 3]
average = numpy.mean(list)
print(average)
2)import 库名 as 自定义
使用函数时:自定义.函数名() 或 自定义.模块名.函数名()
import numpy as np
list = [1, 2, 3]
average = np.mean(list)
print(average)
3)import 库名.模块名 as 自定义
使用函数时:自定义.函数名()
import matplotlib.pyplot as plt
plt.show()
3)from 库名 import 模块
使用函数时:模块名.函数名()
from sklearn import datasets
iris = datasets.load_iris()
1、numpy库
是一个数学库,主要用于数组和矩阵运算
1)生成一个2×2并且初值为0的矩阵:
import numpy
mat = numpy.zeros((2, 2))
print(mat)
效果:

2)求平均值
average = numpy.mean(iris.data, axis = 0):纵向平均值
3)求标准差
d = np.std(iris.data, axis = 0) #axis = 0表示求每一列的标准差
4)求欧式距离
详细:https://blog.csdn.net/Daycym/article/details/81178519
5)创建矩阵
数组的其他操作:https://blog.csdn.net/sinat_34474705/article/details/74458605?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
import numpy as np
arr = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
print(arr)
输出:

2、random库
1)随机函数
randint(l, r):随机生成 [l, r] 范围的整数
随机生成1—10(包括10)的整数:
import random
l = []
for i in range(10):
l.append(random.randint(1, 10))
print(l)
效果:
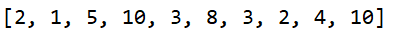
2)将列表元素打乱顺序
random.shuffle()
详细:https://blog.csdn.net/chichu261/article/details/83302736
3、sum函数
mat.sum(axis = 1):对矩阵的所有行求和
mat.sum(axis = 0):对矩阵的所有列求和
对混淆矩阵的行和列求和:
import numpy
import random
from sklearn.metrics import confusion_matrix
test = []
predict = []
#随机生成1000个实际类别和预测类别
for i in range(1000):
test.append(random.randint(0, 1))
predict.append(random.randint(0, 1))
#生成混淆矩阵
mat = confusion_matrix(test, predict)
print('混淆矩阵:')
print(mat)
row_sum = mat.sum(axis = 1)
col_sum = mat.sum(axis = 0)
print('每一行之和:\n', row_sum)
print('每一列之和:\n', col_sum)
效果:

4、sklearn库
sklearn是基于python的第三方库,包括机器学习的各个方面,分别用于完成数据的预处理、模型选择、分类任务、回归任务、聚类任务和降维任务。
1)sklearn中包含iris数据集
from sklearn import datasets
iris = datasets.load_iris()
for i in iris:
print(i)
iris数据集中有以下内容:

2)生成混淆矩阵
from sklearn.metrics import confusion_matrix
y_true = [0, 1, 0, 1]
y_pred = [1, 1, 1, 0]
mat = confusion_matrix(y_true, y_pred)
print(mat)
效果:

3)将原始数据按照比例分成训练集和测试集
train_test_split()
详细:https://www.cnblogs.com/Yanjy-OnlyOne/p/11288098.html
import numpy as np
from sklearn.model_selection import train_test_split
X = np.array([[1, 1], [2, 2], [3, 3], [4, 4]])
y = np.array([1, 2, 3, 4])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
#训练集
print('X_train:')
print(X_train)
print('y_train:')
print(y_train)
#测试集
print('X_test:')
print(X_test)
print('y_test:')
print(y_test)

可以看出,训练集的数据和真实类别是一一对应的
4)标准化函数
不会改变原来的数据集,返回值即为标准化后的数据集
from sklearn.preprocessing import StandardScaler
from sklearn import datasets
iris = datasets.load_iris()
iris.data = StandardScaler().fit_transform(iris.data)
print(iris.data)
5)KFold函数:将数据集等分,用于k折交叉验证数据集的等分
注意拆分的数据集需要是array类型,不能是list类型,否则会出错
from sklearn.model_selection import KFold
import numpy as np
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4])
kf = KFold(n_splits=4)
print(kf.get_n_splits(X))
print(kf)
KFold(n_splits=2, random_state=None, shuffle=False)
for train_index, test_index in kf.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]

5、pandas库
1)创建dataframe类型
详细:https://www.jianshu.com/p/8024ceef4fe2
2)scatter_matrix绘图可视化
详细:https://blog.csdn.net/wangxingfan316/article/details/80033557
random_state如果设为整数,在其他条件不变时,每次返回的数据都一样
如果不设,每次返回的结果都不一样
import pandas
from sklearn import datasets
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
iris = datasets.load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=0)
dataframe = pandas.DataFrame(X_train, columns = iris.feature_names)
pandas.plotting.scatter_matrix(dataframe, marker='o', c = y_train, hist_kwds = {'bins':20})
plt.show()
效果:

3)quantile函数:
求第1、2、3四分位
import pandas
l = [[1, 1, 1, 1],
[2, 2, 2, 2],
[3, 3, 3, 3],
[4, 4, 4, 4]]
df = pandas.DataFrame(l)
first = df.quantile(q=0.25, axis=0, numeric_only=True)
second = df.quantile(q=0.5, axis=0, numeric_only=True)
third = df.quantile(q=0.75, axis=0, numeric_only=True)
print(first)
print(second)
print(third)
输出:

4)读取csv文件为dataframe
链接:https://www.py.cn/jishu/jichu/12705.html
import pandas as pd
data = pd.read_csv("fileName.csv")
print(data)
6、保存列表到本地
链接:https://blog.csdn.net/rosefun96/article/details/78877452
mat = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
fileObject = open('mat.txt', 'w')
for i in mat:
for j in i:
fileObject.write(str(j))
fileObject.write(' ')
fileObject.write('\n')
fileObject.close()
7、csv库
详细:https://jingyan.baidu.com/article/851fbc37729bf33e1f15aba2.html
1)将iris.data样本集保存为本地的 iris_data.csv 文件
from sklearn import datasets
import csv
iris = datasets.load_iris()
with open('d://iris_data.csv', 'w', newline='') as t_file:
csv_writer = csv.writer(t_file)
for i in iris.data:
csv_writer.writerow(i)
2)读取csv文件为列表
转载自:https://blog.csdn.net/qq_44271529/article/details/90301114
from csv import reader
#得到一个data的二维列表,列表中的数据为str类型
data = list(reader(open('data.csv')))
#将列表中的数据转化为float类型
for i in range(len(data)):
for j in range(len(data[i])):
data[i][j] = float(data[i][j])
8、math库
数学库,有许多数学计算函数
math.sqrt函数:开平方
