一、集合与映射
1.1 什么是集合?
集合的概念其实过去也没有严格的定义,人们把一堆东西放到一起,就称之为集合了,我们经常有对某些特性相似的东西分堆处理的需要,因此集合这个概念就被发明出来了。
维基百科上定义,集合就是将数个对象归类而分成为一个或数个形态各异的大小整体。 一般来讲,集合是具有某种特性的事物的整体,或是一些确认对象的汇集,构成集合的事物或对象称作元素或是成员。集合的元素可以是任何事物,可以是人,可以是物,也可以是字母或数字等。
集合具有以下特性:
- 无序性:一个集合中,每个元素的地位都是相同的,元素之间是无序的。集合上可以定义序关系,定义了序关系后,元素之间就可以按照序关系排序。但就集合本身的特性而言,元素之间没有必然的序。
- 互异性:一个集合中,任何两个元素都认为是不相同的,即每个元素只能出现一次。有时需要对同一元素出现多次的情形进行刻画,可以使用多重集合,其中的元素允许出现多次。
- 确定性:给定一个集合,任给一个元素,该元素或者属于或者不属于该集合,二者必居其一,不允许有模棱两可的情况出现。
数学上为研究集合专门建构出一套数学理论 — 集合论,它包含了集合、元素和成员关系等最基本的数学概念。集合论在数学分析 、拓扑学 、抽象代数及离散数学中的基础地位没有争议,它是构成数学基础的四大支柱(集合论、模型论、证明论、可计算性理论 – 也称递归论)之一,由此可见集合这一概念的重要性。
在计算机科学中,集合可以看作是存储多个数据元素或对象的容器,前面介绍的数组、链表、散列表、二叉树等都可以看作是一个数据集合(对于包含重复元素的数据结构可以看作是多重集合),最宽泛的集合可以表示数据元素之间的归属关系(即该元素属于或不属于该集合)。
在软件工程中,我们对不同的数据集合可能会有序关系要求,针对有序关系要求的集合,可以称为有序集合Set;对于没有序关系要求的集合,可以称为无序集合Unordered_set。我们也可能需要对同一元素出现多次的情形进行刻画,针对同一元素允许出现多次的集合,可以称为多重集合Multiset。
1.2 什么是映射?
你平时是怎么学习认识新事物的呢?你观察过小孩子是怎么认知新事物的吗?我们经常会看到某个事物,听别人用几个语音来谈论它,当两者同时出现几次后,我们就会不自觉的在大脑中建立这个事物与这几个语音之间的映射关系。当再次看到该类事物时,就可以用这几个语音来表达它;当我们听到这几个语音时,也能理解它指代的是哪类事物。随着我们的学习,大脑中建立的这种映射关系越来越多,我们就可以使用越来越多的语音符号来理解或表达现实世界中的各种事物,这便是我们学习使用语言与这个世界互动的过程。
我们学习使用文字与这个世界、与他人交流的过程也跟语言类似,而且文字能借助纸张这类载体,将象征性符号与现实世界的事物(甚至我们虚构的概念)之间约定的映射关系记录并保存下来,让我们可以跨越地域与时间的限制,共享并丰富这套象征符号映射数据库。所以,我们对映射关系并不陌生,比如下面列举几个生活中常用的映射关系:

在数学上,我们可以把映射看作是集合与集合之间的一种对应关系。我们中学都学习过函数,函数实际上就是数的集合到数的集合之间的映射关系,自变量的集合称作定义域,因变量的集合称作值域。前面介绍hash table时,经hash function计算前后的数据(也即value与hash(value))就是一种hash映射关系。
计算机更擅长处理数字编号,我们的大脑更擅长处理概念词汇,因此我们经常需要通过某个关键词key来查询一组数据的信息value。比如我们上网只需要记住域名网址即可,计算机需要将域名网址经过DNS记录的映射关系,转换为IP地址后才继续进行网络寻址,为我们提供网络访问服务。
在计算机中使用映射的场景非常普遍,我们就把这种映射关系抽象为一个数据结构:键值对 pair<key, value>,将同类型的多个键值对pair放到一起,构成一个集合,就是一个更高抽象的数据结构:Map或Multimap。在Multimap中,存放映射关系pair的集合可以是多重集合Multiset,因此允许出现重复元素。
由于pair<key, value>也是一个集合,因此Map/Multimap跟Set/Multiset非常相似,二者最大的区别就是前者的元素是pair,后者的元素是value。既然Map/Multimap是pair<key, value>的集合,类比上面集合的特性与分类,映射也可分为有序映射、无序映射、多重映射,三者的区分跟集合分类一样,也是从是否定义序关系和是否满足互异性两个集合特性出发的。
二、集合容器怎么用?
从集合的定义可知,集合可以使用不同的底层数据结构来实现,我们可以将集合set抽象出一组接口:

我们先按无序集合来分析,使用不同底层数据结构实现的集合时间复杂度是怎样的?
| 无序集合底层数据结构 | 插入某元素复杂度 | 删除某元素复杂度 | 查询某元素复杂度 |
|---|---|---|---|
| 变长数组 | O(1) | O(n) | O(n) |
| 链表 | O(1) | O(n) | O(n) |
| 散列表 | O(1) | O(1) | O(1) |
| 平衡二叉树 | O(logn) | O(n) | O(n) |
在无序集合中,插入元素并不需要考虑插入位置,直接插入到就近的空位就可以了;查询或删除指定的元素,因数据集合是无序的,变长数组、链表、平衡二叉树都需要遍历整个数据集合,效率自然比较低,只有散列表可以达到常数级的时间复杂度。因此,无序集合更适合使用散列表或Hash Table作为其实现的底层数据结构。
再来看有序集合,使用不同底层数据结构实现的集合时间复杂度和空间复杂度是怎样的?
| 有序集合底层数据结构 | 插入某元素复杂度 | 删除某元素复杂度 | 查询某元素复杂度 | 空间复杂度 |
|---|---|---|---|---|
| 变长数组 | O(n) | O(n) | O(n) | O(1) |
| 链表 | O(n) | O(n) | O(n) | O(1) |
| 跳表 | O(logn) | O(logn) | O(logn) | O(n) |
| 平衡二叉查找树 (红黑树) |
O(logn) | O(logn) | O(logn) | O(1) |
因为散列表没法单独用于有序集合,首先被排除了,散列表配合双向链表倒是可以用于有序集合,这种组合数据结构比较复杂,暂不考虑。剩下两个比较高效的底层数据结构:跳表和红黑树,但跳表相比红黑树占用更多的内存地址空间。因此,有序集合更适合使用平衡二叉查找树或红黑树作为其实现的底层数据结构。
2.1 有序集合容器Set/Multiset
C++11为有序集合提供的STL容器是Set和Multiset,它们会根据特定的排序准则,自动将元素排序,都是使用红黑树作为其实现的底层数据结构。两者的不同之处在于Multiset使用多重集合,允许元素重复,而Set需要满足元素互异性,每个元素只能出现一次。

C++11 STL Set/Multiset的类模板定义如下(第一个参数T为元素类型,第二个参数Compare用来定义排序准则,默认以operator <对元素进行比较,第三个参数Allocator用来定义内存模型,默认采用由C++标准库提供的allocator):
// <set>
namespace std{
template <typename T,
typename Compare = less<T>,
typename Allocator = allocator<T>>
class set;
template <typename T,
typename Compare = less<T>,
typename Allocator = allocator<T>>
class multiset;
}
需要注意的是,假如自己定义排序准则Compare,则必须区分less与equal,不能使用operator <= 这样的排序准则(集合要求互异性)。两个元素如果没有任何一个小于另一个,则它们被视为重复,也即排序准则也可以被用来检查等价性(equivalence)。
Multiset的等价元素的次序是随机但稳定的,因此C++11保证插入和移除动作都会保存等价元素的相对次序。
前面分析过,Set和Multiset通常使用平衡二叉查找树或者红黑树实现,插入、删除、查找元素比较高效,且能实现自动排序。但是自动排序也给Set和Multiset带来一个限制:你不能直接改变元素值,因为这样会打乱原本正确的顺序。因此,要改变元素值,必须先删除旧元素,再插入新元素。

class set<>的构造函数与析构函数如下:

class set<>的比较、查找等非更易型操作:

Set元素比较动作是以“字典顺序”检查某个容器是否小于另一个容器,且只适用于类型相同的容器,也即元素和排序准则必须有相同的类型,否则编译期就会产生类型方面的错误。
class set<>的迭代器支持的相关操作:

Set容器不提供元素直接访问(自动排序的限制),虽然可通过迭代器访问集合元素,但从迭代器的角度看,所有元素都被视为常量,这可确保元素不会被改动以至于打乱原有顺序。
class set<>的赋值、交换、插入、移除等更易型操作:

C++11保证,multiset的insert()、emplace()、erase()成员函数都会保存等值元素间的相对次序,插入的元素会被放在“既有等值元素群”的末尾。由于multiset允许元素重复而set不允许,如果将某元素插入到set内,而该set已经内含同值元素,插入动作将会失败,所以set的返回类型是以pair组织起来的两个值:pair结构中的second成员表示插入是否成功,first成员表示现存同值元素的位置(如插入成功则表示新插入元素的位置)。
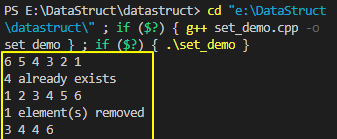
下面给出一个操作set/multiset的示例程序供参考:
// datastruct\set_demo.cpp
#include <iostream>
#include <set>
#include <iterator>
#include <algorithm>
int main(void)
{
std::set<int, std::greater<int>> set1;
// insert elements in random order
set1.insert({4, 3, 5, 1, 6, 2});
set1.insert(5);
// print all elements
for(int elem : set1)
std::cout << elem << ' ';
std::cout << std::endl;
// insert 4 again and process return value
auto status = set1.insert(4);
if(status.second)
std::cout << "4 inserted as element " << std::distance(set1.begin(), status.first) + 1 << std::endl;
else
std::cout << "4 already exists" << std::endl;
// assign elements to another set with ascending order
std::multiset<int> set2(set1.cbegin(), set1.cend());
// print all elements of the copy using stream iterators
std::copy(set2.cbegin(), set2.cend(), std::ostream_iterator<int>(std::cout, " "));
std::cout << std::endl;
// insert elements
set2.insert(4);
// remove all elements up to element with value 3
set2.erase(set2.begin(), set2.find(3));
// remove all elements with value 5
int num = set2.erase(5);
std::cout << num << " element(s) removed" << std::endl;
// print all elements
std::copy(set2.cbegin(), set2.cend(), std::ostream_iterator<int>(std::cout, " "));
std::cout << std::endl;
return 0;
}
上面set的示例代码运行结果如下(需要注意编译器是否支持C++11,比如g++在4.7以上版本才支持,添加-std=c++11即可):
2.2 无序集合容器Unordered Set/Multiset
C++11为无序集合提供的STL容器是Unordered Set/Multiset,为了能提供尽可能高的访问效率,都使用hash table作为其实现的底层数据结构。两者的不同之处在于Multiset使用多重集合,允许元素重复,而Set需要满足元素互异性,每个元素只能出现一次。Unordered Set/Multiset的内部结构如下图所示:

对于每个将被存放的value,hash function会把它映射到hash table内某个bucket(slot)中,每个bucket管理一个单向linked list,内含所有“会造成hash function产生相同数值”的元素。
C++11 STL Unordered Set/Multiset的类模板定义如下(第一个参数T为元素类型;第二个参数Hash用来定义hash function,如未定义则使用默认的hash<>;第三个参数EqPred用来定义等价准则,这是一个判断式predicate,用来判断两个元素值是否相等,如未指定则使用默认的equal_to<>;第四个参数Allocator用来定义内存模型,默认采用由C++标准库提供的allocator):
// <unordered_set>
namespace std{
template <typename T,
typename Hash = hash<T>,
typename EqPred = equal_to<T>,
typename Allocator = allocator<T>>
class unordered_set;
template <typename T,
typename Hash = hash<T>,
typename EqPred = equal_to<T>,
typename Allocator = allocator<T>>
class unordered_multiset;
}
概念上,Unordered Set/Multiset容器以一种随意顺序包含你插入进去的所有元素,当你需要操作容器内的元素时,只能以随机的次序访问它们,所以相比有序集合Set/Multiset容器,这里不需要排序准则。
class unordered_set<>的构造函数与析构函数如下:

无序集合构造函数中,影响Unordered Set/Multiset容器的行为主要有下面三个:Hash函数,等价准则,Bucket的最初数量等。需要注意的是,你不可以在构造函数中指定hash table的最大负载系数,如果需要指定最大负载系数,可以在构建后通过调用成员函数c.max_load_factor(float val)指定。通常0.7 ~ 0.8是速度和内存消耗量之间一个不错的折中,但C++默认的最大负载系数是1.0。
C++为无序容器提供了一些查询、影响hash内部布局的操作函数如下:

除了max_load_factor(),成员函数rehash()和reserve()也很重要,它们提供rehash一个unordered容器,也即改变bucket个数的功能。
class unordered_set<>的比较、查找等非更易型操作:

无序容器不提供比较大小的操作,只提供判断两个元素是否等价的操作。
class unordered_set<>的迭代器支持的相关操作:

跟有序集合对比你会发现,有序集合使用的是双向迭代器,无序集合使用的是前向迭代器。
class unordered_set<>的赋值、交换、插入、移除等更易型操作:

Unordered Set/Multiset容器使用链表法避免散列冲突,hash table中的每个bucket管理一个单向链表,C++也为每个bucket提供了一组接口,便于访问或管理其指向的单向链表,bucket接口支持的操作如下:

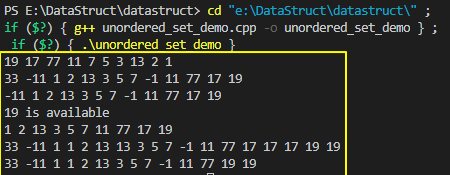
下面给出一个操作unordered_set/multiset的示例程序供参考:
// datastruct\unordered_set_demo.cpp
#include <iostream>
#include <unordered_set>
template <typename T>
void printElements(const T& coll)
{
for(auto iter = coll.begin(); iter != coll.end(); ++iter)
{
const auto& elem = *iter;
std::cout << elem << " ";
}
std::cout << std::endl;
}
int main(void)
{
// create and initialize unordered set
std::unordered_set<int> uset1 = {1, 2, 3, 5, 7, 11, 13, 17, 19, 77};
// print all elments
printElements(uset1);
// insert some additional elements, might cause rehash
uset1.insert({-1, 17, 33, -11, 17, 19, 1, 13});
printElements(uset1);
// remove element with specific value
uset1.erase(33);
printElements(uset1);
// check if value 19 is in the set
if(uset1.find(19) != uset1.end())
std::cout << "19 is available" << std::endl;
// remove all negative values
std::unordered_set<int>::iterator pos;
for(pos = uset1.begin(); pos != uset1.end(); ){
if(*pos < 0)
pos = uset1.erase(pos);
else
pos++;
}
printElements(uset1);
// assign elements to another unordered_multiset
std::unordered_multiset<int> uset2(uset1.cbegin(), uset1.cend());
// insert some additional elements, might cause rehash
uset2.insert({-1, 17, 33, -11, 17, 19, 1, 13});
printElements(uset2);
// remove all elements with specific value
uset2.erase(17);
// remove one of the elements with specific value
auto pos2 = uset2.find(13);
if(pos2 != uset2.end())
uset2.erase(pos2);
printElements(uset2);
return 0;
}
上面unordered_set/multiset的示例代码运行结果如下(需要注意编译器是否支持C++11,比如g++在4.7以上版本才支持,添加-std=c++11即可):
三、映射容器怎么用?
3.1 如何存储映射关系?
前面介绍了C++使用键值对pair<key, value>来存储映射关系,class pair可以将两个value视为一个单元,下面先看看C++11 class pair类模板的定义(第一个参数T1为第一个元素的类型,第二个参数T2为第二个元素的类型):
// <utility>
namespace std{
template <typename T1, typename T2>
struct pair{
//member
T1 first;
T2 second;
...
};
}
class pair<>的构造、赋值、比较等操作函数如下:

一般class pair<key, value>只存储key和value两个元素之间的映射关系,如果我们有更多维度的数据,想存储一对多或多对一的映射关系,比如key映射为value1、value2、value3……,C++还引入了tuple来扩展pair的概念,可以将任意数量的元素视为一个单元,且其中的每个类型都可以被指定或由编译器推导。
class tuple类模板定义如下(typename…表示可以接受任何数量的参数):
// <tuple>
namespace std{
template <typename... Types>
class tuple;
}
class tuple<>的构造、赋值、比较等操作函数如下:

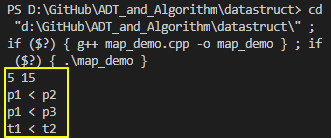
下面给出一个操作pair和tuple的示例程序供参考:
#include <iostream>
#include <utility>
#include <tuple>
#include <string>
int main(void)
{
// create and initialize pair
std::pair<int, int> p1(5, 10);
auto p3 = std::make_pair(10, 5);
// assign to another pair
auto p2 = p1;
p2.second = 15;
// access pair member
std::cout << p2.first << " " << p2.second << std::endl;
// compare two pair
if(p1 < p2)
std::cout << "p1 < p2" << std::endl;
if(p1 < p3)
std::cout << "p1 < p3" << std::endl;
// create and initialize tuple
std::tuple<int, float, std::string> t1(75, 12.12, "are you ok");
auto t2 = std::make_tuple(75, 12.12, "are you ok?");
// compare two tuple
if(t1 < t2)
std::cout << "t1 < t2" << std::endl;
else
std::cout << "t1 >= t2" << std::endl;
return 0;
}
上面pair和tuple的示例代码运行结果如下(需要注意编译器是否支持C++11,比如g++在4.7以上版本才支持,添加-std=c++11即可):
映射map中解决了存储映射关系pair<key, value>的问题,将pair看作是一个单元,map就相当于是pair的集合。前面介绍的集合set支持的接口,映射map基本也都支持,而且相比集合set,映射map还提供了访问、设置键值关系的接口,我们可以将映射map抽象出一组接口如下:

虽然映射map也可以由不同的底层数据结构来实现,因为映射map本质上是键值对pair的集合,使用不同底层数据结构实现的集合时间和空间复杂度对比结果,依然适用于映射map。也即,无序映射更适合使用散列表或Hash Table作为其实现的底层数据结构,有序映射更适合使用平衡二叉查找树或红黑树作为其实现的底层数据结构。
3.2 有序映射容器Map/Multimap
C++11为有序映射提供的STL容器是Map和Multimap,它们将pair<key, value>当作元素进行管理,可根据key的排序准则,自动将元素排序,都是使用红黑树作为其实现的底层数据结构。两者的不同之处在于Multimap使用多重集合,允许元素重复,而map需要满足元素互异性,每个元素只能出现一次。

C++11 STL Map和Multimap的类模板定义如下(第一个参数Key为元素的key类型,第二个参数T为元素的value类型;第三个参数Compare用来定义排序准则,元素的次序由它们的key决定,与value无关;第四个参数Allocator用来定义内存模型,默认采用由C++标准库提供的allocator):
// <map>
namespace std{
template <typename Key, typename T,
typename Compare = less<Key>,
typename Allocator = allocator<pair<const Key, T>>>
class map;
template <typename Key, typename T,
typename Compare = less<Key>,
typename Allocator = allocator<pair<const Key, T>>>
class multimap;
}
跟有序集合一样,假如自己定义排序准则Compare,则必须区分less与equal,不能使用operator <= 这样的排序准则(集合要求互异性)。两个元素如果没有任何一个小于另一个,则它们被视为重复,也即排序准则也可以被用来检查等价性(equivalence)。Multimap的等价元素的次序是随机但稳定的,因此C++11保证插入和移除动作都会保存等价元素的相对次序。
同样的,Map和Multimap通常使用平衡二叉查找树或者红黑树实现,插入、删除、查找元素比较高效,且能按key实现自动排序。但是自动排序也给Map和Multimap带来一个限制:你不能直接改变元素值,因为这样会打乱原本正确的顺序。因此,要改变元素值,必须先删除旧元素,再插入新元素。

class map<>的构造函数与析构函数如下:

class map<>的比较、查找等非更易型操作:

Map元素比较动作是以“字典顺序”检查某个容器是否小于另一个容器,且只适用于类型相同的容器,也即两个容器的key、value和排序准都必须有相同的类型,否则编译期就会产生类型方面的错误。
Map容器的查找操作,传入的参数都是key,也即映射都把key作为pair集合的索引凭证。由于Map容器是根据key来访问value的,有点类似于数组通过下标来访问元素值,所以Map容器提供了类似数组下标访问元素值的操作接口,可以通过c.[key]和c.at(key)来访问Map容器中的value值。
class map<>的迭代器支持的相关操作跟class set<>一样,这里就不赘述了。跟Set容器一样,Map容器不提供元素直接访问(自动排序的限制),虽然可通过迭代器访问集合元素,但从迭代器的角度看,所有元素都被视为常量,这可确保元素不会被改动以至于打乱原有顺序。
class map<>的赋值、交换、插入、移除等更易型操作:

对于multimap,C++11也保证的insert()、emplace()、erase()成员函数都会保存等值元素间的相对次序,插入的元素会被放在“既有等值元素群”的末尾。
插入一个pair<const key, value>时,你需要注意,在map和multimap内部,key被视为常量,你要么得提供正确类型,要么得提供隐式或显式类型转换。自C++11起(在C++11之前最方便的办法是运用make_pair()函数构建pair对象),插入元素的最方便做法就是把它们以初值列的形式传进去,其中第一笔数据是key,第二笔数据是value。
下面给出一个操作map/multimap的示例程序供参考:
// datastruct\map_demo.cpp
#include <iostream>
#include <map>
#include <string>
#include <iomanip>
int main(void)
{
// create map as associative array
std::map<std::string, float> stocks;
stocks["BMW"] = 834.12;
stocks["Daimler"] = 819.32;
stocks["Siemens"] = 842.69;
// print all elements
std::cout << std::left;
for(auto pos = stocks.begin(); pos != stocks.end(); ++pos)
std::cout << "stock: " << std::setw(12) << pos->first
<< "price: " << pos->second << std::endl;
std::cout << std::endl;
// assign and erase element
stocks["Benz"] = stocks["Daimler"];
stocks.erase("Daimler");
// print all elements
for(auto pos = stocks.begin(); pos != stocks.end(); ++pos)
std::cout << "stock: " << std::setw(12) << pos->first
<< "price: " << pos->second << std::endl;
std::cout << std::endl;
// search an element with key "BMW"
auto pos = stocks.find("BMW");
if(pos != stocks.end())
std::cout << "stock: " << std::setw(12) << pos->first
<< "price: " << pos->second << std::endl;
std::cout << std::endl;
// create multimap as dictionary
std::multimap<std::string, std::string> dicts;
// insert some elements in random order
dicts.insert({{"day", "Tag"}, {"smart", "elegant"}, {"car", "Auto"},
{"smart", "klug"}, {"car", "Tag"}});
// print all elements
std::cout << ' ' << std::setw(18) << "english " << "german " << std::endl;
std::cout << std::setfill('-') << std::setw(32) << "" << std::setfill(' ') << std::endl;
for(const auto& elem : dicts)
std::cout << ' ' << std::setw(18) << elem.first << elem.second << std::endl;
std::cout << std::endl;
// print all values for key "smart"
std::string word("smart");
std::cout << word << ": " << std::endl;
for(auto pos = dicts.lower_bound(word); pos != dicts.upper_bound(word); ++pos)
std::cout << " " << pos->second << std::endl;
std::cout << std::endl;
// print all keys for values "Tag"
word = ("Tag");
std::cout << word << ": " << std::endl;
for(const auto& elem : dicts){
if(elem.second == word)
std::cout << " " << elem.first << std::endl;
}
std::cout << std::endl;
return 0;
}
上面map的示例代码运行结果如下(需要注意编译器是否支持C++11,比如g++在4.7以上版本才支持,添加-std=c++11即可):

3.3 无序映射容器Unordered Map/Multimap
C++11为无序映射提供的STL容器是Unordered Map/Multimap,为了能提供尽可能高的访问效率,都使用hash table作为其实现的底层数据结构。两者的不同之处在于Multimap使用多重集合,允许元素重复,而Map需要满足元素互异性,每个元素只能出现一次。
由于Map容器中存放的元素是pair<key, value>, 其中key被用来作为“存放和查找某特定元素”的依据,因此需要经过hash function计算的对象也是key。Unordered Map/Multimap的内部结构如下图所示:

对于每个将被存放的pair<key, value>,hash function会把它映射到hash table内某个bucket(slot)中,每个bucket管理一个单向linked list,内含所有“会造成hash(key)产生相同数值”的元素,bucket管理的单向链表中的元素为pair<key, value>。
C++11 STL Unordered Map/Multimap的类模板定义如下(第一个参数Key为元素的key类型, 第二个元素T为元素的value类型;第三个参数Hash用来定义hash function,如未定义则使用默认的hash<>;第四个参数EqPred用来定义等价准则,这是一个判断式predicate,用来判断两个元素的key值是否相等,如未指定则使用默认的equal_to<>;第五个参数Allocator用来定义内存模型,默认采用由C++标准库提供的allocator):
// <unordered_map>
namespace std{
template <typename Key, typename T,
typename Hash = hash<Key>,
typename EqPred = equal_to<Key>,
typename Allocator = allocator<pair<const Key, T>>>
class unordered_map;
template <typename Key, typename T,
typename Hash = hash<Key>,
typename EqPred = equal_to<Key>,
typename Allocator = allocator<pair<const Key, T>>>
class unordered_multimap;
}
概念上,Unordered Map/Multimap容器以一种随意顺序包含你插入进去的所有元素,当你需要操作容器内的元素时,只能以随机的次序访问它们,所以相比有序映射Map/Multimap容器,这里不需要排序准则。
class unordered_map<>的构造函数与析构函数如下:

无序映射构造函数中,影响Unordered Map/Multimap容器的行为主要有下面三个:Hash函数,等价准则,Bucket的最初数量等。最大负载系数的设置跟无序集合Unordered Set/Multiset一样,C++为无序映射提供了一些查询、影响hash内部布局的操作函数也跟无序集合一样,这里就不再赘述了。
class unordered_map<>的比较、查找等非更易型操作:

与无序集合一样,无序映射也不提供比较大小的操作,只提供判断两个元素是否等价的操作。跟有序映射一样,无序映射也提供类似数组通过下标访问的操作,即通过元素的key值访问元素的value值。
class unordered_map<>的迭代器支持的操作也跟无序集合class unordered_set<>的迭代器一样,使用的是前向迭代器,这里就不再赘述了。
class unordered_map<>的赋值、交换、插入、移除等更易型操作:

Unordered Map/Multimap容器也使用链表法避免散列冲突,hash table中的每个bucket管理一个单向链表,单向链表中的每个元素都是一个键值对pair<key, value>,C++为每个bucket提供的接口操作跟无序集合一样,这里就不再赘述了。
下面给出一个操作unordered_map/multimap的示例程序供参考:
// datastruct\unordered_map_demo.cpp
#include <iostream>
#include <unordered_map>
#include <string>
#include <utility>
#include <iomanip>
template <typename T>
void printUnorderedCell(const T& cell)
{
// basic hash layout data
std::cout << "size: " << cell.size() << std::endl;
std::cout << "buckets: " << cell.bucket_count() << std::endl;
std::cout << "load factor: " << cell.load_factor() << std::endl;
std::cout << "max load factor: " << cell.max_load_factor() << std::endl;
// elements per bucket
std::cout << "data: " << std::endl;
for(auto idx = 0; idx != cell.bucket_count(); ++idx){
std::cout << " b[" << std::setw(2) << idx << "]: ";
for(auto pos = cell.begin(idx); pos != cell.end(idx); ++pos)
std::cout << "[" << pos->first << ", " << pos->second << "] ";
std::cout << std::endl;
}
std::cout << std::endl;
}
int main(void)
{
// create unordered_map as associative array
std::unordered_map<std::string, float> stocks;
stocks["BMW"] = 834.12;
stocks["Daimler"] = 819.32;
stocks["Siemens"] = 842.69;
stocks["VM"] = 413.52;
// print all elements
printUnorderedCell(stocks);
// modify max load factor, might cause rehash
stocks.max_load_factor(0.7);
stocks["Benz"] = stocks["Daimler"];
printUnorderedCell(stocks);
// create and initialize an unordered multimap as dictionary
std::unordered_multimap<std::string, std::string> dicts = {
{"day", "Tag"}, {"smart", "elegant"}, {"car", "Auto"},
{"smart", "klug"}, {"car", "Tag"}, {"clever", "raffiniert"}
};
printUnorderedCell(dicts);
return 0;
}
上面unordered_map/multimap的示例代码运行结果如下(需要注意编译器是否支持C++11,比如g++在4.7以上版本才支持,添加-std=c++11即可):

本章数据结构实现源码下载地址:https://github.com/StreamAI/ADT-and-Algorithm-in-C/tree/master/datastruct
