一、关于微服务调用链
参与过大型微服务项目架构设计(以SpringCloud、SpringCloudAlibaba为代表)或者项目开发的小伙伴们应该都知道,在一个完成的微服务项目中,一个大型的项目被拆分成中多个子服务,服务与服务之间都是独立存在部署的,当某个或者某几个服务间发生交互时,应该就是服务之间的调用,这里我假设有Service-A、Service-B、Service-C三个服务,存在以下调用关系:Service-A调用Service-B服务,Service-B服务调用Service-C服务,当然现实项目中肯定不止这么简单的一个调用链,而且还会存在很多个这种类似的调用服务关系,当调用关系成千上百的个时候,一旦服务与服务之间调用出现了异常,就很难排除是哪个服务出了问题,出了什么问题,那么Spring Cloud Sleuth服务追踪就是为解决这个问题而生的,常见的搭配由Spring Cloud Sleuth+Zipkin 组合起来使用。
二、什么是Zipkin
Zipkin是一款开源的分布式实时数据追踪系统(Distributed Tracking System),基于Google Dapper的论文设计而来,由 Twitter公司开发贡献。其主要功能是聚集来自各个异构系统的实时监控数据。分布式跟踪系统还有其他比较成熟的实现,例如:Naver的Pinpoint、Apache的HTrace、阿里的鹰眼Tracing、京东的Hydra、新浪的Watchman,美团点评的CAT,skywalking等。
三、Zipkin简要架构原理
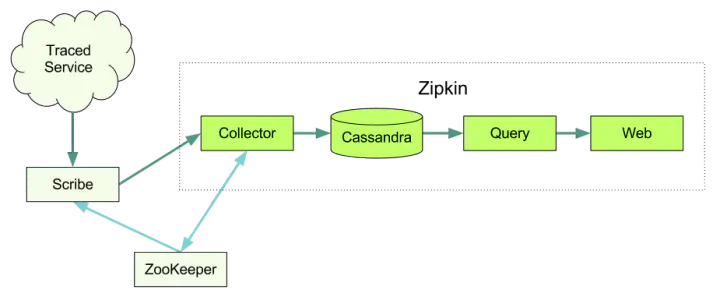
Zipkin 主要由四部分构成:
- 收集器: 负责将各系统报告过来的追踪数据进行接收,
zipkin默认提供的是以http方式将数据收集到内存中,同时也提供了中间件kafka和rabbitmq来收集数据,引入中间件也主要是为了在zipkin-client向zipkin-server传输数据时解决流量消峰问题; - 数据存储: zipkin默认会将链路请求信息保存到内存中,同时官方提供了
zipkin可以将数据持久化到Cassandra、Elasticsearch、MySQL中,一来是解决服务重启信息会丢失情况,二来是解决都存储到内存太浪费资源。 - 查询 : 用来向其他服务提供数据查询的能力,以及调用关系、请求耗时等服务详细信息的查询
- Web 界面:
Web服务是官方默认提供的一个图形用户界面,提供给使用者一个可视化界面来操作、展示数据。
通过上面介绍的Zipkin四部分组成,相比对Zipkin是个啥玩意有了了解,这里友情提示下,在生产换机时,建议将Zipkin 追踪的链路数据进行持久化到Elasticsearch,如果数据量小,存到Mysql中也是可以的。
Zipkin客户端和Zipkin服务端
Spring Cloud Sleuth有一个Sampler策略,可以通过这个实现类来控制采样算法。通过采样到某些请求的的耗时情况,同时结合Zipkin客户端,将追踪到的服务链路信息上传到Zipkin服务端,在Zipkin服务端通过Zipkin的可视化UI界面查询服务追踪到的服务链路数据,具体操作看后面步骤。
四、Spring Cloud Sleuth+ Zipkin可以做什么
Spring Cloud Sleuth 为服务之间调用提供链路追踪。通过 Sleuth 可以很清楚的了解到一个服务请求经过了哪些服务,每个服务处理花费了多长。从而让我们可以很方便的理清各微服务间的调用关系、优化比较耗时的服务、排查一下出故障的服务。
耗时分析: 通过 Sleuth 可以很方便的了解到每个采样请求的耗时,从而分析出哪些服务调用比较耗时;
可视化错误: 对于程序未捕捉的异常,可以通过集成 Zipkin 服务界面上看到;
链路优化: 对于调用比较频繁的服务,可以针对这些服务实施一些优化措施。 Spring Cloud Sleuth 可以结合 Zipkin,将信息发送到 Zipkin,利用 Zipkin 的存储来存储信息,利用 Zipkin UI 来展示数据。
五、Spring Cloud Sleuth基本术语(摘自官网)
Spring Cloud Sleuth采用的是Google的开源项目Dapper的专业术语。
- Span: 基本工作单元,发送一个远程调度任务 就会产生一个Span,Span是一个64位ID唯一标识的,Trace是用另一个64位ID唯一标识的,Span还有其他数据信息,比如摘要、时间戳事件、Span的ID、以及进度ID。
- Trace: 一系列Span组成的一个树状结构。请求一个微服务系统的API接口,这个API接口,需要调用多个微服务,调用每个微服务都会产生一个新的Span,所有由这个请求产生的Span组成了这个Trace。
- Annotation: 用来及时记录一个事件的,一些核心注解用来定义一个请求的开始和结束 。这些注解包括以下:
- cs - Client Sent : 表示客户端发送一个请求,这个注解描述了这个Span的开始
- sr - Server Received : 表示服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网络传输的时间。
- ss - Server Sent (服务端发送响应): 表示该注解表明请求处理的完成(当请求返回客户端),如果ss的时间戳减去sr时间戳,就可以得到服务器请求的时间。
- cr - Client Received (客户端接收响应): 表示此时Span的结束,如果cr的时间戳减去cs时间戳便可以得到整个请求所消耗的时间。

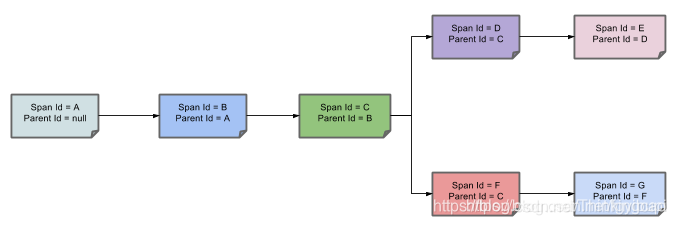
上图中每个颜色的表明一个span(总计7个spans,从A到G),每个span有类似的信息
Trace Id = X
Span Id = D
Client Sent
该span表示span的Trance Id是X,Span Id是D,同时它发送一个Client Sent事件
下图展示了span的父子关系:
六、准备工作
1. zipkin-server安装启动
注意: 在搭建Spring Cloud Sleuth+Zipkin服务链路追踪之前,提一下一个版本问题,在SpringBoot2.0之前的版本,Zipkin服务端,也就是可视化界面,需要自己新建项目引入依赖搭建,如同搭建eureka注册中一样;但是在SpringBoot2.0之后的版本,官方提供好了jar包(Zipkin服务端),直接下载使用java -jar xxx.jar即可运行,不需要再手动搭建了。
- 下载zipkin-server: https://mvnrepository.com/artifact/io.zipkin.java/zipkin-server
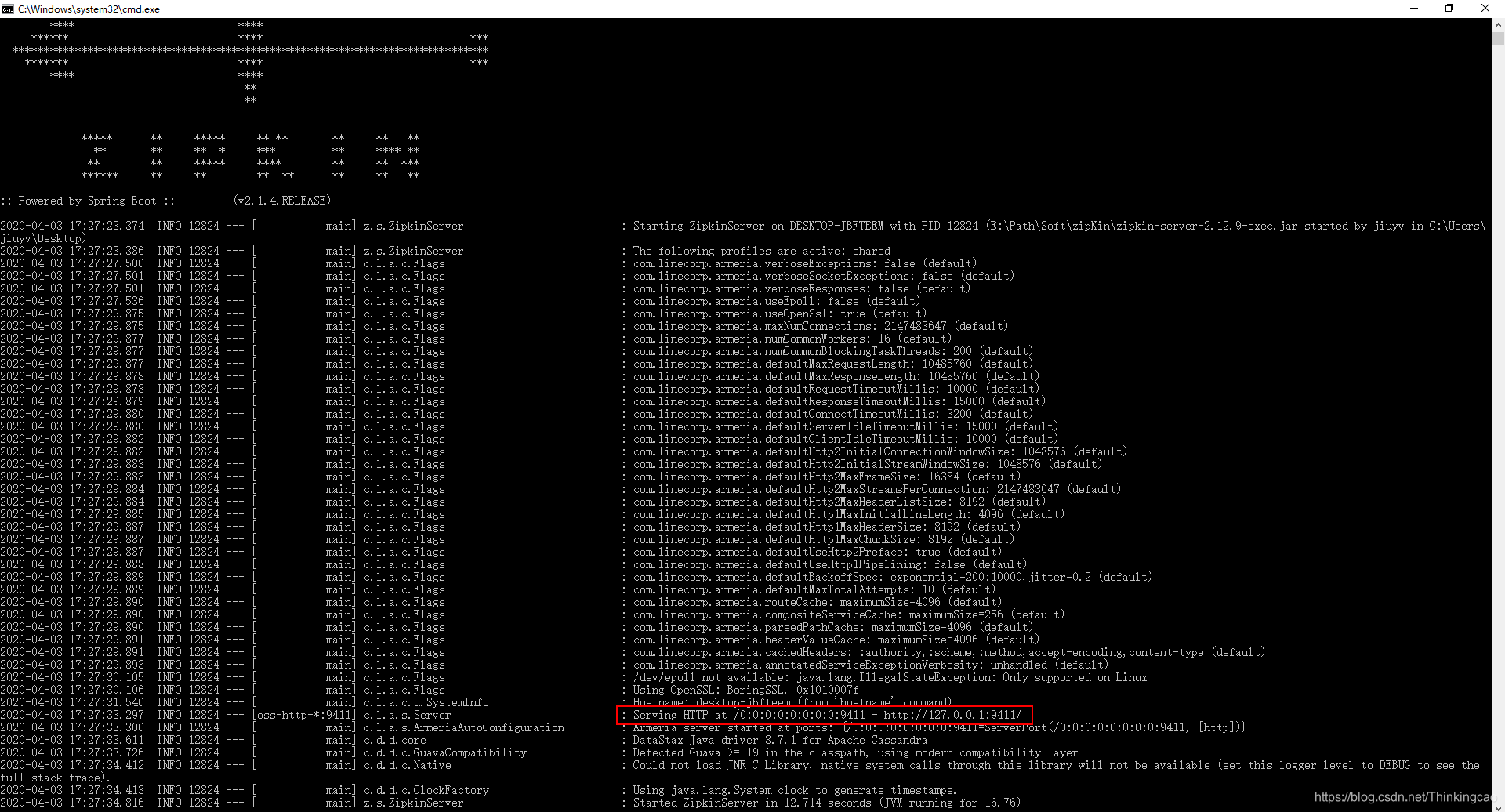
我这里使用的是 zipkin-server-2.12.9-exec.jar,启动zipkin-server,端口默认是9411:
java -jar zipkin-server-2.12.9-exec.jar
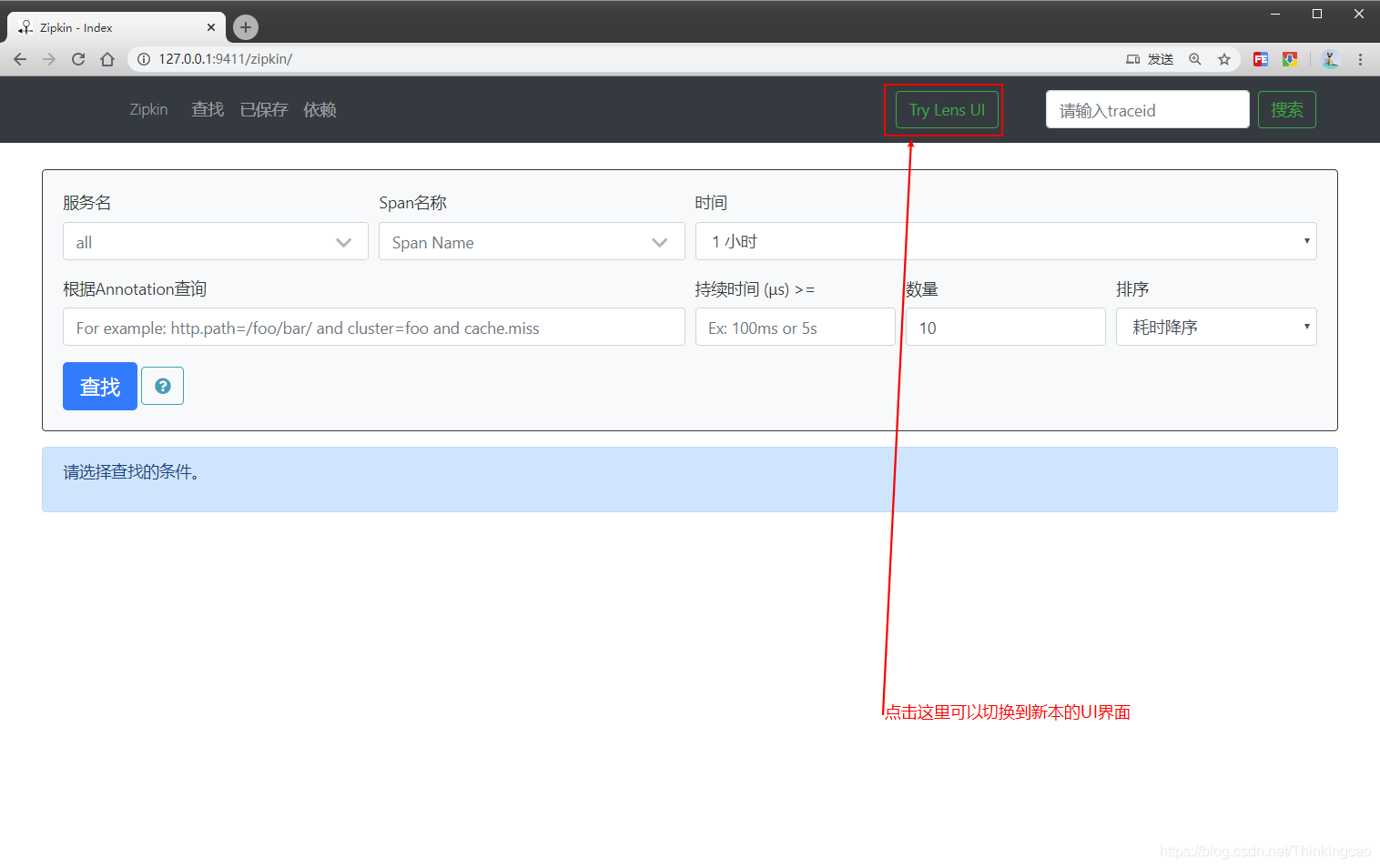
访问地址: http://127.0.0.1:9411/zipkin/ ,现在是没有数据的。
2. 工程准备
- eureka-server: 服务注册中心,端口8000
- app-order: 订单服务工程,端口8761
- app-member: 会员服务工程,端口8765
- app-pay: 支付服务工程,端口8763
为了节省不必要的搭建过程,eureka-server、app-order、app-member这三个工程使用前面第二章节的源码: 使用 Spring Cloud系列教程(二) - 服务消费者Rest+Ribbon(Finchley版本) 这一节的源码, 然后在第二章的源码基础上修改pp-order程和app-member工程,另外新增一个支付服务工程: app-pay, 这三个服务的调用关系为:app-order——>app-member——>app-pay
七、环境搭建
7.1 创建springcloud-app-pay工程
1. 依赖如下:
<!--SpringBoot依赖版本-->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.3.RELEASE</version>
<relativePath/>
</parent>
<groupId>com.thinkingcao</groupId>
<artifactId>springcloud-app-pay</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>springcloud-app-pay</name>
<description>支付服务</description>
<!--项目编码、jdk版本、SpringCloud版本定义-->
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<spring-cloud.version>Finchley.RELEASE</spring-cloud.version>
</properties>
<!--声明管理SpringCloud版本依赖信息-->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- SpringBootWeb组件 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- springcloud整合eureka客户端组件 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<!-- springcloud sleuth整合zipkin客户端组件 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
</dependencies>
<!--maven插件-->
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
2.application.yml配置链路追踪数据上传至Zipkin
Spring Cloud
Sleuth有一个Sampler策略,可以通过这个实现类来控制采样算法。采样器不会阻碍span相关id的产生,但是会对导出以及附加事件标签的相关操作造成影响。
Sleuth默认采样算法的实现是Reservoir
sampling,具体的实现类是PercentageBasedSampler,默认的采样比例为:
0.1(即10%)。不过我们可以通过spring.sleuth.sampler.percentage来设置,所设置的值介于0.0到1.0之间,1.0则表示全部采集。
##=========支付服务配置========
#服务端口号
server:
port: 8763
#定义服务名称(服务注册到eureka名称)
spring:
application:
name: app-thinkingcao-pay
#zipkin服务端地址(sleuth-cli收集信息后通过http传输到zinkin-server)
zipkin:
#数据上传至zipkin服务端的地址
base-url: http://127.0.0.1:9411/
#设置成false,表示这只是一个URL地址而不是服务名称(nacos与zipkin一起使用时可能出现此问题,这里可忽略)
#discoveryClientEnabled: false
#发送数据类型 kafaka、rabbitmq、web
sender:
type: WEB
#全部采集,默认的采样比例为: 0.1(即10%),1.0则表示全部采集
sleuth:
sampler:
probability: 1.0
#在此指定服务注册中心地址,将当前服务注册到eureka注册中心上
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:8000/eureka
#启动注册操作,该值默认为true。若设置为fasle将不会启动注册操作。是否需要去检索寻找服务,默认是true
register-with-eureka: true
#是否需要从eureka上获取注册信息
fetch-registry: true
#表示eureka client间隔多久去拉取服务器注册信息,默认为30秒
registry-fetch-interval-seconds: 10
##心跳检测与续约时间(测试环境和本地开发环境将值设置小一点,保证服务关闭后,注册中心能够及时踢出)
instance:
#客户端向Eureka注册中心发送心跳的时间间隔,单位为秒(默认为30s),(客户端会按照此规则向Eureka服务端发送心跳检测包)
lease-renewal-interval-in-seconds: 2
#Eureka注册中心在收到客户端最后一次心跳之后等待的时间上限,单位为秒(默认为90s),超过时间则剔除(客户端会按照此规则向Eureka服务端发送心跳检测包)
lease-expiration-duration-in-seconds: 2
注意: 下述这个配置,其中数据的发送类型有:kafka、rabbitmq、web三种,如果微服务项目比较庞大的情况下,可以现将数据发送至rabbitmq或者kafka,然后rabbitmq或者kafka再将消息日志数据发送到zipkin服务端,这样一来主要是为了解决高并发场景下实现流量消峰的问题。
#发送数据类型 kafaka、rabbitmq、web
sender:
type: WEB
如果需要引入rabbitmq来进行服务追踪数据的一个中间传输的话,需要引入依赖
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>
同时application.yml配置需要加入rabbitmq的配置信息,kafka的配置与其类似,这里不累赘
#发送数据类型 kafka、rabbitmq、web
sender:
type: WEB
#rabbitmq配置
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
listener:
# 这里配置了重试策略
direct:
retry:
enabled: true
simple:
retry:
enabled: true
这里我们不采用中间件传输,发送类型设置为WEB。
3. 创建支付服务接口
package com.thinkingcao.api.controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @desc: 支付服务接口
* @author: cao_wencao
* @date: 2020-03-26 13:32
*/
@RestController
public class PayController {
@RequestMapping("/doPay")
public String doPay() {
try {
Thread.sleep(5000);
} catch (Exception e) {
System.out.println(e.getMessage());
}
return "我支付服务哦,准备开始执行支付操作啦";
}
}
4. 启动类
启动类加入@EnableEurekaClient或者@EnableDiscoveryClient注解,前面对此注解做了解释,这里再次解释下:
- @EnableEurekaClient: 启用eureka客户端向eureka服务端注册服务信息,只针对eureka独有的注解。
- @EnableDiscoveryClient: 启用注册中心(eureka、zookeeper、Consule、Nacos等)客户端向注册中心服务端注册服务信息,针对所有注册中心组件。
package com.thinkingcao.api;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
@SpringBootApplication
@EnableEurekaClient
public class AppPayApplication {
public static void main(String[] args) {
SpringApplication.run(AppPayApplication.class, args);
}
}
7.2 改造订单工程springcloud-app-order
1. application.yml 加入服务链路追踪配置
#zipkin服务端地址(sleuth-cli收集信息后通过http传输到zinkin-server)
zipkin:
base-url: http://127.0.0.1:9411/
#设置成false,表示这只是一个URL地址而不是服务名称(nacos与zipkin一起使用时可能出现此问题)
#discoveryClientEnabled: false
#发送数据类型 kafaka、rabbitmq、web
sender:
type: WEB
#全部采集,默认的采样比例为: 0.1(即10%),1.0则表示全部采集
sleuth:
sampler:
probability: 1.0
2. pom.xml加入服务链路追踪的依赖
<!-- springcloud sleuth整合zipkin客户端组件 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
3. OrderController接口改造
package com.thinkingcao.api.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
/**
* @desc: 订单调用会员服务接口
* @author: cao_wencao
* @date: 2020-02-19 17:47
*/
@RestController
public class OrderController {
@Autowired
private RestTemplate restTemplate;
//订单服务(消费者)调用会员服务(生产者)接口
@RequestMapping("/getOrderToMember")
public String getOrderToMember() {
String url = "http://app-thinkingcao-member/getMember";
String result = restTemplate.getForObject(url, String.class);
return result;
}
// 有两种方式调用,一种是采用服务别名方式调用,使用别名方式会去注册中心上获取对应的服务调用地址;
// 另一种是直接使用IP地址调用(不会走注册中心)
@Bean
@LoadBalanced
RestTemplate restTemplate() {
return new RestTemplate();
}
//订单服务(消费者)调用会员服务(生产者)接口,会员服务(消费者)调用支付生产者
@RequestMapping("/getOrderToMemberToMsg")
public String getOrderToMemberToMsg() {
String url = "http://app-thinkingcao-member/memberToPay";
String result = restTemplate.getForObject(url, String.class);
System.out.println("订单服务调用会员服务result: "+ result);
return result;
}
}
7.3 改造会员工程springcloud-app-member
1. applicayion.yml配置和pom.xml同上述新增的配置一样,此处省略
2. 改造MemberController接口调用支付服务接口
package com.thinkingcao.api.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
/**
* @desc: 会员服务接口
* @author: cao_wencao
* @date: 2020-02-19 18:12
*/
@RestController
public class MemberController {
@Autowired
private RestTemplate restTemplate;
@Value("${server.port}")
private String serverPort;
//会员服务接口
@RequestMapping("/getMember")
private String getMember() {
return "我是会员服务,订单服务调用会员服务成功啦, 端口号为: " + serverPort;
}
//会员调用支付接口
@RequestMapping("/memberToPay")
public String memberToPay(){
String url = "http://app-thinkingcao-pay/doPay";
String result = restTemplate.getForObject(url, String.class);
System.out.println("会员服务调用支付服务result: "+ result);
//制造空指针异常场景,被ZipKin发觉
/* String str = null;
if (str.equals("123aaa"))
{
}*/
return result;
}
@Bean
@LoadBalanced
RestTemplate restTemplate() {
return new RestTemplate();
}
}
至此,项目的服务调用环境已经通过实战搭建完成了,接下来开始测试啦。
八、测试
依次启动服务:
①. eureka-server: 服务注册中心,端口8000;
②. app-pay: 支付服务工程,端口8763;
③. app-member: 会员服务工程,端口8765;
④. app-order: 订单服务工程,端口8761;
1. 访问注册中心:http://127.0.0.1:8000/
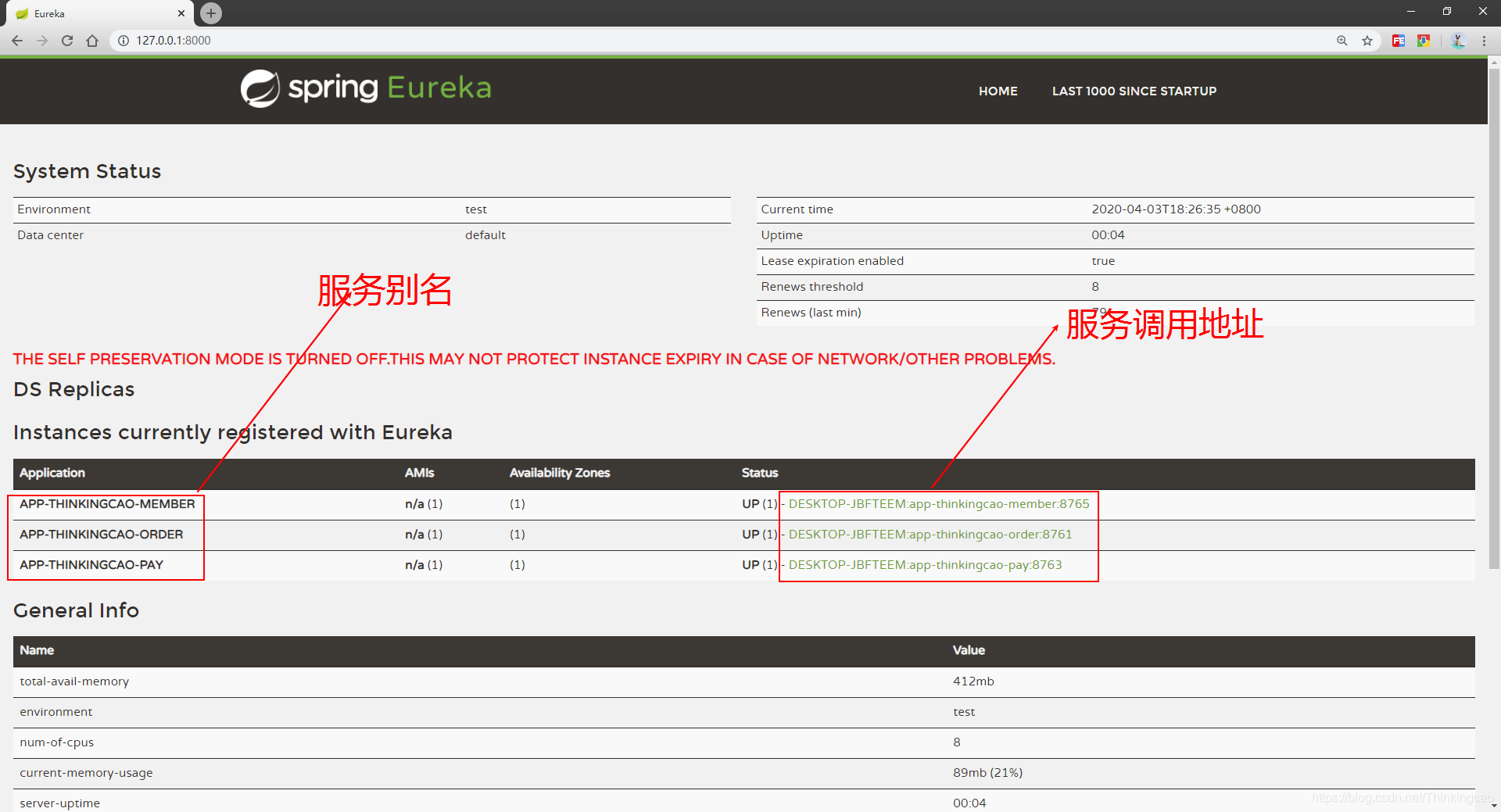
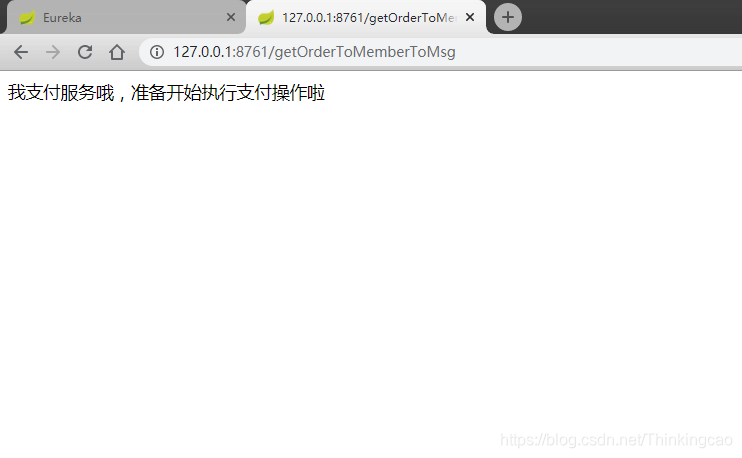
2. 访问订单服务: http://127.0.0.1:8761/getOrderToMemberToMsg
(1)、先执行一次访问订单服务的请求,结果如下:
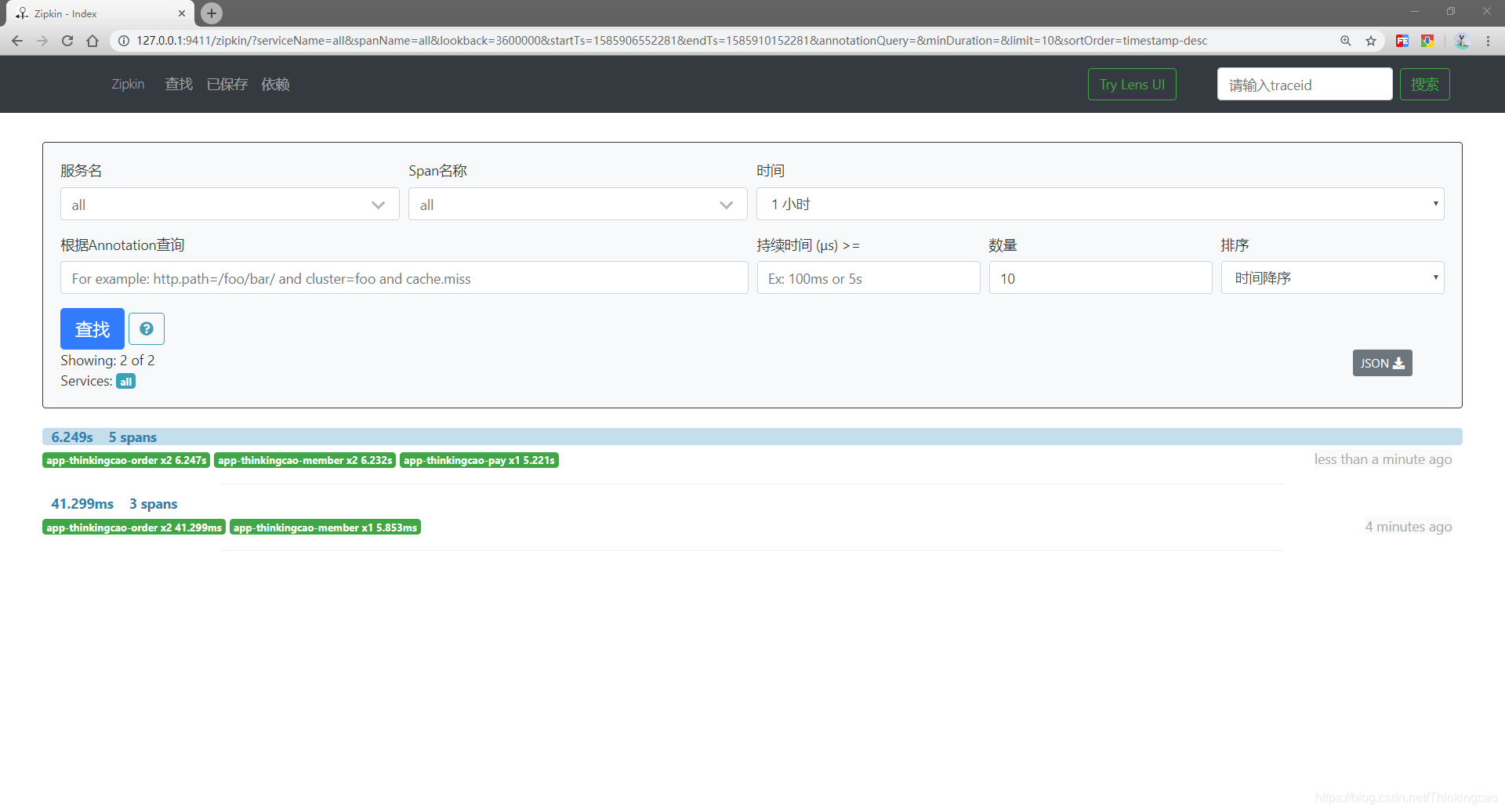
(2)、查看zipkin控制台: http://127.0.0.1:9411/zipkin/
调用链关系图如下:
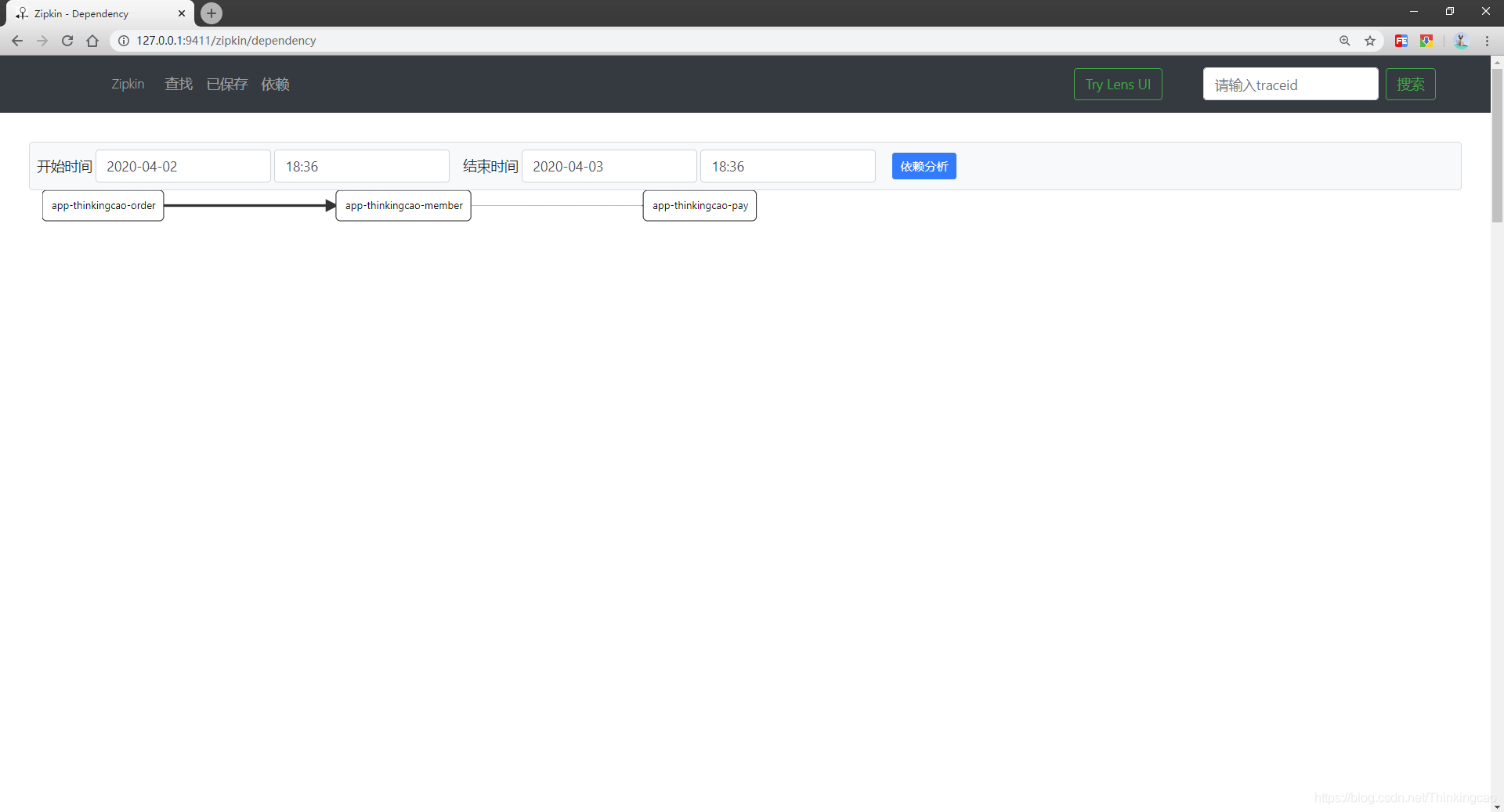

3. 将支付服务宕机,然后再次访问订单的请求
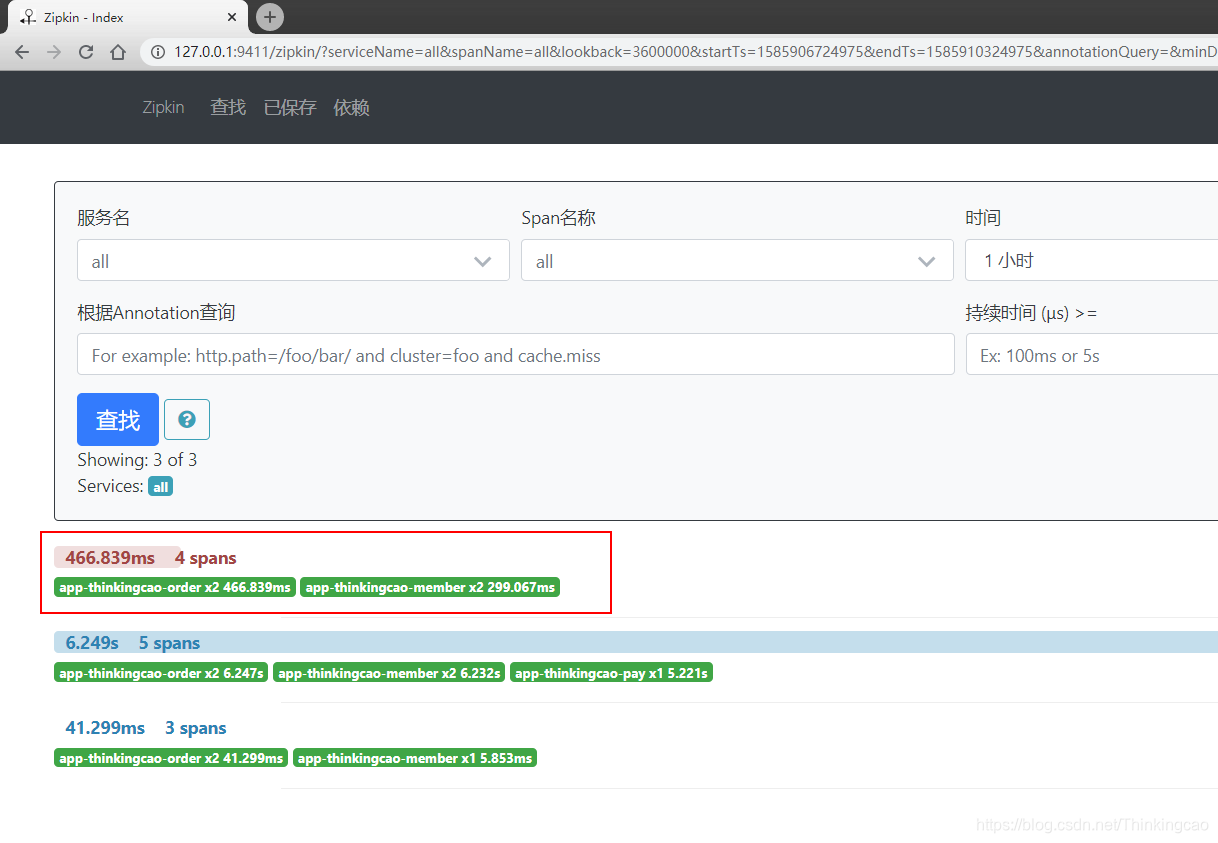
从上图的结果可以看到,因为订单调用会员,会员调用支付服务,由于支付服务宕机掉了,这里整个服务返回结果异常了。分析这个调用链,上述红框点进去看可以看出如下结果:
支付服务(app-pay): error日志显示这个实例已经不可用了,没有提供可用的实例
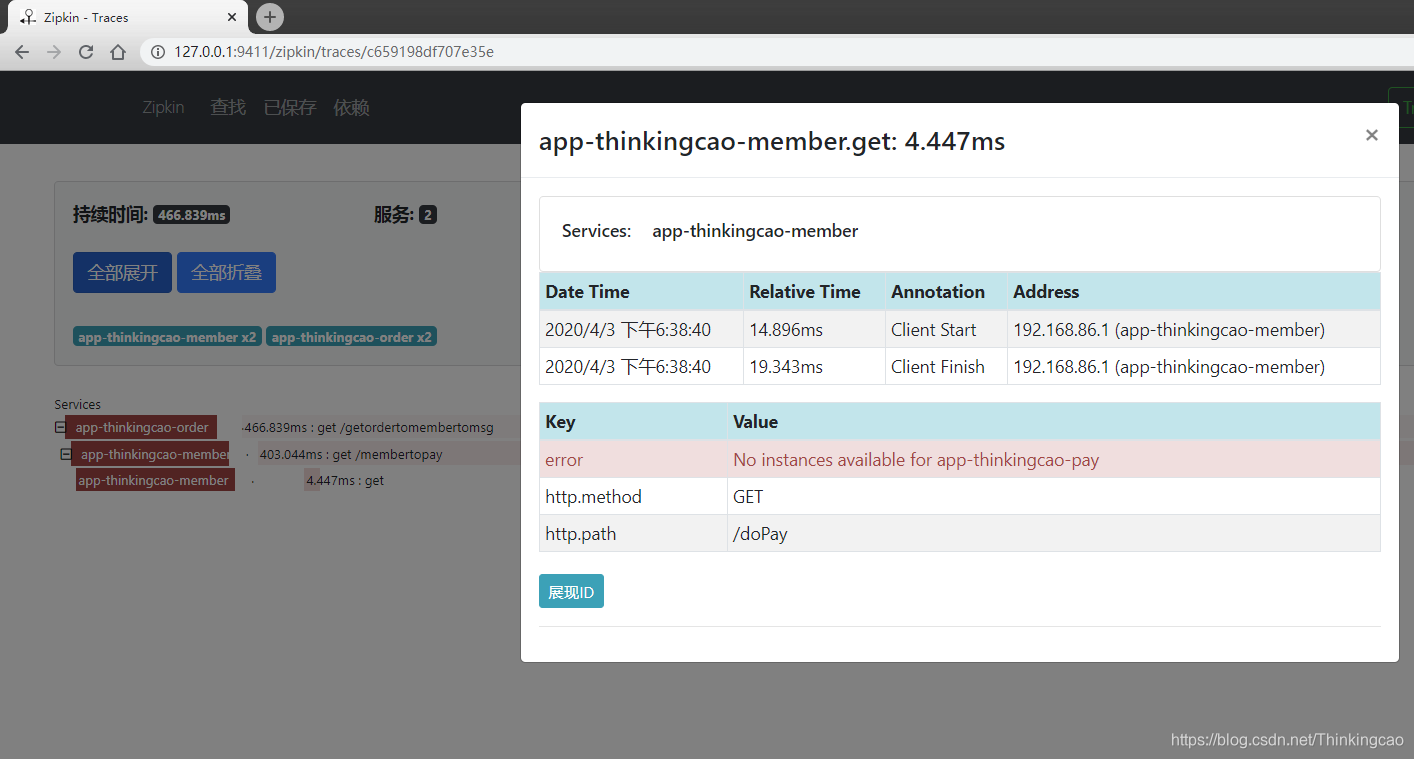
会员服务(app-member): error日志显示在app-member服务在调用app-pay服务的时候,返回app-pay没有可用的实例了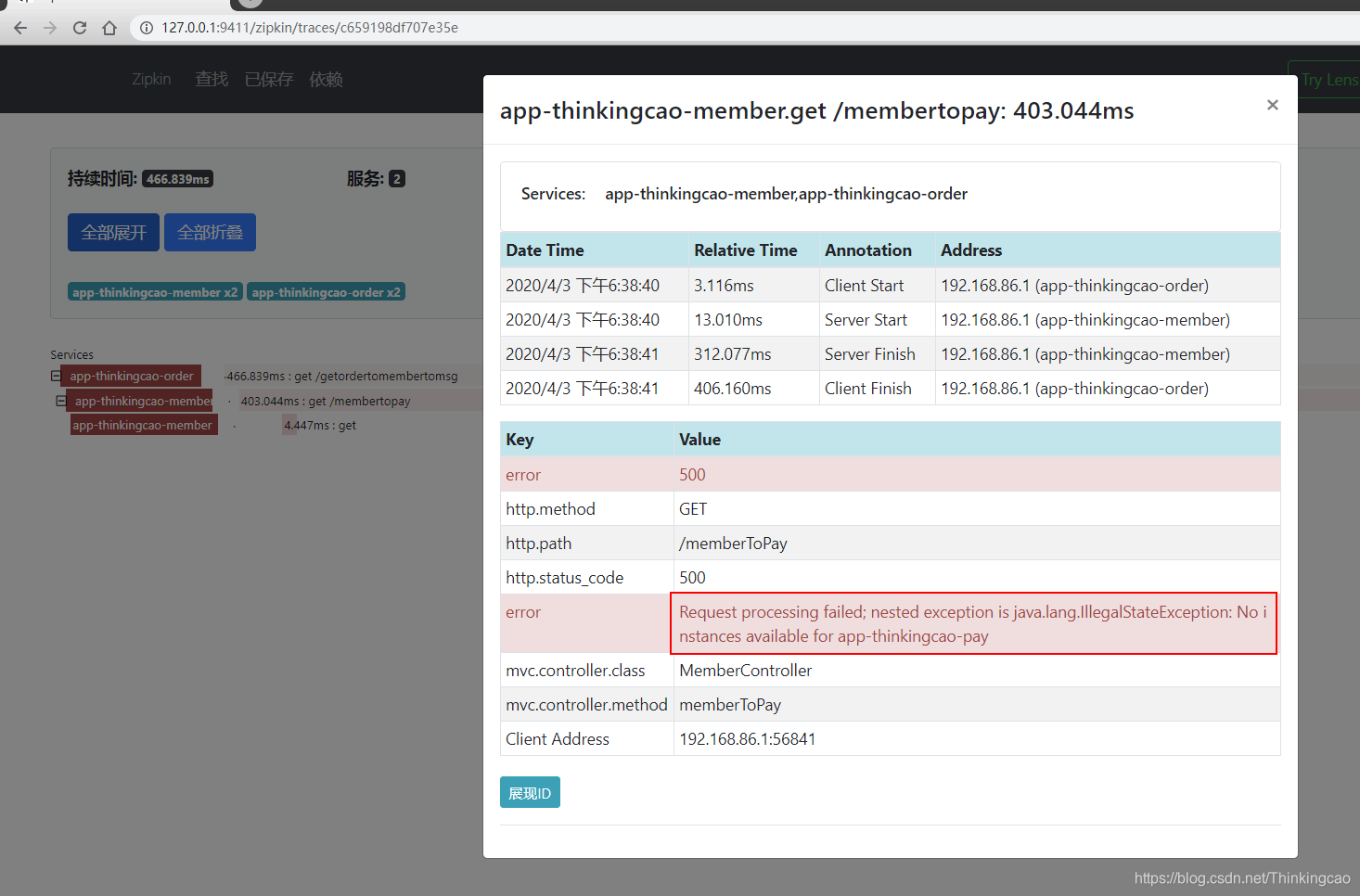
订单服务(app-member): error日志显示在app-order服务在调用app-member服务的时候,返回500错误,因为我们调用app-member是可以调通的,只是app-member在调用app-pay的时候异常了,所以拿不到正确的响应结果,返回客户端500异常,补充下,通过Hystrix服务保护可防止此异常响应给客户端,因此通过上述案例分析,Spring Cloud Sleuth+Zipkin在微服务服务链路追踪过程当中,真的帮我们解决了很大一部分问题,像常见的空指针异常、数据库连接异常、网络异常、宕机等异常都可以全部给我们追踪出来,他是必不可少的组件。
九、源码
源码: https://github.com/Thinkingcao/SpringCloudLearning/tree/master/springcloud-sleuth-zipkin
十、SpringCloud系列教程
下一篇: Spring Cloud系列教程(十四):服务追踪SpringCloud Sleuth集成Zipkin持久化数据存储MySQL(Finchley版本)
SpringCloud教程汇总: Spring Cloud系列教程(汇总篇):专栏汇总篇(持续更新中)

