一、引子
xpath 是 XML 的路径语言,通俗一点讲就是通过元素的路径来找到这个标签元素。
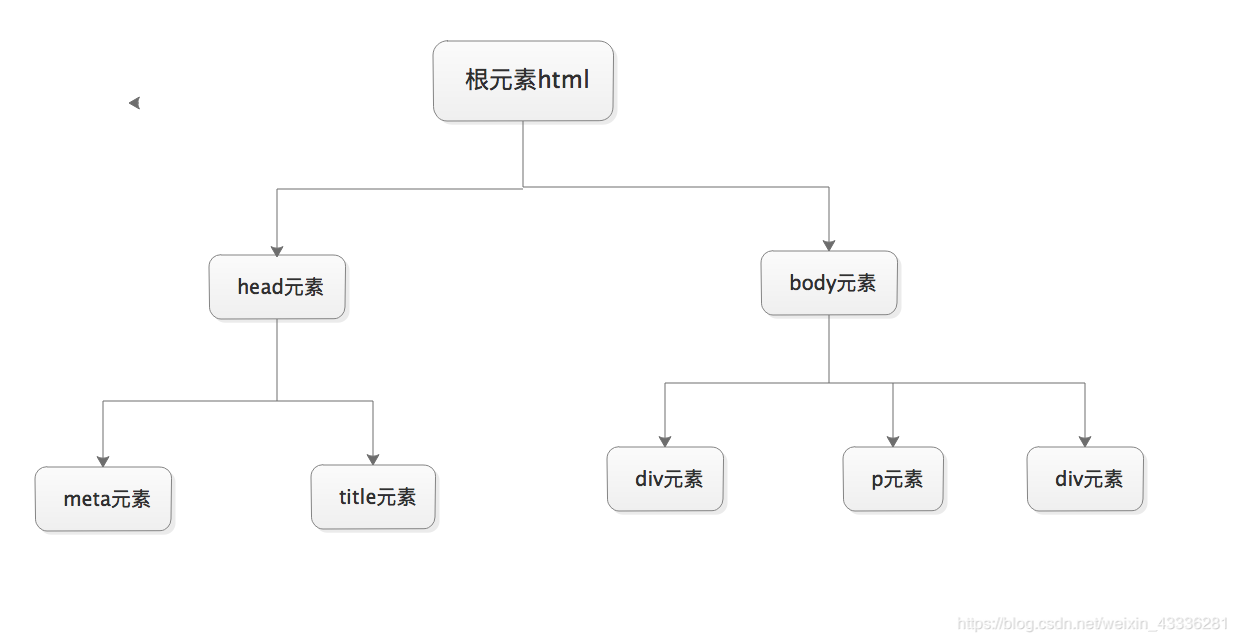
xpath 解析是爬虫中最常用也是最通用的一种数据解析方式,其简洁高效的解析方式深受广大爬虫工程师的喜爱。
环境安装
使用 xpath 解析需要安装一个第三方库:
pip install lxml
解析步骤
- 使用通用爬虫爬取网页全部数据
- 实例化 etree 对象,并将页面数据加载到该对象中
- 使用 xpath 函数结合 xpath 表达式进行标签定位并提取指定数据
二、xpath 实战
爬取拉勾网 Python 岗位信息
Analysis
- 确定爬取 URL:https://www.lagou.com/zhaopin/Python/
- Page 分析
第一页 URL:https://www.lagou.com/zhaopin/Python/
第二页 URL:https://www.lagou.com/zhaopin/Python/2/
第三页 URL:https://www.lagou.com/zhaopin/Python/3/
……
第 n 页 URL:https://www.lagou.com/zhaopin/Python/n/
- Elements 分析:
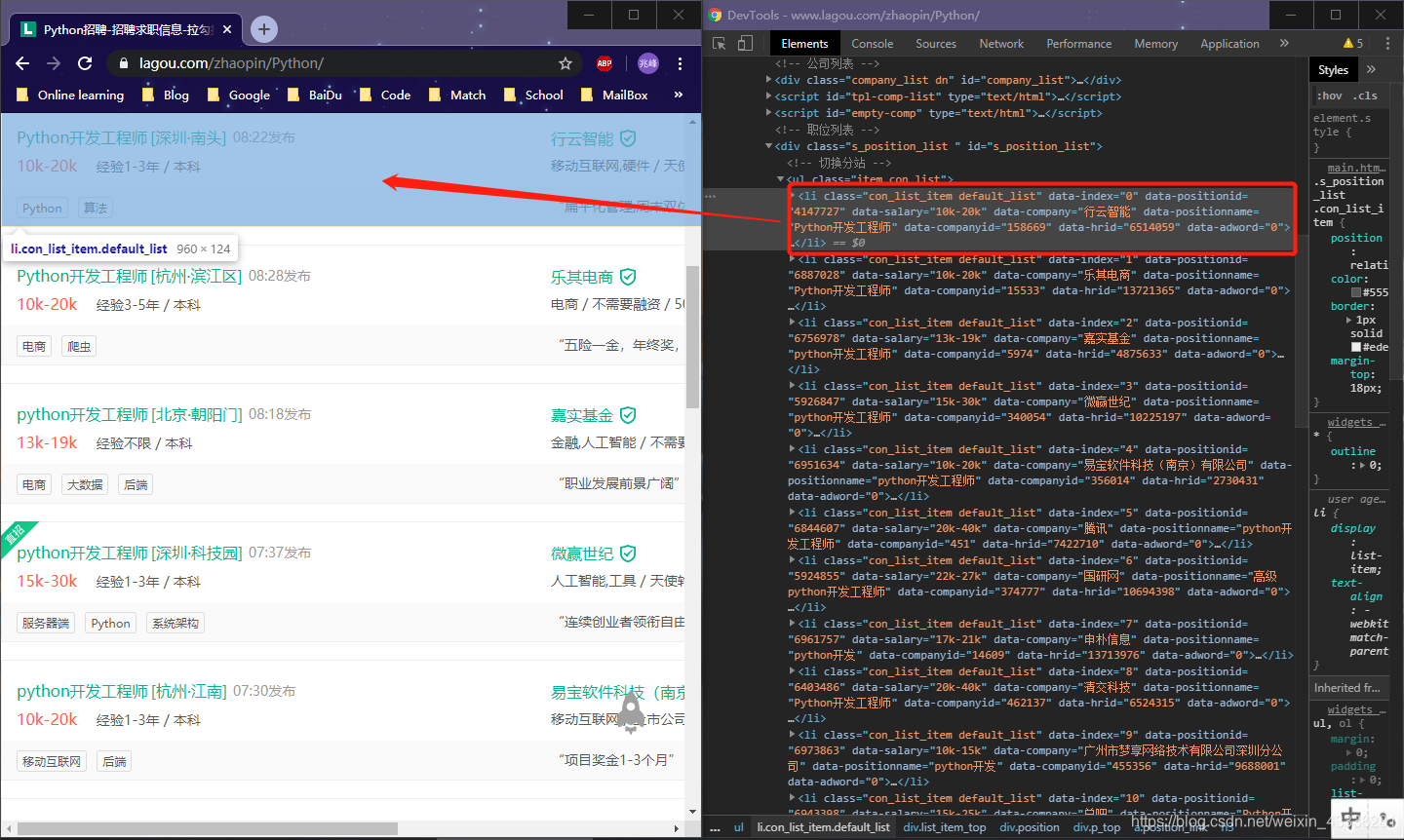
<ul class="item_con_list">下的每一个 <li class="con_list_item default_list"就对应了一个招聘信息。
定位这些 li 标签://*[@id="s_position_list"]/ul/li
通过观察可以发现,岗位名称、公司名称和薪资都是直接写在了 li 标签的属性中,因此可以直接通过提取属性获得这些值:
定位岗位名称://*[@id="s_position_list"]/ul/li/@data-positionname
定位公司名称://*[@id="s_position_list"]/ul/li/@data-company
定位薪资://*[@id="s_position_list"]/ul/li/@data-salary
然后通过每一个 li 标签为根再定位公司地址、工作经验要求和企业简介:
定位公司地址:.//div[1]/div[1]/div[1]/a/span/em
工作经验要求:.//div[1]/div[1]/div[2]/div/text()
公司简介:.//div[1]/div[2]/div[2]/text()
最后获取每个职位的详情页面 URL,并爬取职位描述:
详情页 URL:.//div[1]/div[1]/div[1]/a/@href
职位描述://*[@id="job_detail"]/dd[2]/div//text()
Code
import json
import time
import random
import requests
from lxml import etree
if __name__ == '__main__':
headerList = [
{"user-agent": "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)"},
{"user-agent": "Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1"},
{
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"}
]
allData = {}
for index in range(1, 31):
print("正 在 爬 取 第 %d 页......" % index)
firstUrl = "https://www.lagou.com/zhaopin/Python/%d/" % index
pageHtml = requests.get(url=firstUrl, headers=random.choice(headerList), timeout=500).text
firstTree = etree.HTML(pageHtml)
liList = firstTree.xpath('//*[@id="s_position_list"]/ul/li')
for li in liList:
secondUrl = li.xpath('.//div[1]/div[1]/div[1]/a/@href')[0]
detailHtml = requests.get(url=secondUrl, headers=random.choice(headerList), timeout=500).text
secondTree = etree.HTML(detailHtml)
liData = {
"positionName": li.xpath('./@data-positionname')[0],
"company": li.xpath('./@data-company')[0],
"salary": li.xpath('./@data-salary')[0],
"address": li.xpath('.//div[1]/div[1]/div[1]/a/span/em/text()'),
"experience": li.xpath('.//div[1]/div[1]/div[2]/div/text()'),
"companyProfile": li.xpath('.//div[1]/div[2]/div[2]/text()'),
"detailUrl": secondUrl,
"describe": secondTree.xpath('//*[@id="job_detail"]/dd[@class="job_bt"]/div[@class="job-detail"]//text()')
}
allData["%s-%s" % (liData["company"], liData["positionName"])] = liData
time.sleep(1)
with open("拉勾网Python职位信息.json", "w", encoding="utf-8") as fp:
json.dump(obj=allData, fp=fp, ensure_ascii=False)
