摘要:深度学习不能仅仅停留在理论层面,更重要的是为人所用。但是如下图所示,深度神经网络应用于实际生活,还有很多困难。所以将网络模型部署到存储空间更小、计算力更低的可移动设备上对于深度学习的发展至关重要。这篇文章从以上角度对一些经典网络进行简要介绍与分析,并搭配一些常用的网络优化方法,希望可以让对于这方面比较感兴趣的读者对此有一定的了解。

首先,让我们来逐一介绍分析几种经典网络。
下图是Imagenet历年冠军模型的错误率和网络深度,可以看出“更深更准”是大势所趋。但是更深的网络往往会带来参数量和计算量的激增,为此研究者们提出了许多解决方法。

让我们先看以下两张图片,可以看出,我们可以使用2个3x3的滤波器替换1个5x5的滤波器,使用3个3x3的滤波器替换1个7x7的滤波器,因为感受野(由输出的1x1对应到输入的feature map大小)是相同的。


通过这个方式,增加了网络的深度,增加了网络的非线性表达能力(卷积层多了,对应的激活函数层也多了),同时还降低了参数和计算量(如下式)。
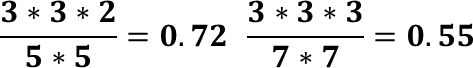
根据以上思想,19层的VGG出现了,与以前的8层相比,可谓发生了质的变化,其网络结构如下:

从深度出发提高了准确率,那么我们自然会想到从宽度上做一些文章,于是诞生了GoogLe Net(据说L大写是为了纪念Le Net)。其主要结构为Inception,如下图所示:

一个卷积层内含有1x1卷积、3x3卷积、5x5卷积和池化,这样就提取了更加丰富的信息。但是这样做,通道数会明显增加,所以引入了1x1卷积对通道数进行降维。
先来介绍一下,为何1x1卷积可以用来改变通道数,如下图所示。

用降维举例,阴影是1x1卷积核。卷积核对每一个点进行卷积,每一次卷积输出下面的一个点。如果有两个卷积核,那么第一个卷积核就输出了粉色的通道,第二个卷积核就输出了黄色的通道。这样就实现了通道数的改变。
因此,改进后的Inception结构如下所示(b):降低了通道数,虽然网络宽度变大了,但是计算量也不会增加太多。

一定有人想到了将5x5替换为2个3x3,确实是这样。进一步,我们甚至可以将3x3替换为1x3和3x1,如下图所示。

这样就可以进一步改进Inception的结构:

同时,为了防止网络深度增加,反向传播过程中梯度消失,前几层的效果较差,在网络中间部分同样设置了输出,计算损失,用以监督学习过程,如下图黄色部分所示。

以上两种网络,虽然考虑到了计算量和效率,但是主要是为了准确率而生,那么接下来的两个网络则主要是为了效率和减少存储空间而生。
第一个是Squeezed Net。
该网络的主要思想浓缩于Fire Module,如下图所示,一个瓶颈结构。

首先使用1x1的卷积进行降维,然后再对输出进行一些3x3和1x1的卷积操作。这样既增加了深度,也增加了宽度。同时,增加了网络超参数控制3x3和1x1的比例,调整该参数可以在网络性能几乎不变的条件下,控制模型的大小。
第二个是Mobile Net。

Mobile Net可以实现很大的可控压缩比,能够部署在移动设备上,让我们看看它是如何做到的。
该网络利用了深度可分离卷积,如下图所示。

输入的大小为N个DfxDf,滤波器的大小为DkxDk,通道数为M。那么普通的卷积对应图中的a,右侧是其计算量。那么b、c对应了深度可分离卷积,先对输入的每一个通道分别进行卷积,再用1x1的卷积核对所有通道进行卷积,两者的计算量之和远远低于a的计算量,如下式。

α和ρ分别代表宽度因子和分辨率因子,可以进一步对网络进行压缩,一般两者取0.7,这样0.7x0.7x0.7x0.7=0.24,模型又被压缩了76%,而且准确率不会受到较大影响。
除了深度可分离卷积之外,还有群组卷积,同样可以提高计算效率,如下图。

将各个通道分组,然后分别卷积,这样降低了计算量。但是如a所示,这样影响了信息的流通,所以要进行通道混洗,如b、c所示。这样就在降低计算量的同时,也保证了信息的流通。
最后一个要介绍的网络是目前经常被用作baseline的Res Net。文中开始时提到“更深更准”是大势所趋,那么Res Net将网络深度陡然提升。
但是,理想很丰满,现实很骨干。如前所述,网络太深不利于训练,甚至不如比较浅的网络。如下图所示。

为了解决这一问题,Res Net使用如下结构:

将每一个部分的输入直接连接到输出,再将多个这样的结构级联,那么如果左侧的影响忽略不计,那么Res Net就相当于减少了层数,它的性能就至少不会比较浅的网络差。而事实上,Res Net的性能超越了较浅的网络,成为了当今的主流网络之一。实验结果如下图所示。

介绍完一些经典网络,我们来聊一聊一些常用的网络压缩方法。
剪枝

对于权重较小的连接,直接去除,可以大幅度提升网络速度并对网络进行大幅压缩。
权值共享

对成千上万的权值进行聚类,用新的权值替代该类别的所有权值,这样就降低了网络需要存储的数据量,实现了对网络的压缩。
量化

上面对应两种量化,其中把输入和权值全部量化为1和-1的网络叫做XNOR Net。通过量化降低了存储空间,实现了网络压缩。(在此基础上当然可以进行编码操作,比如哈夫曼编码)
蒸馏

严格意义上不属于网络压缩方法。用大的模型监督小的模型训练,使小的模型具有一定大的模型的能力,这样就可以在一定场合用小模型代替大模型,间接实现了网络压缩。
一般来说,可以将如上操作组合使用,这样的压缩效率是很可观的。
以上内容大多一带而过,仅仅介绍了思想。感兴趣的读者应该以此为原点,继续深入研究学习。
完
欢迎讨论 欢迎吐槽
