本文重点梳理常用的语言模型。
语言模型主要包括统计语言模型、神经语言模型。其中统计语言模型主要包括LSI、n-gram(贝叶斯)等,而神经语言模型主要包括n-gram(Bengio)、word2vec(skip-gram、CBOW)。最后介绍结合了统计语言模型和神经语言模型的GloVe模型。
一、统计语言模型
1. LSI
LSI即隐性语义索引。它的计算方法是,先基于词频统计得到词语-文档矩阵,然后利用SVD对词语-文档矩阵进行分解。在新生成的矩阵中的一些结果作为词向量。这里给出一个例子,如下图,左侧竖栏是词语,上方横栏是文档,数值代表某篇文档中是否包含某个词。

对C进行SVD分解C = UΣVT ,
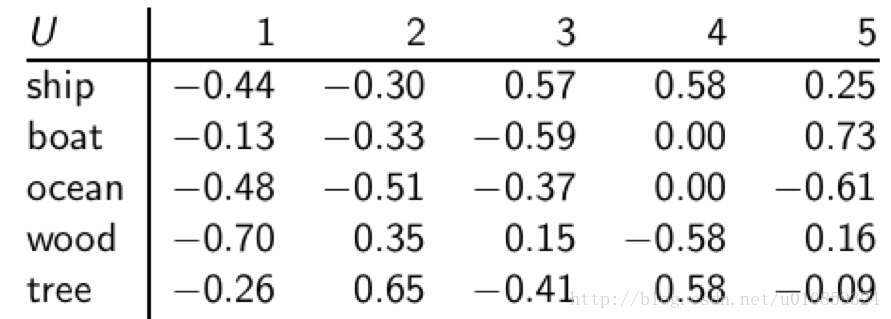
每个词语对应一行,每个min(M,N)对应一列,其中M为词语的数目,N是文档的数目。 这是个正交矩阵:
(i) 列向量都是单位向量;
(ii) 任意两个列向量之间都是互相正交的。可以想象这些列向量分别代表不同 的“语义”维度,比如政治、体育、经济等主题。矩阵元素 uij 给出的是词项i和第j个“语义”维度之间的关系强弱程度。
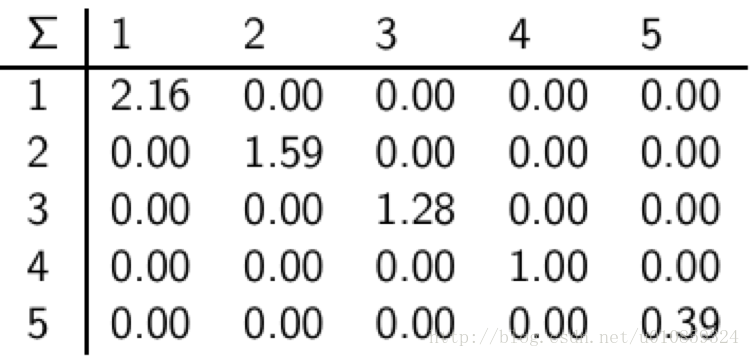
这是个min(M,N) × min(M,N)的对角方阵。对角线上是矩阵C的奇异值。奇异值的大小度量的是相应“语义”维度的重要性。我们可以通过忽略较小的值来忽略对应的“语义”维度。各个语义之间是垂直的。
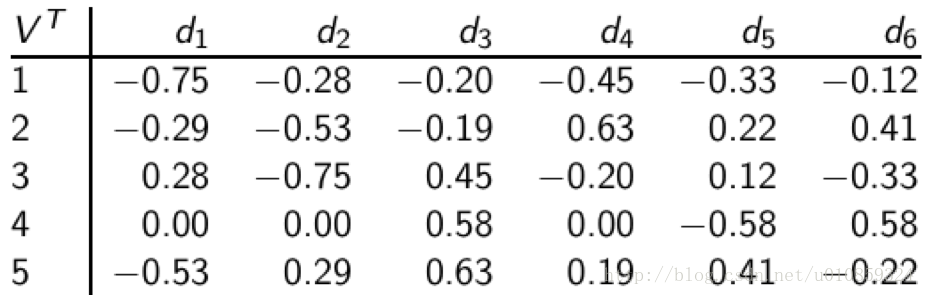
每篇文档对应一列,每 min(M,N) 对应一行。同样,这也是一个正交矩阵:
(i) 每个行向量都是单位向量;
(ii) 任意两个行向量之间都是正交的;
同样每个行向量代表的是一个语义维度,矩阵元素vij 代表的是文档 i 和语义维度j的关系强弱程度。
经过以上过程,我们可以将矩阵U中的每一行作为对应词汇的向量表示。即词ship的向量表示即为[-0.44,-0.3,0.57,0.58,0.25]。
这里的U是保存了分解后的全部信息,入股要舍弃冗余信息,可以对U进行降维,方法是根据奇异值矩阵中的奇异值大小做取舍,比如在这个case中,保留最大的两个奇异值,分解结果就变为
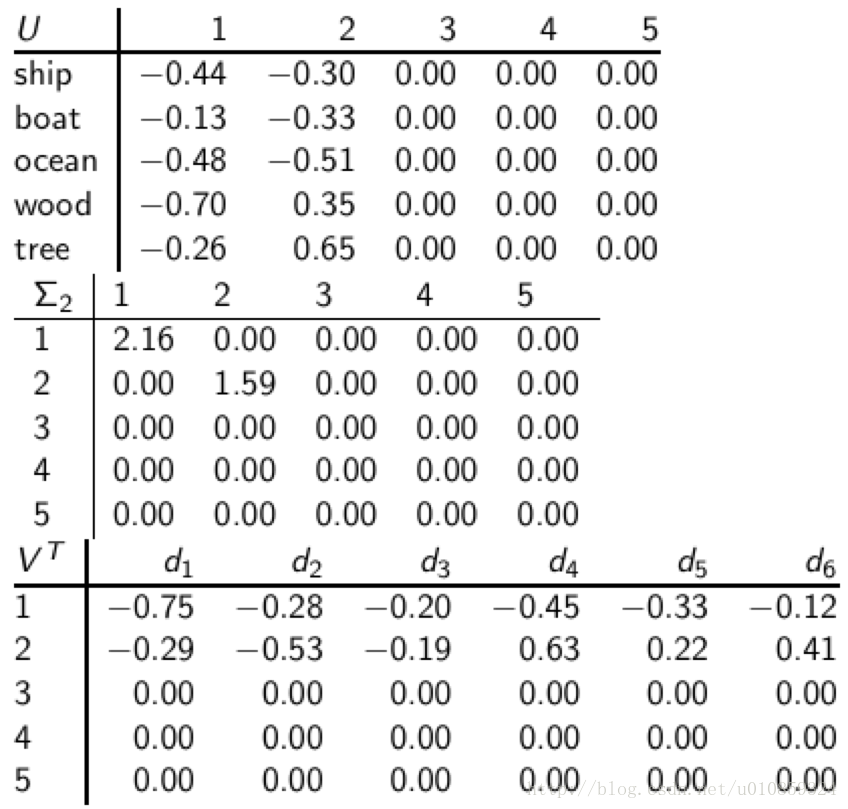
词语ship的向量表示就变为[-0.44,-0.3,0,0,0]
2.n-gram
假设一个句子是由{w1,w2,w3,…wn}来表示的,其中wi表示的句子中的单词,那么,一个语言模型就可以用如下来表示:
P={w1,w2,w3,…wn}
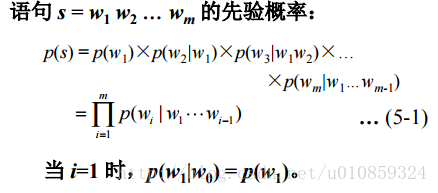
严格按照这个公式来算的话会因为词汇量太大使得计算量暴增,所以为了能够计算,将条件概率进行简化,对于每一个单词,只考虑其前面的n个单词。
譬如n取2,则
P{wm|w1,w2,…wn}=P{wm|wm−1,wm−2}
另外,计算的时候注意做平滑处理。
二、神经语言模型
1. n-gram(Bengio)
Bengio的《A Neural Probabilistic Language Model》算是神经语言模型的开山之作,
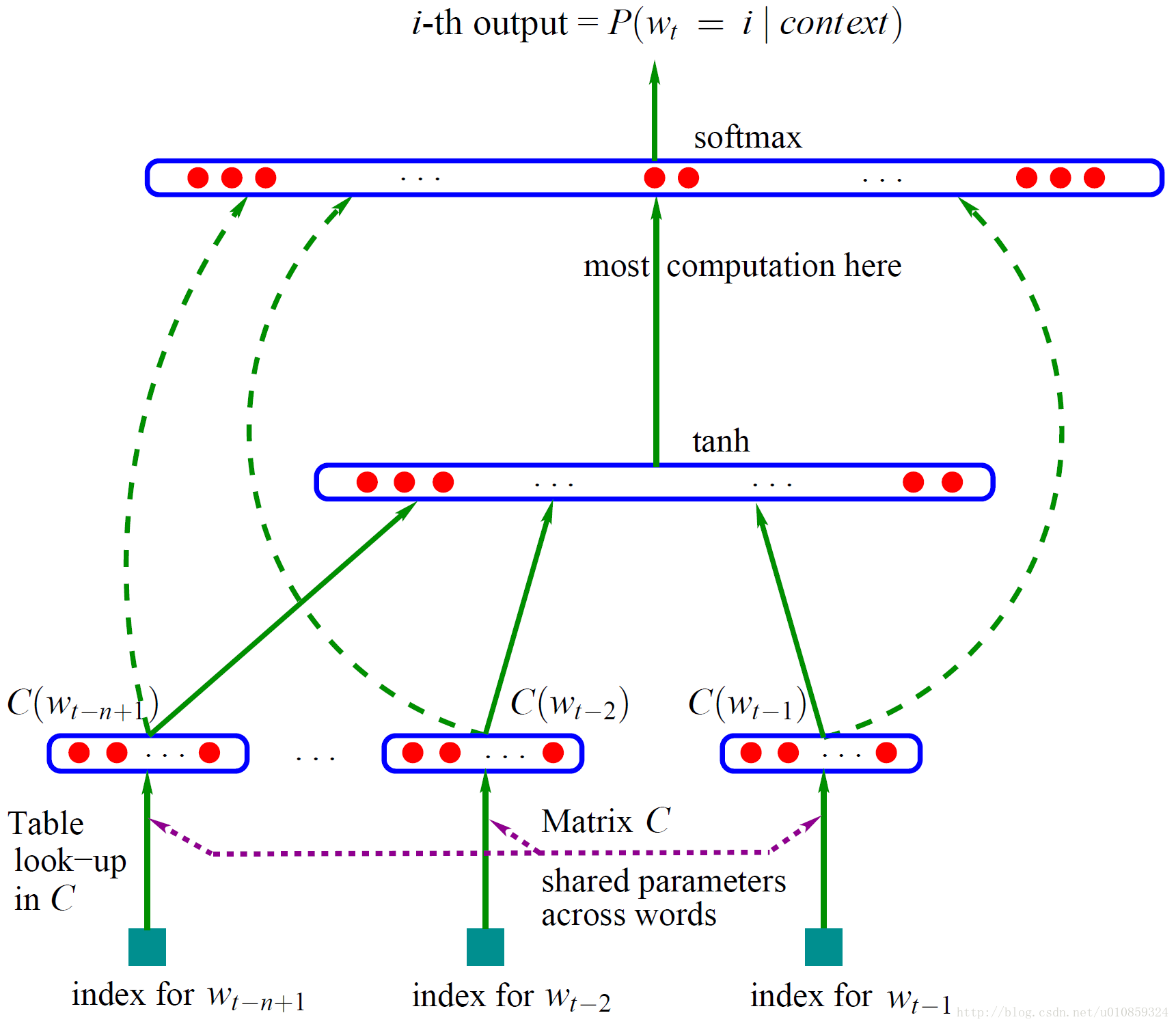
神经网络架构为,
用one-hot representation的方式,把前n-1个词表示成词向量(|V|维) ——> 经过矩阵C(shared parameters,|V|*m维),转换成低维的向量(m维) ——> 将n-1个m维向量拼接在一起,形成一个(n-1)*m维的向量x ——> 对x进行非线性变换,tanh(d+Hx) ——> 计算y(|V|维),y=b+Wx+Utanh(d+Hx),除了非线性变换项之外,还加入了输入层到输出层的直连边(所以reset的high way connected思想是不是借鉴的这个?) ——> 通过softmax输出概率值。
特点:
整个过程进行了两次矩阵乘,两次非线性变换,参数多,计算量大;
词与词间向量的加权和预测概率,不能充分抓住词向量的相似性。
- word2vec
1)skip-gram
利用中心词去预测附近的词,架构如下图所示。
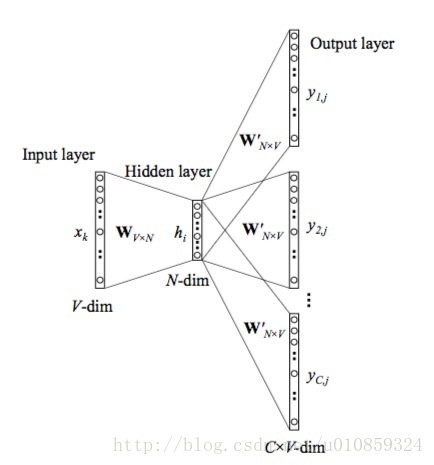
这里的W是同一个(parameters shared)。隐藏层(hidden layer)的输出即为要求的词向量。
利用最大似然估计的思想,使得条件概率最大
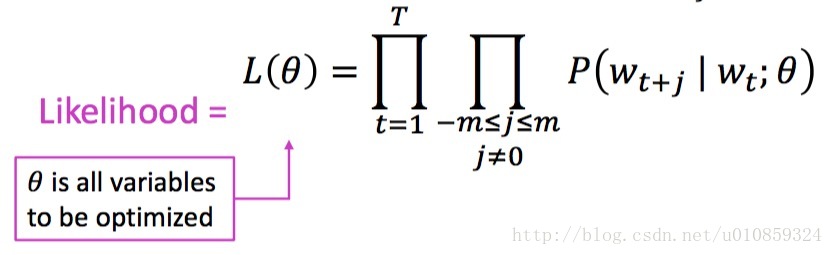
神经网络的loss function为
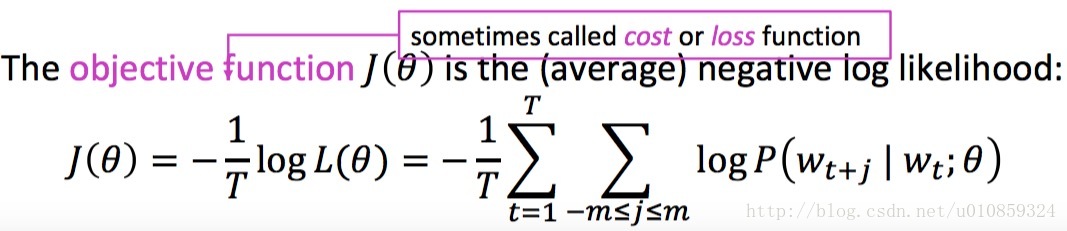
这里的条件概率p的定义和基于counting的n-gram不同,是利用词向量来定义条件概率。定义的方法为
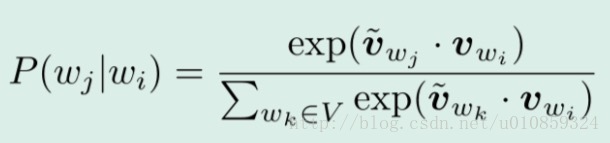
分母部分,在每一个窗口,都要计算中心词和全部词的相似度,计算量巨大。采用negative sampling技术解决这一问题。
参数的更新迭代使用梯度下降的方法,单独拿出一个中心词和一个窗口内的词组成对,来研究参数的更新过程。
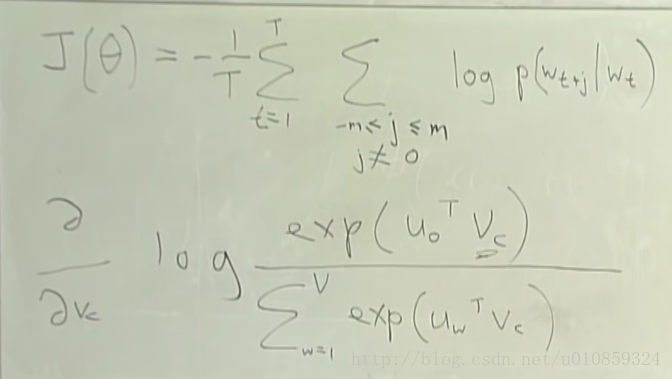
其中Vc为中心词向量,Uo为窗口内词向量。
对Vc求导的结果为
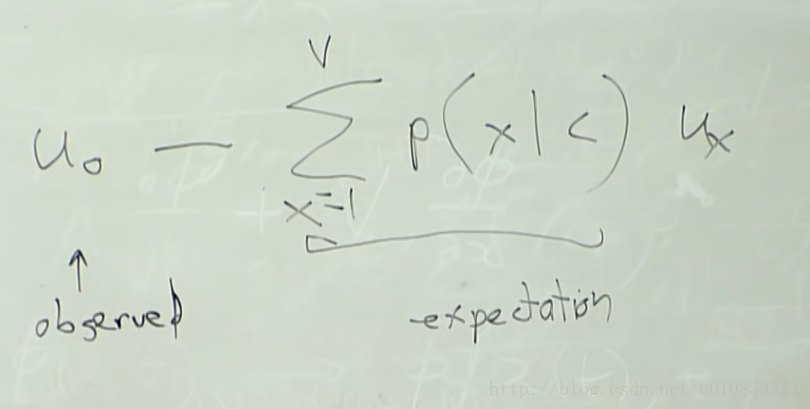
可见,损失函数对Vc的梯度为窗口内的实际出现的词向量减去窗口内可能出现的词向量加权和。
损失函数对Uo的梯度计算是类似的,不再赘述。
上述参数更新过程存在的问题是,由于整个词库非常庞大,导致计算上图中”expectation”项时计算量过大,为了解决这一问题,采用negative sampling做法,从全集中随机采集若干个词作为负样本,损失函数变为

2)CBOW
利用附近的词去预测中心词,架构如下图所示。
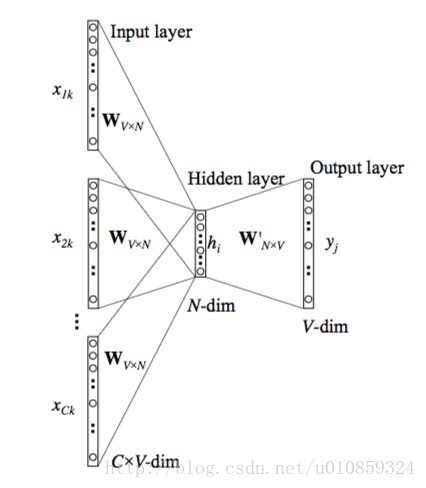
在模型中会同时应用这两种算法进行计算,最后把得到的词向量做算术平均。
三、GloVe模型
word2vec没有考虑词序,以及全局统计信息,GloVe试图解决这两个问题。

计算过程需要对整个语料扫描两遍,第一遍做统计,得到Pij,第二遍则扫描每个共现的词对时更新u_i、v_j。
其实,GloVe可以归入到统计语言模型大类中,因为整个框架并没有神经网路。
具体实现可以参考这篇博客
http://blog.csdn.net/coderTC/article/details/73864097