根据慢日志定位慢查询sql
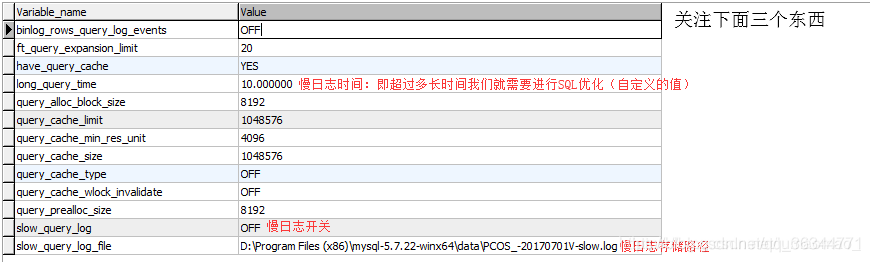
我们可以通过如下语句查询MySQL对数据库慢查询的设置
show variables like ‘%query%’
修改设置
set global slow_query_log = on;--设置慢查询日志为开启状态
set global long_query_time = 1;--设置慢查询日志时间阈值为1s
这样我们就会记录下所有运行时间超过1s的SQL语句,可以在上述的慢日志存储路径中查看
我们先来制造一个慢查询用到的数据库(共40W条数据)
public class SlowqueryTest {
public static Connection getConnection() {
Connection conn;
try {
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
try {
String url = "jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8";
String user = "root";
String pwd = "数据库密码";
conn = DriverManager.getConnection(url, user, pwd);
} catch (SQLException e) {
e.printStackTrace();
conn = null;
}
return conn;
}
public static void main(String[] args) {
Connection conn = getConnection();
String sql = null;
Random rand = new Random();
try {
Statement stat = conn.createStatement();
for (int i = 0; i < 200000; i++) {
System.out.println(i);
int x = rand.nextInt(100000);
// sql = "insert into slowquerytest values(default,'光头" + i +
// "')";
// sql = "insert into slowquerytest values(default,'有头发" + i +
// "')";
sql = "insert into slowquerytest values(default,'流浪" + x + "')";
stat.execute(sql);
}
} catch (Exception e) {
// TODO: handle exception
}
}
}
什么是联合索引的最左匹配原则
最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a=3 and b=4 and c>5 and d=6 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以仼意调整。
=和in可以乱序,比如a=1 and b=2 and c=3 建立(a,b,c)索引可以任意顺序,mysq的查询优化器会帮你优化成索引可以识别的形式
成因
MySQL创建符合索引的规则是:首先会对复合索引的最左边(第一个索引)字段的数据进行排序(第一个字段绝对有序)
在对第一个字段排序的基础上,在对第二个字段进行排序(第二个字段相对于第一个字段有序,事实上它本身是无序的,这就是为什么他不能越过第一个字段来使用符合索引的原因了)
依次类推
数据库索引什么时候会失效
如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因)
对于多列索引,不是使用的第一部分,则不会使用索引
like查询是以%开头
如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
如果mysql估计使用全表扫描要比使用索引快,则不使用索引
