读取csv文件且用到for的双层循环
在最近读取一个百万级数据量的csv文件时,为了对其进行数据的整合,用到了双层循环,但是结果差强人意,除了第一批数据可以正常处理,剩下的读取不到,经过测试发现了问题
一丶发现问题
为了方便的处理数据,首先对数据进行了预处理,提取出id
id_union = [776001, 776002, 776003, 776004, 776005, 776006, 776007, 776008, 776009, 776013, 776016, 776018, 776021,776030, 776031, 776032, 776033, 776034, 776035, 776999]
读取数据及双循环处理
with open('model_3.csv', 'r') as f:
initial_data = csv.reader(f)
lv_ranks = {}
for node_id in id_union:
lv_ranks['lv_' + str(node_id)] = []
for i in initial_data:
if i[5] == str(node_id):
lv_ranks['lv_' + str(node_id)].append(float(i[6]))
# print(lv_ranks)
上面的打印结果除了第一个id的key是有value的,后面的均为空,为什么会出现问题,完全找不到头绪,首先双层循环不存在死循环,不存在字典重置,其次我将双层循环改成单层循环,数据均能正确的拿出,说明if判断没有问题,陷入了一个两难的局面,百度也没有找到想要的答案
二丶尝试解决
这个问题说到底就是两个列表的遍历,由于数据量较大,在运行发现的问题难以得到处理,于是我将两个列表精简到最简,并重现了双层循环的过程
a = ["1", "2", "3", "4", "5"]
b = [(1, "1"), (2, "2"), (3, "3"), (4, "4"), (5, "5")]
c = {}
for i in a:
c[i] = []
for j in b:
if j[1] == i:
c[i].append(j[0])
print(c)
上面的这个代码段打印的结果与预期相同,于是我隐约猜到了出现问题的原因,接着进行了尝试
with open('model_3_预测1月.csv', 'r') as f:
initial_data = csv.reader(f)
initial_data = list(initial_data)
lv_ranks = {}
for node_id in id_union:
lv_ranks['lv_' + str(node_id)] = []
for i in initial_data:
if i[5] == str(node_id):
lv_ranks['lv_' + str(node_id)].append(float(i[6]))
# print(lv_ranks)
上述我将读取到的csv结果,转化成了list列表,果真解决了问题,此时我还不知道原因
三丶问题总结
这里涉及到类型转换,说明读取到的csv文件的结果并不是list类型,但一定是可迭代类型,打印了下csv读取结果的数据类型 
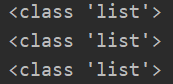
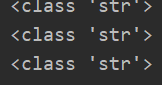
显而易见并不是list类型的数据,但遍历时,每一行数据又是一个列表,列表中每一个数据又以字符串的类型存在,在这个问题里,需要将其转化成list类型,以完成双层循环。
对于为什么要这么操作,我没搞明白,应该是因为csv的数据类型不能进行二次循环,或者进入循环读取时数据类型与之前不一致,经过几个小时的纠结,也算是解决了问题