正则表达式到底是什么东西?
在编写处理字符串的程序或网页时,经常会有查找符合某些复杂规则的字符串的需要。正则表达式就是用于描述这些规则的工具。换句话说,正则表达式就是记录文本规则的代码。
我们都使用过Windows/Dos下用于文件查找的通配符,也就是*和?。
如果你想查找某个目录下的所有的Word文档的话,你会搜索*.doc。
在这里,*会被解释成任意的字符串。
和通配符类似,正则表达式也是用来进行文本匹配的工具,只不过比起通配符,它能更精确地描述你的需求
——当然,代价就是更复杂
——比如你可以编写一个正则表达式,用来查找所有以0开头,后面跟着2-3个数字,然后是一个连字号“-”,最后是7或8位数字的字符串(像010-12345678或0376-7654321)。
http://tool.oschina.net/regex/:正则表达式在线验证
1.正则表达式基本语法
两个特殊的符号'^'和'$'。他们的作用是分别指出一个字符串的开始和结束。例子如下:
"^The":表示所有以"The"开始的字符串("There","The cat"等);
"of despair$":表示所以以"of despair"结尾的字符串;
"^abc$":表示开始和结尾都是"abc"的字符串——只有"abc"自己了;
"notice":表示任何包含"notice"的字符串。
如果你不使用两个特殊字符,你就在表示要查找的串在被查找串的任意部分——你并不把它定位在某一个顶端。
其它还有 '*','+'和'?' 这三个符号,表示一个或多个字符重复出现的次数。
它们分别表示“没有或更多”,“一次或更多”还有“没有或一次”。下面是几个例子:
"ab*":表示一个字符串有一个a后面跟着零个或若干个b。("a", "ab", "abbb",……);
"ab+":表示一个字符串有一个a后面跟着至少一个b或者更多;
"ab?":表示一个字符串有一个a后面跟着零个或者一个b;
"a?b+$":表示在字符串的末尾有零个或一个a跟着一个或几个b。
你也可以使用范围,用大括号括起,用以表示重复次数的范围。
"ab{2}":表示一个字符串有一个a跟着2个b("abb");
"ab{2,}":表示一个字符串有一个a跟着至少2个b;
"ab{3,5}":表示一个字符串有一个a跟着3到5个b。
请注意,你必须指定范围的下限(如:"{0,2}"而不是"{,2}")。还有,你可能注意到了,'*','+'和'?'相当于"{0,}","{1,}"和"{0,1}"。
还有一个'|',表示“或”操作:
"hi|hello":表示一个字符串里有"hi"或者"hello";
"(b|cd)ef":表示"bef"或"cdef";
"(a|b)*c":表示一串"a""b"混合的字符串后面跟一个"c";
方括号表示某些字符允许在一个字符串中的某一特定位置出现:
"[ab]":表示一个字符串有一个"a"或"b"(相当于"a|b");
"[a-d]":表示一个字符串包含小写的'a'到'd'中的一个(相当于"a|b|c|d"或者"[abcd]");
"^[a-zA-Z]":表示一个以字母开头的字符串;
"[0-9]%":表示一个百分号前有一位的数字;
",[a-zA-Z0-9]$":表示一个字符串以一个逗号后面跟着一个字母或数字结束。
你也可以在方括号里用'^'表示不希望出现的字符,
'^'应在方括号里的第一位。(如:"%[^a-zA-Z]%"表示两个百分号中不应该出现字母)。
如果表示特殊字符本身,你必须在"^.$()|*+?{\"这些字符前加上转移字符'\'。
'.'可以替代任意的一个字符:
"a.[0-9]":表示一个字符串有一个"a"后面跟着一个任意字符和一个数字;
"^.{3}$":表示有任意三个字符的字符串(长度为3个的字符);
常用的一些表达式的简写:

java中怎么使用正则表达式:
1、匹配验证-验证Email是否正确
public class Demo { public static void main(String[] args) { //写一个程序,验证一下输入的字符串,是不是一个合法的邮箱地址 //要验证的字符串 String email = "[email protected]"; //邮箱验证规则 String regEx = "[\\w!#$%&'*+/=?^_`{|}~-]+(?:\\.[\\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])?"; //编译正则表达式 Pattern pattern = Pattern.compile(regEx); //忽略大小写的写法 Pattern pat = Pattern.compile(regEx,Pattern.CASE_INSENSITIVE); Matcher matcher = pattern.matcher(email); //字符串是否与正则表达式相匹配 boolean rs = matcher.matches(); System.out.println(rs); //true } }
2、在字符串中查询字符或者字符串
public class Demo { public static void main(String[] args) { //写一个程序,验证一下输入的字符串,是不是一个合法的邮箱地址 //要验证的字符串 String email = "[email protected]"; //邮箱验证规则 String regEx = "[\\w!#$%&'*+/=?^_`{|}~-]+(?:\\.[\\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])?"; String newstr = email.replaceAll(regEx, "aaaa"); System.out.println(newstr); //true } }
//找到了,还可以进一步的替换
}
3、常用正则表达式
| 规则 |
正则表达式语法 |
| 一个或多个汉字 |
^[\u0391-\uFFE5]+$ |
| 邮政编码 |
^[1-9]\d{5}$ |
| QQ号码 |
^[1-9]\d{4,10}$ |
| 邮箱 |
^[A-Za-z\\d]+([-_.]|[A-Za-z\\d]+)*@([A-Za-z\\d]+|[-.])+\\.[A-Za-z\\d]{2,4}$ |
| 用户名(字母开头 + 数字/字母/下划线) |
^[A-Za-z][A-Za-z1-9_]+$ |
| 手机号码 |
^1[3|4|5|8][0-9]\d{8}$ |
| URL |
^((http|https)://)?([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$ |
| 18位身份证号 |
^(\d{6})(18|19|20)?(\d{2})([01]\d)([0123]\d)(\d{3})(\d|X|x)?$ |
背景知识
现代软件开发,往往做出的应用程序不止给一个国家的人去使用。不同国家的人往往存在语言文字不通的问题。由此产生了国际化(internationalization)、多语言(multi-language)、本地化(locale)这些词,它们其实都是一个意思,支持多种语言,提供给不同国家的用户使用。
语言编码、国家/地区编码
我们多多少少接触过类似 zh-CN, en-US 这样的编码字样。
这些编码是用来表示指定的国家地区的语言类型的。那么,这些含有特殊含义的编码是如何产生的呢?
ISO-639标准使用编码定义了国际上常见的语言,每一种语言由两个小写字母表示。
ISO-3166标准使用编码定义了国家/地区,每个国家/地区由两个大写字母表示。
规定用语言+国家/地区来标示语言,为什么?
道理很简单:拿咱们中国来说,同样是中文,全国各地的方言就多如牛毛,更不要说世界上有那么多种语言,得有多少方言?
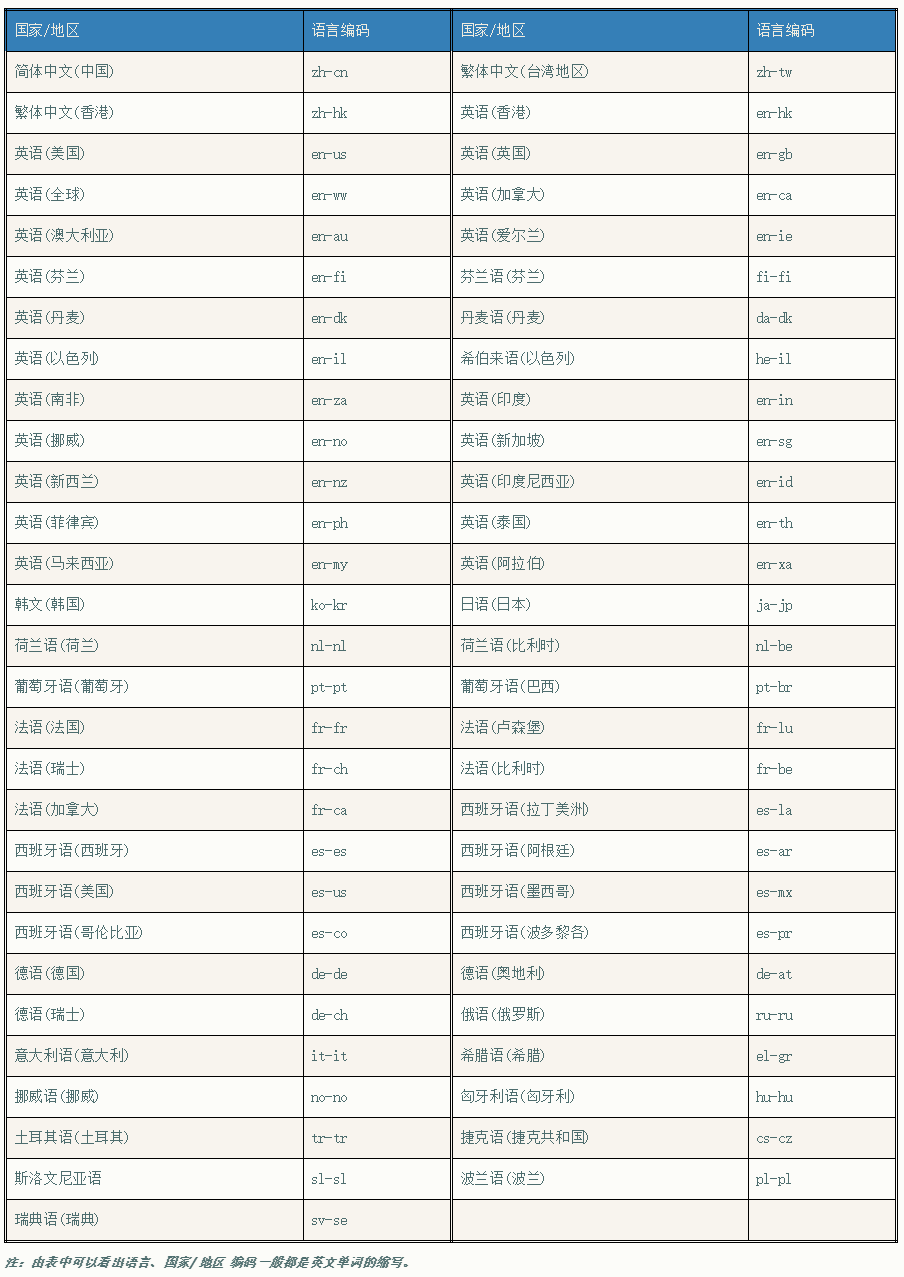
下表列举了一些常见国家、地区的语言编码:
字符编码
在此处,引申一下字符编码的概念。
是不是有了语言、国家/地区编码,计算机就可以识别各种语言了?
答案是否。作为程序员,相信每个人都会遇到过这样的情况:期望打印中文,结果输出的却是乱码。
这种情况,往往是因为字符编码的问题。
计算机在设计之初,并没有考虑多个国家,多种不同语言的应用场景。当时定义一种ASCII码,将字母、数字和其他符号编号用7比特的二进制数来表示。后来,计算机在世界开始普及,为了适应多种文字,出现了多种编码格式,例如中文汉字一般使用的编码格式为GB2312、GBK。
由此,又产生了一个问题,不同字符编码之间互相无法识别。于是,为了一统江湖,出现了 unicode编码。它为每种语言的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台的文本转换需求。
有人不禁要问,既然 Unicode 可以支持所有语言的字符,那还要其他字符编码做什么?
Unicode 有一个缺点:为了支持所有语言的字符,所以它需要用更多位数去表示,比如ASCII表示一个英文字符只需要一个字节,而 Unicode 则需要两个字节。很明显,如果字符数多,这样的效率会很低。
为了解决这个问题,有出现了一些中间格式的字符编码:如UTF-8、UTF-16、UTF-32等。中国程序员一般使用UTF-8编码。
在这里提到了,为了达到跨编码也正常显示的目的,有必要将非ASCII 字符转为 Unicode 编码。上面的中文转为 Unicode。
Unicode 转换工具
JDK在bin目录下为我们提供了一个Unicode 转换工具:native2ascii。
它可以将中文字符的资源文件转换为Unicode代码格式的文件,命令格式如下:
native2ascii [-reverse] [-encoding 编码] [输入文件 [输出文件]]
例:
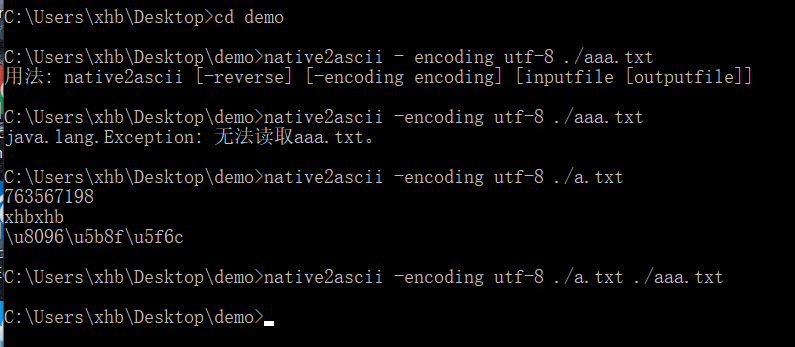
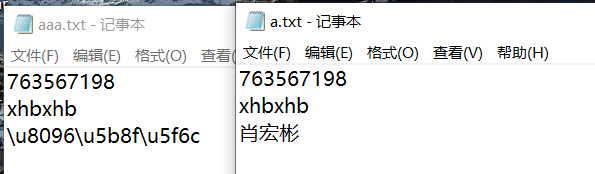
假设content_zh_CN.properties 在d:\ 目录。执行以下命令可以新建 content_zh_CN_new.properties ,其中的内容就所有中文字符转为 UTF-8 编码格式的结果。
native2ascii -encoding utf-8 d:\content_zh_CN.properties d:\content_zh_CN_new.properties
国际化的 Java 实现
1.定义 properties
实现国际化,归根结底就是根据语言类型去定义好字符串模板而已。
Java 中的多语言字符串模板一般保存在properties资源文件中。
它必须遵照以下的命名规范:
<资源名>_<语言代码>_<国家/地区代码>.properties

其中,语言代码和国家/地区代码都是可选的。
<资源名>.properties命名的国际化资源文件是默认的资源文件,即某个本地化类型在系统中找不到对应的资源文件,就采用这个默认的资源文件。
例:
定义中英文两种多语言资源文件,将其置于com.notes.locale.resources 路径下。
content_en_US.properties:
helloWorld = HelloWorld!
time = Thecurrenttimeis%s.
content_zh_CN.properties
helloWorld = \u4e16\u754c\uff0c\u4f60\u597d\uff01
time = \u5f53\u524d\u65f6\u95f4\u662f\u0025\u0073\u3002
可以看到,两种语言的Key 完全一致,只是 Value 是对应语言的字符串。
本地化不同的同一资源文件,虽然属性值各不相同,但属性名却是相同的,这样应用程序就可以通过Locale对象和属性名精确调用到某个具体的属性值了。
2.加载资源文件
定义了多语言资源文件,下一步就是加载资源文件了。
Java为我们提供了用于加载本地化资源文件的工具类:java.util.ResourceBoundle。
Java为我们提供了可以包含当前语言环境或全部公共语言环境的信息的类:Locale
具体的使用方式:
import java.time.Instant; import java.time.LocalDate; import java.time.Period; import java.time.YearMonth; import java.time.format.DateTimeFormatter; import java.util.Date; import java.util.Locale; import java.util.ResourceBundle; import java.util.regex.Matcher; import java.util.regex.Pattern; public class Demo { public static void main(String[] args) { Locale localeEn = new Locale("en","US");//包含英文环境的信息 Locale localeZh = new Locale("zh","CN");//包含中文环境的信息 ResourceBundle rbEn = ResourceBundle.getBundle("aaa.content",localeEn); ResourceBundle rbZh = ResourceBundle.getBundle("aaa.content",localeZh); System.out.println("En:"+rbEn.getString("username"));// System.out.println("Zh:"+rbZh.getString("username")); } }
需要强调说明的是:ResourceBundle类的 getBundle方法第一个参数 baseName需要输入的是资源文件的package路径 + 文件前缀。
以本文例子来说,content_zh_CN.properties 和content_en_US.properties 的baseName 都是:com.notes.locale.resources.content。
在加载资源时,如果指定的本地化资源文件不存在,它会尝试按下面的顺序加载其他的资源:本地系统默认本地化对象对应的资源-> 默认的资源。如果指定错误,Java 会提示找不到资源文件。