python的正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
用前得先引用re模块 import re
re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
re.match(pattern, string, flags=0)
匹配的的正则表达式 ,匹配的字符串,匹配方式
#!/usr/bin/python3 import re line = "Cats are smarter than dogs" # .* 表示任意匹配除换行符(\n、\r)之外的任何单个或多个字符 matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I) if matchObj: print ("matchObj.group() : ", matchObj.group()) print ("matchObj.group(1) : ", matchObj.group(1)) print ("matchObj.group(2) : ", matchObj.group(2)) else: print ("No match!!")
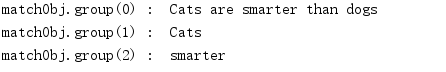
matchObj.groups() 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
matchObj.group(num=0) 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。
re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string, flags=0)
与re.math类似,但re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
re.sub
re.sub用于替换字符串中的匹配项。
re.sub(pattern, repl, string, count=0, flags=0)
正则中的模式字符串,替换的字符串, 要被查找替换的原始字符串,模式匹配后替换的最大次数,编译时用的匹配模式
#!/usr/bin/python3 import re phone = "2004-959-559 # 这是一个电话号码" # 删除注释 num = re.sub(r'#.*$', "", phone) print ("电话号码 : ", num) # 移除非数字的内容 num = re.sub(r'\D', "", phone) print ("电话号码 : ", num)
![]()
findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
re.findall(string[, pos[, endpos]])
待匹配的字符串,可选参数,指定字符串的起始位置,默认为 0。,可选参数,指定字符串的结束位置,默认为字符串的长度。
爬虫一般用这个
re.split
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
re.split(pattern, string[, maxsplit=0, flags=0])
匹配的正则表达式,要匹配的字符串,分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数。,标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
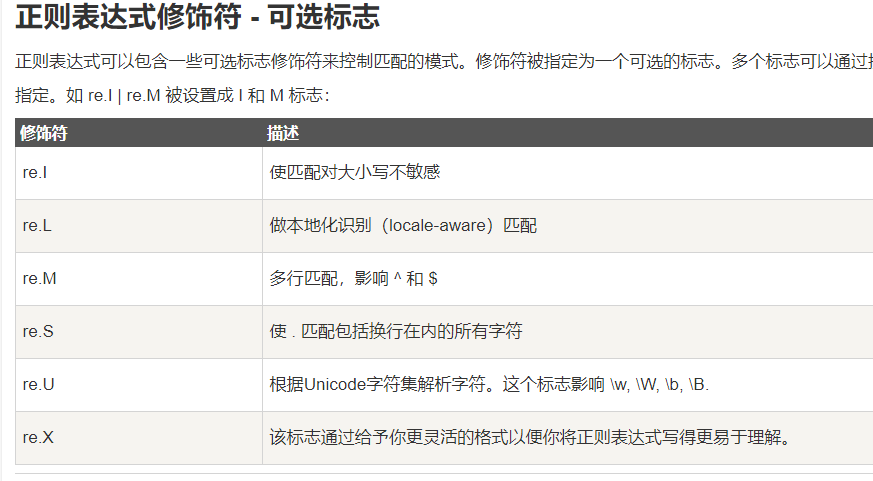
https://www.runoob.com/python3/python3-reg-expressions.html#flags 介绍正则表达式