数据清洗
首先导入所需要的模块
from pandas import DataFrame,Series
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
处理缺失值、填充缺失值
DataFrame中,isnull、notnull方法
info方法、dropna方法、fillna方法
# 创建有缺失值的数据
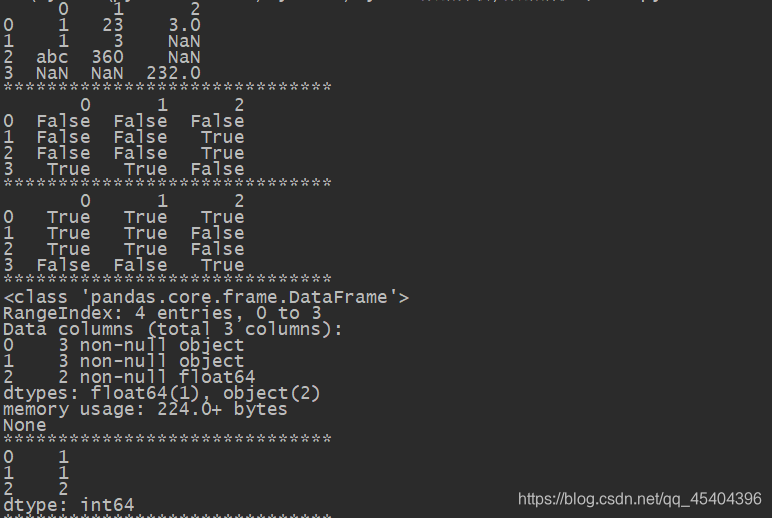
df_1=DataFrame([[1,23,3],[1,3,np.nan],['abc','360',np.nan],[np.nan,np.nan,232]])
print(df_1)
print('*'*30)
# 查看缺失值
print(df_1.isnull())
print('*'*30)
print(df_1.notnull())
# 通过info方法,可以查看DataFrame每列数据的缺失值情况
print('*'*30)
print(df_1.info())
print('*'*30)
print(df_1.isnull().sum())
print('*'*30)
print(df_1.isnull().sum().sum())
print('\n')
# 删除有缺失值的数据
# dropna方法可以删除有缺失值的行
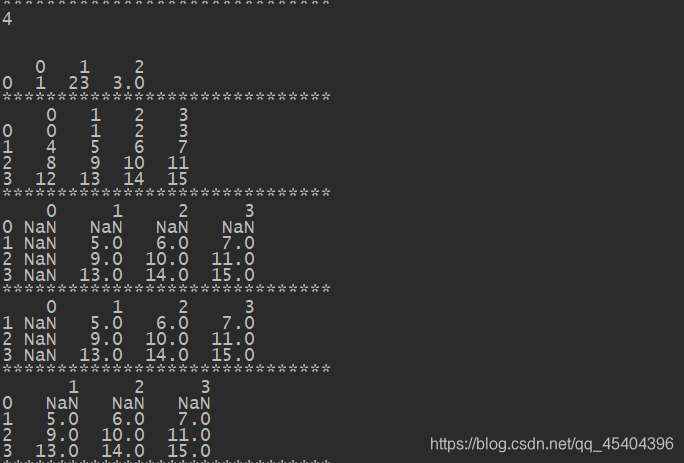
print(df_1.dropna())
# 传入how="all",则只会删除全为NaN的那些行
print('*'*30)
df_2=DataFrame(np.arange(16).reshape(4,4))
print(df_2)
print('*'*30)
df_2.iloc[0]=np.nan
df_2[0]=np.nan
print(df_2)
print('*'*30)
print(df_2.dropna(how='all'))
# 如果要删除列,则axis=1即可
print('*'*30)
print(df_2.dropna(how="all",axis=1))
# 填充缺失值
print('*'*30)
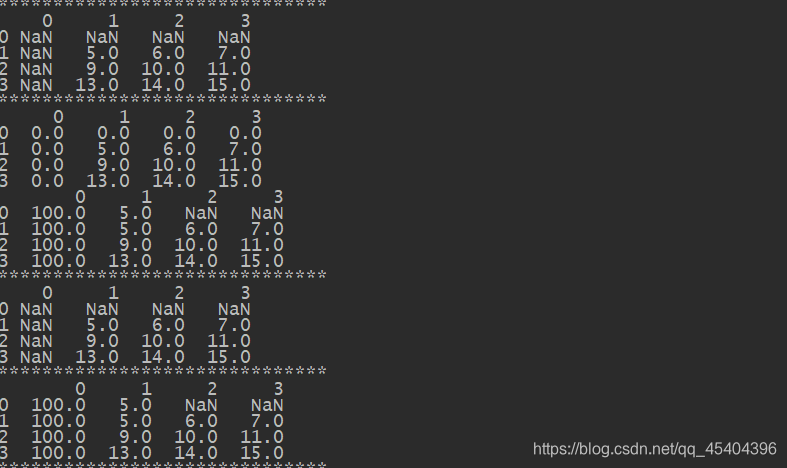
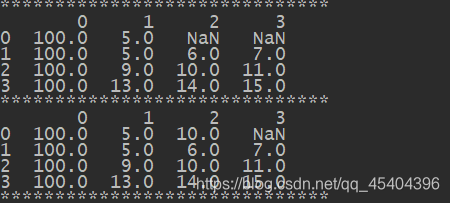
print(df_2)
print('*'*30)
print(df_2.fillna(0))
# 再fillna中传入字典结构数据,可以针对不同列填充不同的数据
print(df_2.fillna({1:5,0:100}))
print('*'*30)
print(df_2)
print('*'*30)
# 也可以通过inplace进行修改
df_2.fillna({1:5,0:100},inplace=True)
print(df_2)
print('*'*30)
# print(df_2.fillna(method='ffill'))
print(df_2)
print('*'*30)
df_2[2].fillna(df_2[2].mean(),inplace=True)
print(df_2)
运行结果:
替换值
datas={
'name':['小明','小张','小芳','小李'],
'adress':['上海','南京','','上海'],
'year':[2001,2001,'',2004]
}
df_4=DataFrame(data=datas)
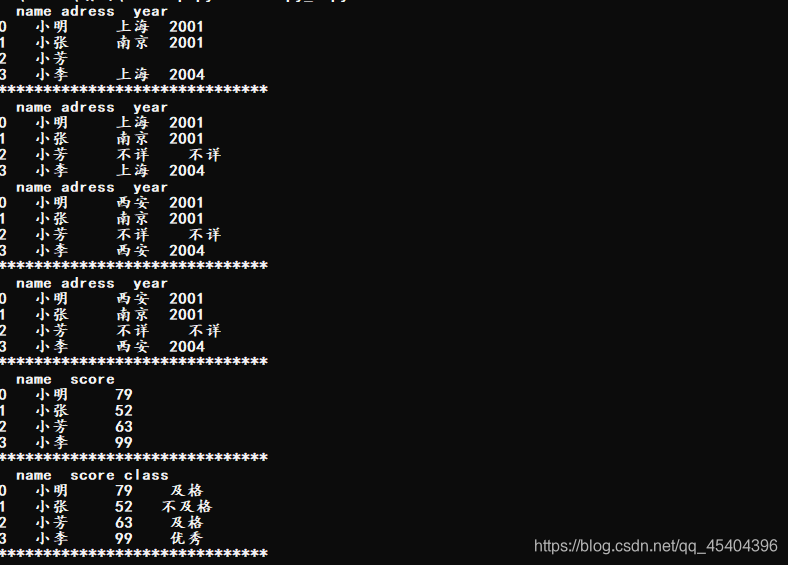
print(df_4)
print('*'*30)
print(df_4.replace('','不详'))
# 也可以针对不同值进行多值替换,参数传入可以使列表也可以是字典
print(df_4.replace(['','上海'],['不详','西安']))
print('*'*30)
print(df_4.replace({'':'不详','上海':'西安'}))
print('*'*30)
# 利用函数或映射进行数据转换
data={
'name':['小明','小张','小芳','小李'],
'score':[79,52,63,99]
}
df_5=DataFrame(data=data)
print(df_5)
print('*'*30)
def f(x):
if x>=90:
return '优秀'
elif x>=80:
return '良好'
elif x>=60:
return '及格'
else:
return '不及格'
df_5['class']=df_5['score'].map(f)
print(df_5)
print('*'*30)
运行结果:
检测异常值
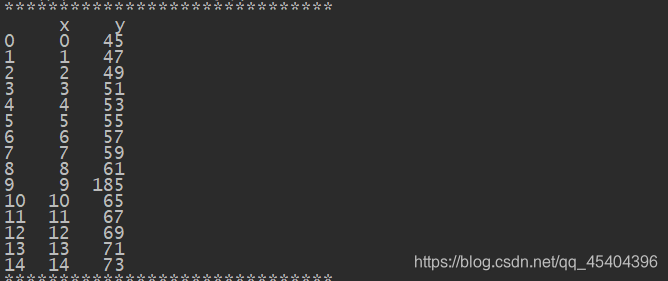
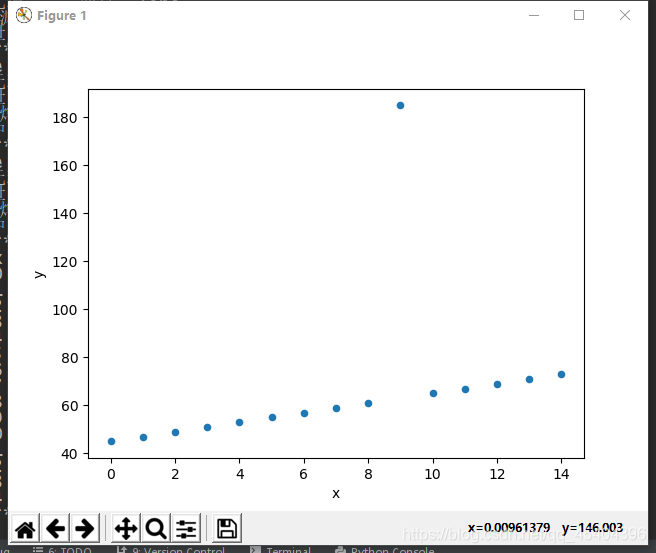
df_6=DataFrame(np.arange(15),columns=['x'])
df_6['y']=2*df_6['x']+45
df_6.iloc[9,1]=185
print(df_6)
print('*'*30)
df_6.plot(kind='scatter',x='x',y='y')
plt.show()
运行结果:
虚拟变量
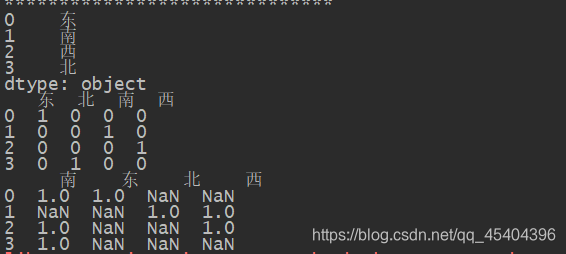
df_7=Series(['东','南','西','北'])
print(df_7)
print(pd.get_dummies(df_7))
df_8=Series(['东.南','西.北','西.南','南'])
df_8_1=df_8.apply(lambda x:Series(x.split('.')).value_counts())
print(df_8_1)