(Principles of training multi-layer neural network using backpropagation)
使用反向传播训练多层神经网络的原则
(The project describes teaching process of multi-layer neural network employing backpropagation algorithm. To illustrate this process the three layer neural network with two inputs and one output,which is shown in the picture below, is used: )
该项目描述了采用反向传播算法的多层神经网络的教学过程。 为了说明这个过程,使用了如下图所示的具有两个输入和一个输出的三层神经网络:
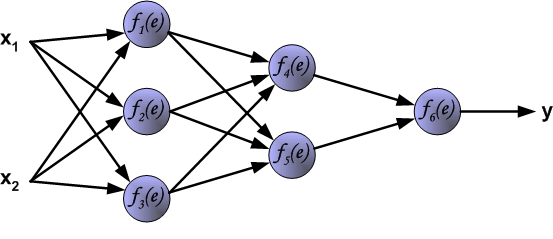
(Each neuron is composed of two units. First unit adds products of weights coefficients and input signals. The second unit realise nonlinear function, called neuron activation function. Signal e is adder output signal, and y = f(e) is output signal of nonlinear element. Signal y is also output signal of neuron. )
每个神经元由两个单元组成。 第一单元添加权重系数和输入信号的乘积。 第二个单元实现非线性函数,称为神经元激活函数。 信号e是加法器输出信号,y = f(e)是非线性元件的输出信号。 信号y也是神经元的输出信号。
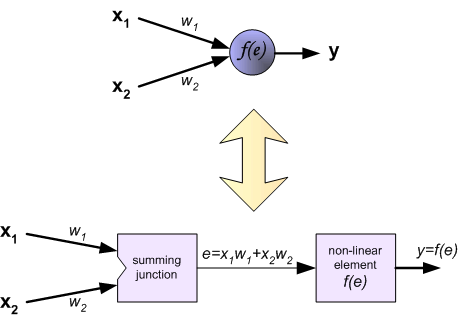
(To teach the neural network we need training data set. The training data set consists of input signals (x1 and x2 ) assigned with corresponding target (desired output) z. The network training is an iterative process. In each iteration weights coefficients of nodes are modified using new data from training data set. Modification is calculated using algorithm described below: Each teaching step starts with forcing both input signals from training set. After this stage we can determine output signals values for each neuron in each network layer. Pictures below illustrate how signal is propagating through the network, Symbols w(xm)n represent weights of connections between network input xm and neuron n in input layer. Symbols yn represents output signal of neuron n. )
为了训练神经网络,我们需要训练数据集。 训练数据集由分配有相应目标(期望输出)z的输入信号(x1和x2)组成。 网络训练是一个迭代过程。 在每次迭代中,使用来自训练数据集的新数据修改节点的权重系数。 使用下面描述的算法计算修改量:每个训练教学步骤从强制来自训练集的两个输入信号开始。 在这个阶段之后,我们可以确定每个网络层中每个神经元的输出信号值。 下面的图片说明信号如何通过网络传播,符号w(xm)n表示输入层网络输入xm和神经元n之间的连接权重。 符号yn表示神经元n的输出信号。

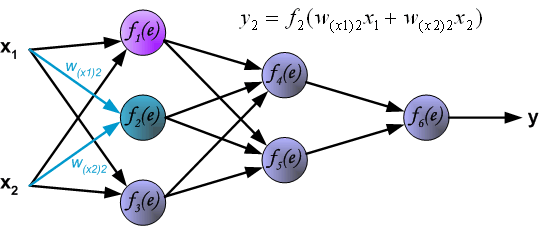

(Propagation of signals through the hidden layer. Symbols wmn represent weights of connections between output of neuron m and input of neuron n in the next layer. )
通过隐藏层传播信号。 符号wmn表示神经元m的输出与下一层神经元n的输入之间的连接权重。
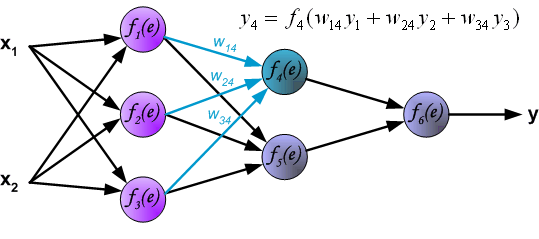

(Propagation of signals through the output layer. )
通过输出层传播信号。
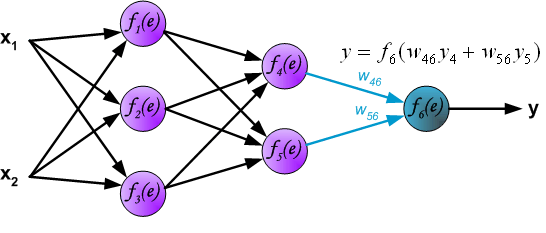
(In the next algorithm step the output signal of the network y is compared with the desired output value (the target), which is found in training data set. The difference is called error signal d of output layer neuron. )
在下一个算法步骤中,将网络y的输出信号与在训练数据集中发现的期望输出值(目标)进行比较。 差异称为输出层神经元的误差信号delta。
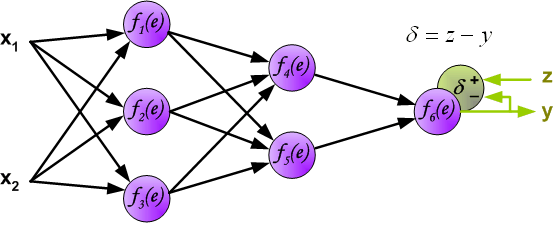
(It is impossible to compute error signal for internal neurons directly, because output values of these neurons are unknown. For many years the effective method for training multiplayer networks has been unknown. Only in the middle eighties the backpropagation algorithm has been worked out. The idea is to propagate error signal delta (computed in single teaching step) back to all neurons, which output signals were input for discussed neuron. )
不可能直接计算内部神经元的误差信号,因为这些神经元的输出值是未知的。 多年来,多层网络训练的有效方法一直未知。 只有在八十年代中期,反向传播算法才被制定出来。 这个想法是将误差信号delta(在单个教学步骤中计算)传播回所有神经元,为所讨论的神经元输入输出信号。
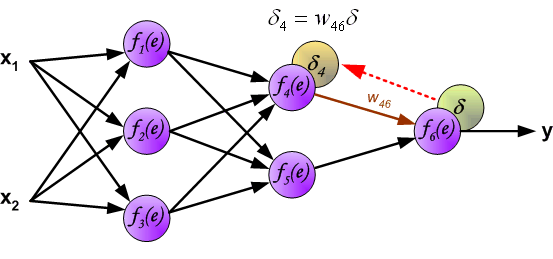

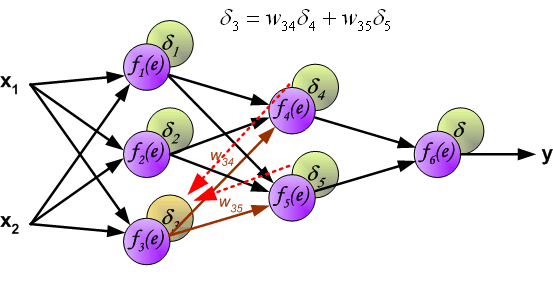
(The weights' coefficients wmn used to propagate errors back are equal to this used during computing output value. Only the direction of data flow is changed (signals are propagated from output to inputs one after the other). This technique is used for all network layers. If propagated errors came from few neurons they are added. The illustration is below: )
用于传播错误的权重系数wmn等于在计算输出值期间使用的系数。 只有数据流的方向发生改变(信号从一个接一个地传输到输入端)。 该技术用于所有网络层。 如果传播的错误来自它们添加的少数神经元。 插图如下:

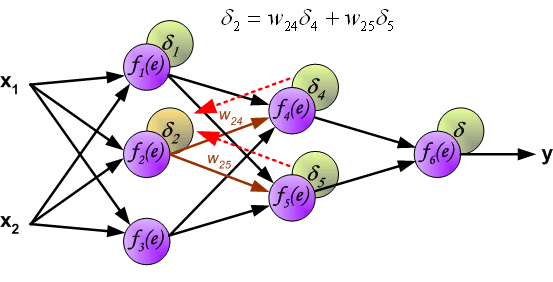
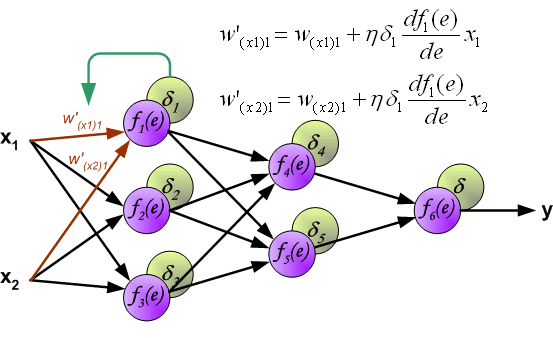
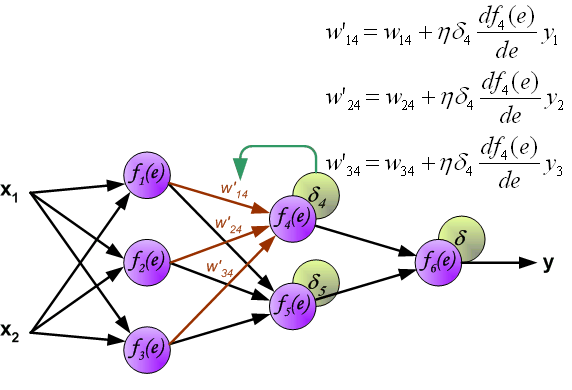
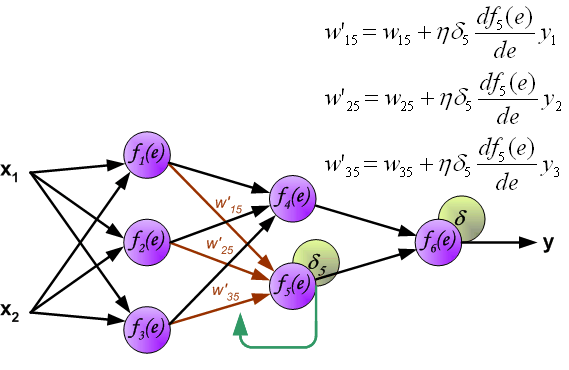
(When the error signal for each neuron is computed, the weights coefficients of each neuron input node may be modified. In formulas below df(e)/de represents derivative of neuron activation function (which weights are modified). )
当计算每个神经元的误差信号时,可以修改每个神经元输入节点的加权系数。 在下面的公式中,df(e)/de表示神经元激活函数的导数(其权重被修改)。


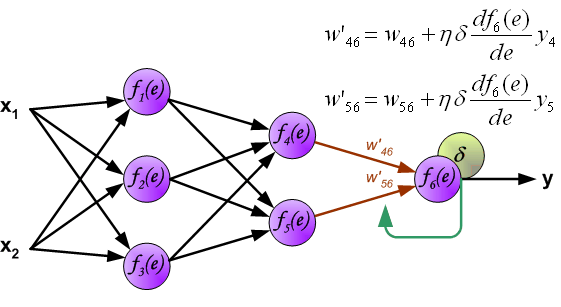
(Coefficient h affects network teaching speed. There are a few techniques to select this parameter. The first method is to start teaching process with large value of the parameter. While weights coefficients are being established the parameter is being decreased gradually. The second, more complicated, method starts teaching with small parameter value. During the teaching process the parameter is being increased when the teaching is advanced and then decreased again in the final stage. Starting teaching process with low parameter value enables to determine weights coefficients signs. )
系数h(原文为eta)影响网络教学速度。 有几种技术可以选择这个参数。 第一种方法是以大参数值开始教学过程。 在建立权重系数的同时,参数逐渐减少。 第二种更复杂的方法是以小参数值开始教学。 在教学过程中,参数在教学提前时增加,然后在最后阶段再次降低。 以低参数值开始教学过程可以确定加权系数符号。
参考文献:Ryszard Tadeusiewcz "Sieci neuronowe", Kraków 1992
原文地址:http://galaxy.agh.edu.pl/~vlsi/AI/backp_t_en/backprop.html
-----------------------------------------------------------------------分界线
以下内容来自微信公众号文《收藏!机器学习与深度学习面试问题总结.....》
链接:https://mp.weixin.qq.com/s/CdqUNqDSnk9WWolbhAlT9Q
(1)BP,Back-propagation
后向传播是在求解损失函数L对参数w求导时候用到的方法,目的是通过链式法则对参数进行一层一层的求导。这里重点强调:要将参数进行随机初始化而不是全部置0,否则所有隐层的数值都会与输入相关,这称为对称失效。
大致过程是:
首先前向传导计算出所有节点的激活值和输出值,

计算整体损失函数:
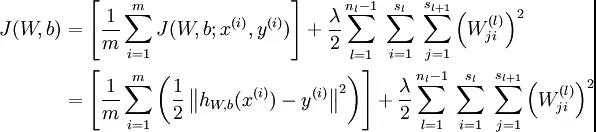
然后针对第L层的每个节点计算出残差(这里是因为UFLDL中说的是残差,本质就是整体损失函数对每一层激活值Z的导数),所以要对W求导只要再乘上激活函数对W的导数即可

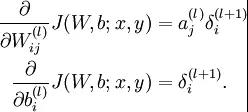
(2)梯度消失、梯度爆炸
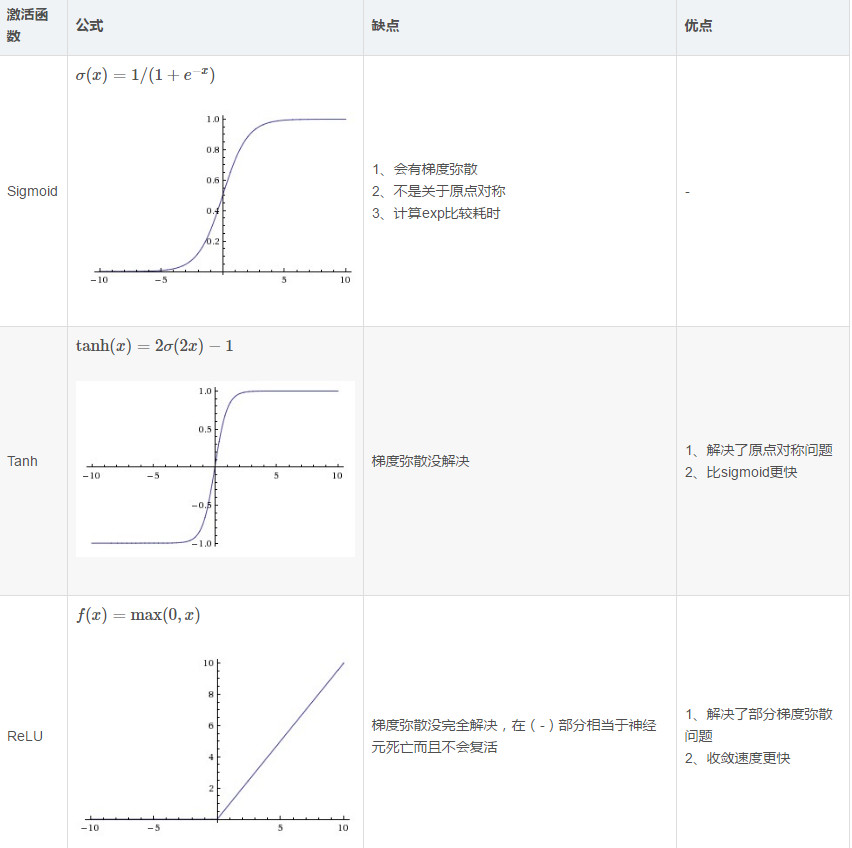
梯度消失:这本质上是由于激活函数的选择导致的, 最简单的sigmoid函数为例,在函数的两端梯度求导结果非常小(饱和区),导致后向传播过程中由于多次用到激活函数的导数值使得整体的乘积梯度结果变得越来越小,也就出现了梯度消失的现象。
梯度爆炸:同理,出现在激活函数处在激活区,而且权重W过大的情况下。但是梯度爆炸不如梯度消失出现的机会多。
(3)常用的激活函数
(5)解决overfitting的方法
dropout, regularization, batch normalizatin,但是要注意dropout只在训练的时候用,让一部分神经元随机失活。 Batch normalization是为了让输出都是单位高斯激活,方法是在连接和激活函数之间加入BatchNorm层,计算每个特征的均值和方差进行规则化。