1.CNN基本原理(对应相乘再相加)
卷积神经网络能够识别图像,它的理论依据是卷积可以识别边缘,识别纹理,然后通过不断的卷积,提取出抽象的特征,最终实现图像识别。
局部感知
在传统神经网络中每个神经元都要与图片上每个像素相连接,这样的话就会造成权重的数量巨大造成网络难以训练。而在含有卷积层的的神经网络中每个神经元的权重个数都时卷积核的大小,这样就相当于没有神经元只与对应图片部分的像素相连接。这样就极大的减少了权重的数量。同时我们可以设置卷积操作的步长,假设将上图卷积操作的步长设置为3时每次卷积都不会有重叠区域(在超出边界的部分补自定义的值)。局部感知的直观感受如下图:
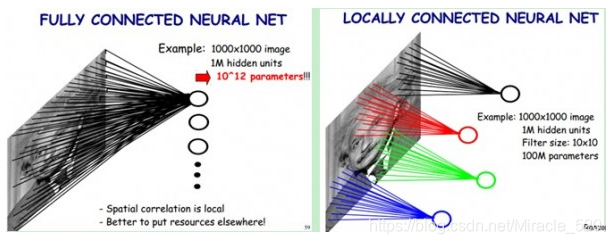
使用局部感知的原因是一般人们认为图片中距离相近的部分相关性较大,而距离比较远的部分相关性较小。在卷积操作中步长的设置就对应着距离的远近。但是步长的设置并无定值需要使用者尝试
参数共享
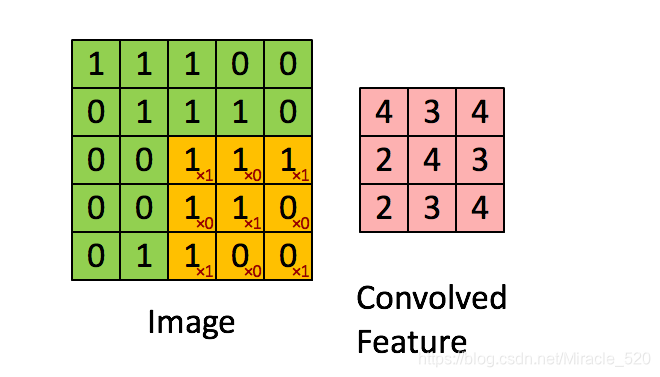
在介绍参数共享前我们应该知道卷积核的权重是经过学习得到的,并且在卷积过程中卷积核的权重是不会改变的,这就是参数共享的思想。这说明我们通过一个卷积核的操作提取了原图的不同位置的同样特征。简单来说就是在一幅图片中的不同位置的相同目标,它们的特征是基本相同的。其过程如下图:
多核卷积
如权值共享的部分所说我们用一个卷积核操作只能得到一部分特征可能获取不到全部特征,这么一来我们就引入了多核卷积。用每个卷积核来学习不同的特征(每个卷积核学习到不同的权重)来提取原图特征。
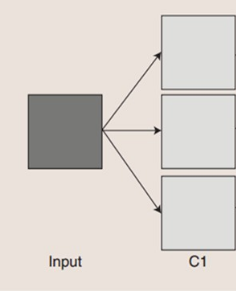
上图的图片经过三个卷积核的卷积操作得到三个特征图。需要注意的是,在多核卷积的过程中每个卷积核的大小应该是相同的。
下采样层(Down—pooling)
下采样层也叫池化层,其具体操作与卷积层的操作基本相同,只不过下采样的卷积核为只取对应位置的最大值、平均值等(最大池化、平均池化),并且不经过反向传播的修改。
参考文献
池化层的特征:
1.没有要学习的参数,池化只是从目标区域中取最大值(或者平均值),所以不存在要学习的参数。
2.通道数不发生变化,计算是按通道独立进行的。
3.对微小的数值变化具有鲁棒性(健壮),输入数据发生微小偏差时,池化仍会返回相同的结果
卷积神经网络(CNN)学习笔记
2.卷积的整体过程
-
经过卷积后输出图像尺寸:
假设输入图像尺寸为W,卷积核尺寸为F,步幅(stride)为S(卷积核移动的步幅),Padding使用P(用于填充输入图像的边界,一般填充0),那么经过该卷积层后输出的图像尺寸为(W-F+2P)/S+1。
-
池化
池化层通过减小中间过程产生的特征图的尺寸(下采样,图像深度不变),从而减小参数规模,降低计算复杂度,也可以防止过拟合。池化是分别独立作用于图像深度方向上的每个slice,一般使用Max操作(在一个局部区域内取最大值代表该区域),即最大池。通常池化层的空间尺寸(spatial extent)不应过大,过大会丢失太多结构信息,一般取F=3,S=2或者F=2,S=2。也有人不建议使用池化,而是在卷积层增大stride来降低图像尺寸。
-
全连接
一个神经元作用于整个slice,即filter的尺寸恰好为一个slice的尺寸,这样输出一个值,如果有n个filter,则输出长度为n的向量,一般全连接层的输出为类别/分数向量(class scores )。
-
其他
(1)尽量使用多层fliter尺寸小的卷积层代替一层filter较大的卷积层。
因为使用多层filter较小的卷积层所能观察到的区域大小和一层filter较大的卷积层是相同的,但是前者可以看到更加抽象的特征,提取的特征表达性能更佳。
此外,前者引入的参数规模相比后者更小。比如,使用3层filter为3X3的卷积层代替1层filter为7X7的卷积层,假设输入的volume为C个通道,则前者参数个数为3×(C×(3×3×C))=27C2,而后者为C×(7×7×C)=49C2,明显前者引入的参数更少。
(2)为什么使用padding?
使用padding的好处是使得卷积前后的图像尺寸保持相同,可以保持边界的信息。一般padding的大小为P=(F-1)/2,其中F为filter的尺寸。如果不使用paddding,则要仔细跟踪图像尺寸的变化,确保每一层filter和stride正确的被使用。
(3)为什么stride一般设为1?
stride设为1实际表现效果更好,将下采样的工作全部交给池化层。
(4)输入层(input layer)尺寸一般应该能被2整除很多次
比如32(CIFAR-10),64,96(STL-10),224(common ImageNet ConvNets),384和512。(5)尽量使用filter较小(3x3 or 至多 5x5)的卷积层
如果要使用较大的filter(比如7x7),一般也只在第一个卷积层。(6)有时候由于参数太多,内存限制,会在第一个卷积层使用较大filter(7x7)和stride(2)(参考 ZF Net),或者filter(11x11),stride(4)(参考 AlexNet)。
参考文献
3.1*1卷积的作用
我们都知道,卷积核的作用在于特征的抽取,越是大的卷积核尺寸就意味着更大的感受野,当然随之而来的是更多的参数。早在1998年,LeCun大神发布的LetNet-5模型中就会出,图像空域内具有局部相关性,卷积的过程是对局部相关性的一种抽取。
但是在学习卷积神经网络的过程中,我们常常会看到一股清流般的存在—1*1的卷积!
1X1卷积核最开始是在颜水成论文中提出的,后来被GoogLeNetConvolutions的初始结构继续应用了。能够使用更小通道的前提就是稀疏比较多不然1 * 1效果也不会很明显
1x1卷积可以压缩信道数。池化可以压缩宽和高
1x1卷积给神经网络增加非线性,从而减少或保持信道数不变,也可以增加信道数
如何理解卷积神经网络中的1*1卷积
卷积神经网络中用1 * 1卷积有什么作用?
首先假设用平面的二维图像与11的核进行卷积,则我们会得到:
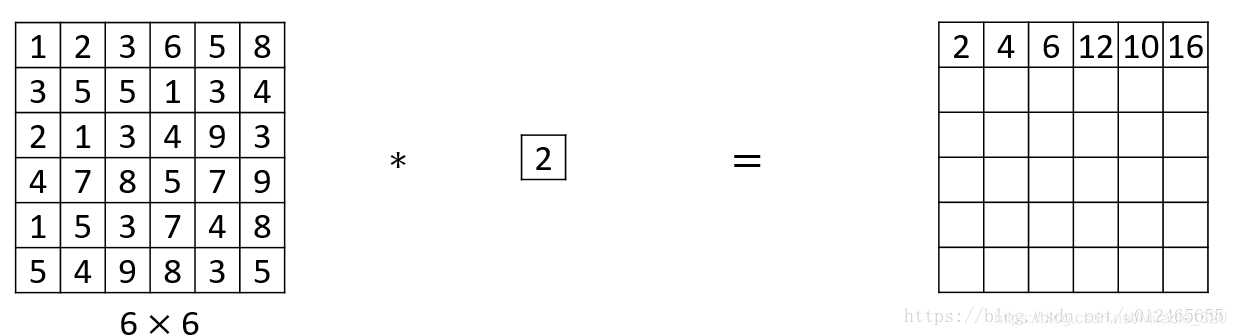
这样只会在原来的像素上乘上一个系数,并没有什么直接的效果。
但是假设在一个多通道的图像中用上11的卷积核,我们会得到什么样的效果呢?
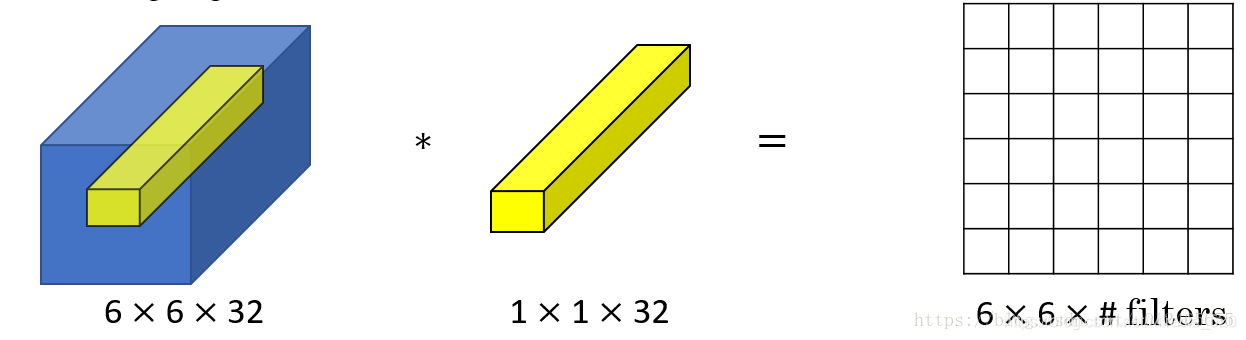
用一个6632的图像去乘以1132的卷积核得到的其实是一个66的二维矩阵。这样就将通道数32给消除了,相当于给图像降维的操作,而且很迅速。
卷积核的通道数必须与源图像的通道数相同。在通常的神经网络中,一般不会单独只使用1个卷积核,当使用的卷积核的个数是filters的时候,最后输出的就是一个66*filters的立方块。
参考资料
4.卷积层的设置规律
-
输入层
应该能被2整除很多次。常用数字包括32(比如CIFAR-10),64,96(比如STL-10)或224(比如ImageNet卷积神经网络),384和512。 -
卷积层
应该使用小尺寸滤波器(比如3x3或最多5x5),使用步长S=1。对输入数据进行零填充,使卷积层不改变输入数据在空间维度上的尺寸。比如,当F=3,那就使用P=1来保持输入尺寸。当F=5时,使用P=2,一般对于任意F,当P=(F-1)/2的时候能保持输入尺寸。如果必须使用更大的滤波器尺寸(比如7x7之类),通常只用在第一个面对原始图像的卷积层上。 -
池化层
负责对输入数据的空间维度进行降采样。最常用的设置是用用2x2感受野(即F=2)的最大值池化,步长为2(S=2)。注意这一操作将会把输入数据中75%的激活数据丢弃(因为对宽度和高度都进行了2的降采样)。另一个不那么常用的设置是使用3x3的感受野,步长为2。最大值池化的感受野尺寸很少有超过3的,因为汇聚操作过于激烈,易造成数据信息丢失,这通常会导致算法性能变差。
所有的卷积层都能保持其输入数据的空间尺寸,池化层只负责对数据从空间维度进行降采样。如果使用的步长大于1并且不对卷积层的输入数据使用零填充,那么就必须监督输入数据体通过整个卷积神经网络结构的过程,确认所有的步长和滤波器都尺寸互相吻合。
为什么在卷积层使用1的步长?
在实际应用中,更小的步长效果更好。步长为1可以让空间维度的降采样全部由池化层负责,卷积层只负责对输入数据体的深度进行变换。
为何使用零填充?
使用零填充除了前面提到的可以让卷积层的输出数据保持和输入数据在空间维度的不变,还可以提高算法性能。如果卷积层值进行卷积而不进行零填充,那么数据体的尺寸就会略微减小,那么图像边缘的信息就会过快地损失掉。
在 tensorflow 中,tf.nn.conv2d函数和tf.nn.max_pool函数,尺寸变化:
对于SAME填充,输出高度和宽度计算如下:
out_height = ceil(float(in_height)/ float(strides [1]))
out_width = ceil(float(in_width)/ float(strides [2]))
对于VALID填充,输出高度和宽度计算如下:
out_height = ceil( float(in_height - filter_height + 1)/ float(strides[1]))
out_width = ceil( float(in_width - filter_width + 1)/ float(strides [2]))
一文看懂卷积神经网络操作原理
假设输入大小为(H,W),滤波器大小为(FH,FW),输出大小为(OH,OW),填充为P,步幅为S。那么我们可以得到下面这个式子:
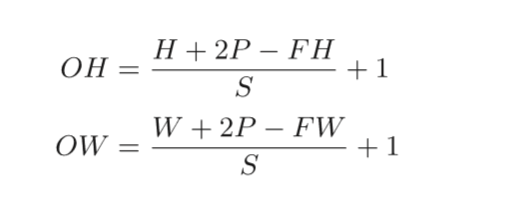
**因为内存限制所做的妥协:
**在某些案例(尤其是早期的卷积神经网络结构)中,基于前面的各种规则,内存的使用量迅速飙升。例如,使用64个尺寸为3x3的滤波器对224x224x3的图像进行卷积,零填充为1,得到的激活数据体尺寸是[224x224x64]。这个数量就是一千万的激活数据,或者就是72MB的内存(每张图就是这么多,激活函数和梯度都是)。因为GPU通常因为内存导致性能瓶颈,所以做出一些妥协是必须的。在实践中,人们倾向于在网络的第一个卷积层做出妥协。例如,可以妥协可能是在第一个卷积层使用步长为2,尺寸为7x7的滤波器(比如在ZFnet中)。在AlexNet中,滤波器的尺寸的11x11,步长为4。
