1 数据库集群会产生哪些问题?
- 自增 ID 问题
- 数据关联查询问题(水平拆分)
- 数据同步问题
2 数据库集群如何考虑数据库自增唯一性?
在数据库集群环境下,默认自增方式存在问题,因为都是从 1 开始自增,可能会存在重复,应该设置每台节点自增步长不同。
查询自增的步长:
SHOW VARIABLES LIKE 'auto_inc%'
修改自增的步长:
SET @@auto_increment_increment=10;
修改起始值:
SET @@auto_increment_offset=5;
假设有两台 mysql 数据库服务器:
- 节点①自增 1 3 5 7 9 11 ….
- 节点②自增 2 4 6 8 10 12 ….
注意:在最开始设置好了每台节点自增方式步长后,确定好了
mysql集群数量后,无法扩展新的mysql,不然生成步长的规则可能会发生变化。
推荐:使用
雪花算法或redis解决数据库自增唯一性
3 数据库分表分库策略
数据库分表分库原则遵循:垂直拆分 与 水平拆分
垂直拆分:就是根据不同的业务,分为不同的数据库,比如会员数据库、订单数据库、支付数据库等,垂直拆分在微服务项目中用的非常常见。
优点:拆分后业务清晰,拆分规则明确,系统之间整合或扩展容易。缺点:部分业务表无法join,只能通过接口方式解决,提高了系统复杂度,存在分布式事务问题。
水平拆分:是把同一个表拆到不同的数据库中。
- 相对于垂直拆分,水平拆分不是将表的数据做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中 的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中,主要有
分表,分库两种模式。 - 该方式 提高了系统的稳定性跟负载能力,但是跨库
join性能较差。
4 使用 MyCat 实现水平分片策略
MyCat 支持 10 种分片策略:
- 求模算法
- 分片枚举
- 范围约定
- 日期指定
- 固定分片
hash算法 - 通配取模
ASCII码求模通配- 编程指定
- 字符串拆分
hash解析
详细:http://www.mycat.io/document/mycat-definitive-guide.pdf
4.1 分片枚举 算法
分片枚举:根据不同的枚举(常量),进行分类存储。
这种规则适用于特定的场景,比如有些业务需要按照省份或区县来做保存,而全国的省份区县固定的,这类业务使用这一规则。
配置如下:
- 案例步骤:创建数据库:
userdb_1、userdb_2、userdb_3 - 修改
partition-hash-int.txt规则wuhan=0 shanghai=1 suzhou=2
根据地区进行分库:湖北数据库、江苏数据库、山东数据库。
应用场景:根据地区进行查找数据等
配置步骤
1、创建三个数据库:
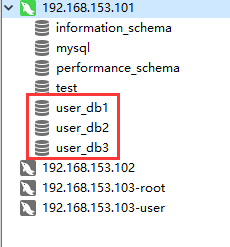
都创建表:

2、修改配置文件:
枚举配置文件:partition-hash-int.txt
wuhan=0
shanghai=1
suzhou=2
配置 分库分表 规则的文件:rule.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="role2">
<rule>
<columns>name</columns> <!-- 根据数据库里面的 name 自动进行分片枚举 -->
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name="hash-int" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property> <!-- 指定枚举文件 -->
<property name="type">1</property> <!-- 1表示非数值类型;0为数值类型 -->
<property name="defaultNode">1</property> <!-- 默认存放路径为 1 -->
</function>
</mycat:rule>
schema.xml:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- TESTDB1 是mycat的逻辑库名称,链接需要用的 -->
<schema name="user_db" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
<table name="user_info" dataNode="dn$1-3" rule="role2" />
</schema>
<!-- database 是MySQL数据库的库名 -->
<dataNode name="dn1" dataHost="localhost1" database="user_db1" />
<dataNode name="dn2" dataHost="localhost1" database="user_db2" />
<dataNode name="dn3" dataHost="localhost1" database="user_db3" />
<!--
dataNode节点中各属性说明:
name:指定逻辑数据节点名称;
dataHost:指定逻辑数据节点物理主机节点名称;
database:指定物理主机节点上。如果一个节点上有多个库,可使用表达式db$0-99, 表示指定0-99这100个数据库;
dataHost 节点中各属性说明:
name:物理主机节点名称;
maxCon:指定物理主机服务最大支持1000个连接;
minCon:指定物理主机服务最小保持10个连接;
writeType:指定写入类型;
0,只在writeHost节点写入;
1,在所有节点都写入。慎重开启,多节点写入顺序为默认写入根据配置顺序,第一个挂掉切换另一个;
dbType:指定数据库类型;
dbDriver:指定数据库驱动;
balance:指定物理主机服务的负载模式。
0,不开启读写分离机制;
1,全部的readHost与stand by writeHost参与select语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且M1与 M2互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡;
2,所有的readHost与writeHost都参与select语句的负载均衡,也就是说,当系统的写操作压力不大的情况下,所有主机都可以承担负载均衡;
-->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="3" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- 可以配置多个主从 -->
<writeHost host="hostM1" url="192.168.153.101:3306" user="root" password="123456">
<!-- 可以配置多个从库 -->
<readHost host="hostS2" url="192.168.153.12:3306" user="root" password="123456" />
</writeHost>
</dataHost>
</mycat:schema>
server.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<!-- 读写都可用的用户 -->
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">user_db</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<!-- 只读用户 -->
<user name="user">
<property name="password">user</property>
<property name="schemas">user_db</property>
<property name="readOnly">true</property>
</user>
</mycat:server>
测试
启动 MyCat:
/usr/local/mycat/bin/mycat start
查看日志:
cat /usr/local/mycat/logs/wrapper.log
在 MyCat 连接中插入以下数据:
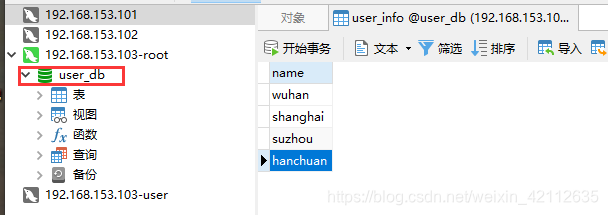
会按照之前的规则分别存到对应的数据库中,缺省的存在第一个数据库中。
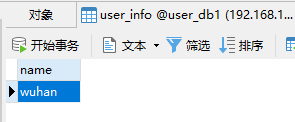
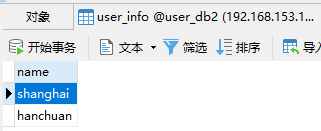
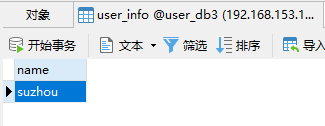
问题:如果查询时不按此字段查询,那么会扫描每个数据库
4.2 取模 算法
根据 id 进行十进制取模运算,运算结果为分区索引 。
注意:数据库节点分片数量无法更改,和 ES 集群非常相似的。
配置步骤
1、创建三个数据库:
都创建表:
2、修改配置文件:
配置 分库分表 规则的文件:rule.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="role2">
<rule>
<columns>id</columns> <!-- 根据数据库里面的 id 自动进行分片 -->
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!--指定分片数量,不可以被更改-->
<property name="count">3</property>
</function>
</mycat:rule>
schema.xml:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- TESTDB1 是mycat的逻辑库名称,链接需要用的 -->
<schema name="user_db" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
<table name="user_info" dataNode="dn$1-3" rule="role2" />
</schema>
<!-- database 是MySQL数据库的库名 -->
<dataNode name="dn1" dataHost="localhost1" database="user_db1" />
<dataNode name="dn2" dataHost="localhost1" database="user_db2" />
<dataNode name="dn3" dataHost="localhost1" database="user_db3" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="3" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- 可以配置多个主从 -->
<writeHost host="hostM1" url="192.168.153.101:3306" user="root" password="123456">
<!-- 可以配置多个从库 -->
<readHost host="hostS2" url="192.168.153.12:3306" user="root" password="123456" />
</writeHost>
</dataHost>
</mycat:schema>
server.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<!-- 读写都可用的用户 -->
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">user_db</property>
</user>
<!-- 只读用户 -->
<user name="user">
<property name="password">user</property>
<property name="schemas">user_db</property>
<property name="readOnly">true</property>
</user>
</mycat:server>
测试
启动 MyCat:
/usr/local/mycat/bin/mycat start
查看日志:
cat /usr/local/mycat/logs/wrapper.log
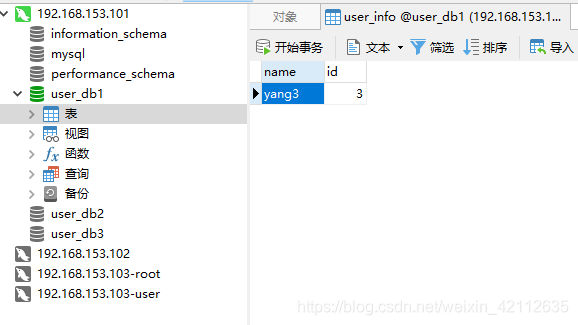
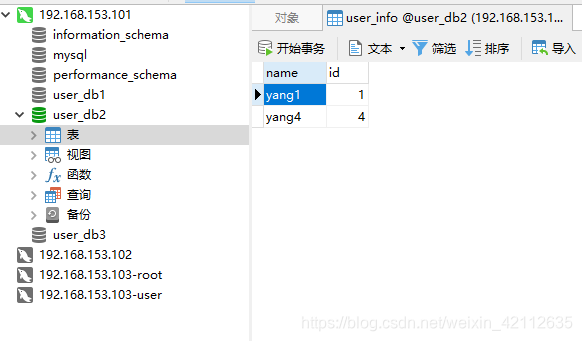
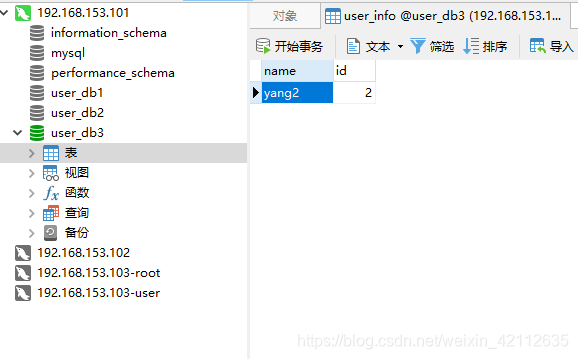
插入以下数据:
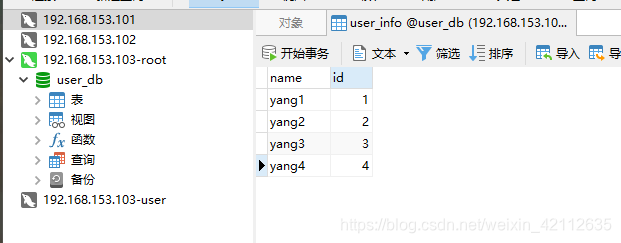
可以看到在三个数据库中分别存储的为:
5 使用 MyCat 分表分库原理分析
修改
/usr/local/mycat/conf/log4j2.xml日志级别为debug
vi /usr/local/mycat/conf/log4j2.xml

查看日志:
tail -200f /usr/local/mycat/logs/mycat.log
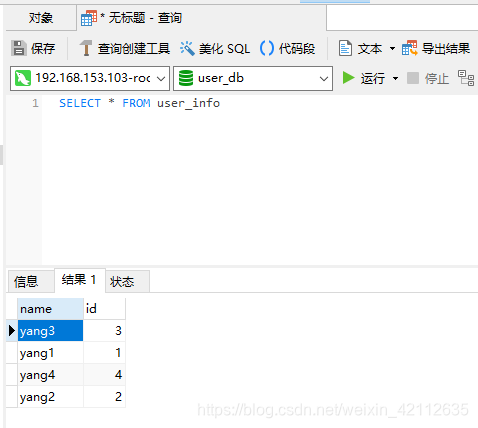
执行下面的 SQL 语句:
日志:
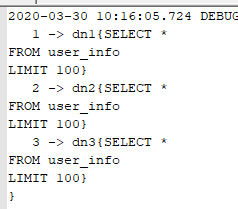
执行下面的 SQL 语句:
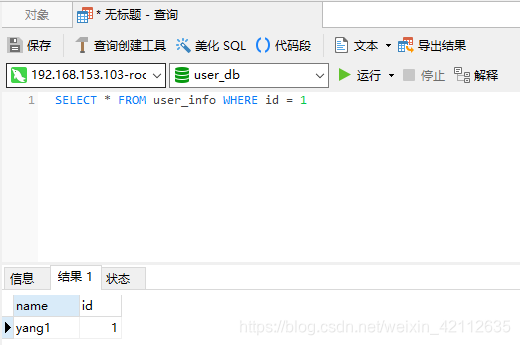
日志:
Mycat 中的路由结果是通过分片字段和分片方法来确定的,如果查询条件中有 id 字段的情况还好,查询将会落到某个具体的分片。
如果查询没有分片的字段,会向所有的 db 都会查询一遍,然后封装结果集给客户端。
执行
LIMIT查询:
所有数据:
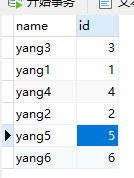
SELECT * FROM user_info LIMIT 0,2
会向每个库都发送查询语句,会随机选择一条查询语句的结果:
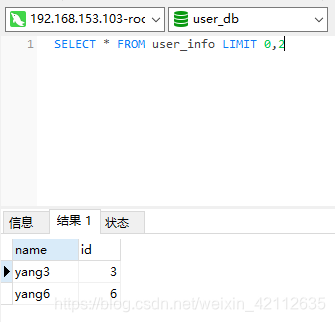
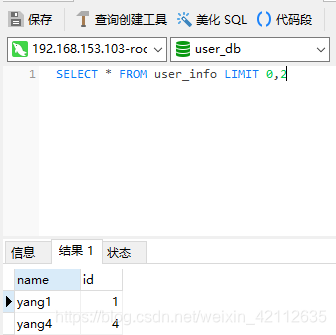
由于每个数据库都有两条数据,所以会随机选择一个库中的数据做展示
执行下面语句:
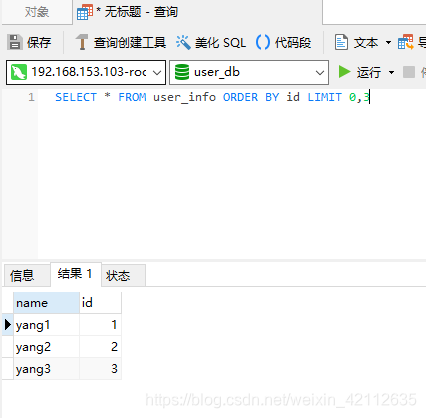
SELECT * FROM user_info LIMIT 0,3
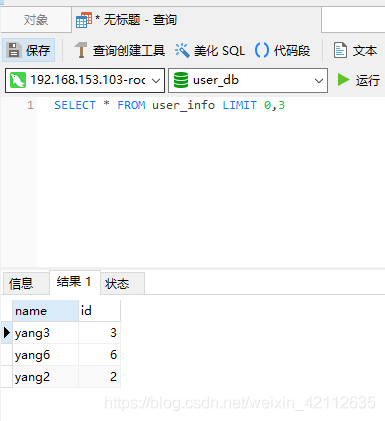
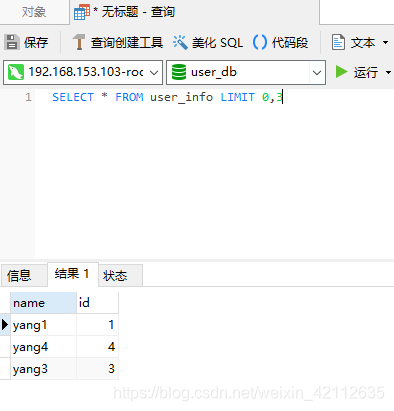
会先随机取一个库中的两条数据,再随机再其他两个数据库中拿取一条数据
执行
ORDER BY查询:
SELECT * FROM user_info ORDER BY id LIMIT 0,3