哈希表:哈希表是一种可以在O(1)时间内查找到某个元素的数据结构,它是用数组实现的,这依赖于内存的随机访问特性。那哈希表到底是什么样呢?哈希表是通过哈希函数(hashfunc)使元素的存储位置与关键码一一对应的关系,所以在进行元素查找的时候可以通过该函数快速的找到该元素。若结构中存在关键字和key相等的元素,则必然存储在f(k)的位置上。由此,不需要进行比较便可以直接取得所查记录。这个对应函数就被称为散列函数(哈希函数),依照这个思想所建立出来的表就被称为散列表(哈希表)。
常见的哈希函数有很多种,在这里我先用除留余数法简单的画一下哈希表是怎样存储元素的。
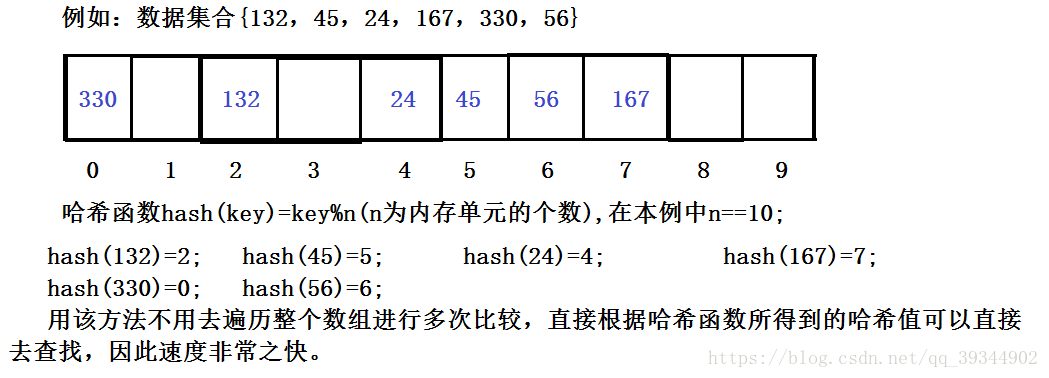
但是有没有发现一个问题,如果我们想再存入一个值为16的元素,应该把它存在哪里,这就是哈希冲突问题;所谓哈希冲突就是对于两个不同的数据元素m和n,存在HashFunc(m)==HashFunc(n);即不同的关键字计算出相同的哈希地址,这种现象称为哈希冲突或者哈希碰撞,把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”。
那我们应该怎样去很好的解决掉哈希冲突问题呢?
一般来说有三种解决方式:
第一种:引起哈希冲突的一个很可能的因素就是哈希函数设计的不够合理,哈希函数设计时应遵从下面几条原则:
1.哈希函数的定义域必须包含需要存储的所有关键码,即如果哈希表中有m个地址时,其值域必须在0~m-1之间。
2.哈希函数计算出来的哈希地址应该均匀的分布在整个哈希表中。
3.哈希函数的设计应该进可能的简单一点。
常见的哈希函数可自行百度。
第二种:闭散列
闭散列也叫开放地址法,当发生哈希冲突时,如果哈希表未被装满,说明哈希表中还有位置,可以把key放在下一个空位中去,那么如何去寻找下一个空余位置呢?
线性探测:举个例子:
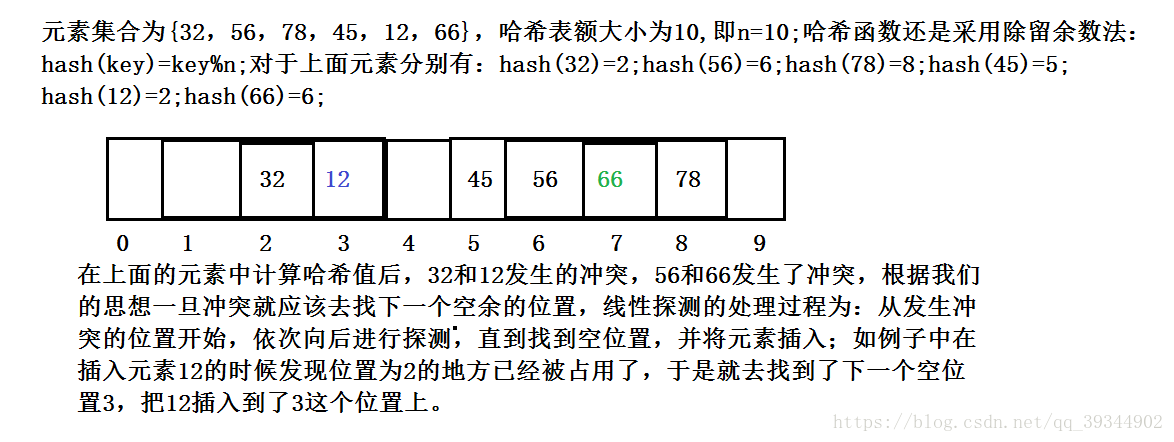
根据闭散列线性的处理哈希冲突的方法,我们不难发现,不能随便删除哈希表中的元素,如果直接删除会影响其他元素的搜索。假设我们在上面例子中的哈希表中删除了元素32,当我们再想去查找元素12的时候,我们会首先去位置2的地方去找,此时我们发现位置2是空着的,我们就会认为12不存在于哈希表中,我们肯定就不再去向后进行查找了。(只有当位置2的不为空的时候,我们才会认为有可能发生了哈希冲突,才会去向后继续查找)。
采用线性探测的方法非常简单,但是当大量的哈希冲突聚集在一起,容易产生“数据堆积”,不同的关键码占据了可利用的空位置,使得寻找某一个关键字可能需要进行多次的比较,降低了搜索效率。那么如何缓解这种问题呢?我们引入了散列表的负载因子a=插入表中的元素个数/散列表的长度;a是散列表装满程度的标志因子,a越大,表明表中的元素越多,产生冲突的可能性就越大;反之,a越小,表明插入表中的元素就越少,产生哈希冲突的可能性就越小,实际上,散列表的平均查找长度是负载因子a的函数,只是不同处理冲突的方法有不同的函数。对于开放定址法,a非常重要,一般控制在0.7-0.8以下,当插入表中的元素个数=a*散列表长度时,我们就认为该哈希表已经满了,不可以再进行插入元素了。a超过0.8,查表时的cpu缓存命不中的概率呈指数上升趋势。
二次探测:发生哈希冲突时,二次探测法在表中查找下一个空位置的计算公式为: Hi=(H0+i^2)%m;Hi=(H0-i^2)%m;i=1,2,3...
m为哈希表的大小。
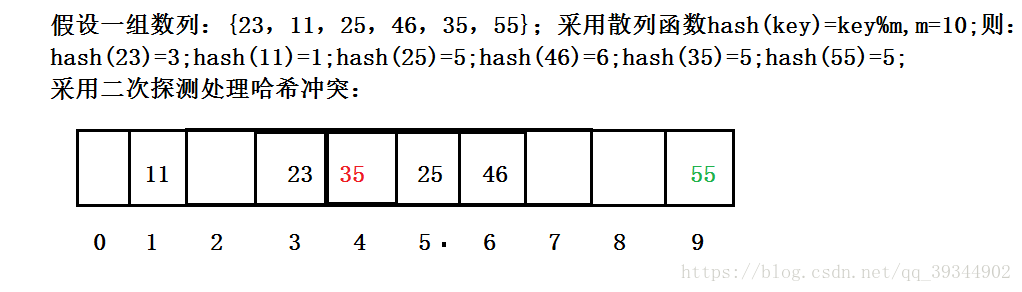
在上面的例子中,哈希冲突有三个元素:25,35和55,当插入5的时候直接存在了位置5处,插入35的时候发现位置5被占用了,所以就不能根据公式Hi=(H0+i^2)%m=(5+1)%10=6;尝试去往位置6出插入,发现位置6也被占用了,于是根据公式Hi=(H0-i^2)%m=(5-1)%10=4;尝试往位置4进行插入,位置4为空,所以将35插在了位置4处。接下来插入最后一个元素55时发现4和6的位置都被占用了,于是根据公式Hi=(H0+i^2)%m=(5+2^2)%10=9(此时i=2);尝试向位置9进行插入,并插入成功。
研究表明:当表的程度为质数且表的负载因子不超过0.5时,新的元素一定能够插入,而且任意一个位置都不会被探查两次,因此表中只要有一半的空位置,就不存在表满的问题。在搜索时可以不考虑表装满的情况,但在插入元素的时候必须保证负载因子a不超过0.5,如果超出必须对哈希表进行增容。
用闭散列实现哈希结构的代码如下:
//hash_table.h
#pragma once
#include<stddef.h>
#include<Windows.h>
#include<stdio.h>
#define Header printf("=============%s===============\n",__FUNCTION__);
#define HashMaxSize 1000
typedef enum Stat {
Empty,
Valid,
Invalid // 当前元素被删除了
} Stat;
typedef int KeyType;
typedef int ValType;
typedef size_t (*Hashfunc)(KeyType);
typedef struct HashElem {
KeyType key;
ValType value;
Stat stat; // 引入一个 stat 标记来作为是否有效的标记
} HashElem;
typedef struct HashTable {
HashElem data[HashMaxSize];
size_t size;
Hashfunc hash_func;
} HashTable;
void HashInit(HashTable* ht, Hashfunc hash_func);
size_t HashfuncDefault(KeyType key);
void HashPrint(HashTable* ht,const char* msg);
int HashInsert(HashTable* ht, KeyType key, ValType value);
// 输入key, 查找对应key的value.
int HashFind(HashTable* ht, KeyType key, ValType* value);
void HashRemove(HashTable* ht, KeyType key);
int HashEmpty(HashTable* ht);
size_t HashSize(HashTable* ht);
void HashDestroy(HashTable* ht);
void CountNum(HashTable* ht);//统计每个元素出现了几次
//hash_table.c
#include "hash_table.h"
size_t HashfuncDefault(KeyType key)
{
return key%HashMaxSize;
}
void HashInit(HashTable* ht, Hashfunc hash_func)
{
size_t i=0;
if(ht==NULL)//非法输入
{
return;
}
ht->hash_func=hash_func;
ht->size=0;
for(; i<HashMaxSize; ++i)
{
ht->data[i].stat=Empty;
}
return;
}
int HashInsert(HashTable* ht, KeyType key, ValType value)
{
size_t offset;
if(ht==NULL)
{
return 0;
}
if(ht->size>HashMaxSize*0.8)//负载因子设为0.8
{
return 0;
}
offset=ht->hash_func(key);
while(1)
{
if(ht->data[offset].stat==Valid)
{
if(ht->data[offset].key==key)
{
return 0;
}
++offset;
if(offset>=HashMaxSize)
{
offset-=HashMaxSize;
}
}
else
{
ht->data[offset].key=key;
ht->data[offset].value=value;
ht->data[offset].stat=Valid;
++ht->size;
break;
}
}
return 1;
}
void HashPrint(HashTable* ht,const char* msg)
{
size_t i=0;
printf("%s>\n",msg);
for(; i<HashMaxSize; ++i)
{
if(ht->data[i].stat!=Empty)
{
printf("[%lu] key:[%d] value[%d] stat[%d]",i,ht->data[i].key,
ht->data[i].value,ht->data[i].stat);
printf("\n");
}
}
}
int HashFind(HashTable* ht, KeyType key, ValType* value)
{
size_t offset;
if(ht==NULL)
{
return 0;
}
offset=ht->hash_func(key);
while(1)
{
if(key==ht->data[offset].key&&ht->data[offset].stat==Valid)//找到了
{
*value=ht->data[offset].value;
return 1;
}
else if(ht->data[offset].stat==Empty)
{
return 0;
}
else
{
++offset;
if(offset>=HashMaxSize)
{
offset-=HashMaxSize;
}
}
}
return 0;
}
void HashRemove(HashTable* ht, KeyType key)
{
size_t offset;
if(ht==NULL)
{
return;
}
offset=ht->hash_func(key);
while(1)
{
if(key==ht->data[offset].key&&ht->data[offset].stat==Valid)//找到了
{
ht->data[offset].stat=Invalid;
--ht->size;
return;
}
else if(ht->data[offset].stat==Empty)
{
break;
}
else
{
++offset;
if(offset>=HashMaxSize)
{
offset-=HashMaxSize;
}
}
}
}
void HashDestroy(HashTable* ht)
{
size_t i=0;
if(ht==NULL)
{
return;
}
for(; i<HashMaxSize; ++i)
{
ht->data[i].stat=Empty;
}
ht->size=0;
ht->hash_func=NULL;
return;
}
int HashEmpty(HashTable* ht)
{
if(ht==NULL)
{
return 1;
}
return ht->size==0?1:0;
}
size_t HashSize(HashTable* ht)
{
if(ht==NULL)
{
return 0;
}
return ht->size;
}
void CountNum(HashTable* ht)
{
int arr[]={1,2,4,2,1,4,1};
int i=0;
int ret=0;
int value=0;
int sz=sizeof(arr)/sizeof(arr[0]);
Header;
HashInit(ht,HashfuncDefault);
for(; i<sz; ++i)
{
ret=HashFind(ht,arr[i],&value);
if(ret==0)
{
HashInsert(ht,arr[i],1);
}
else
{
HashRemove(ht,arr[i]);
HashInsert(ht,arr[i],value+1);
}
}
for(i=0; i<sz; i++)
{
printf("%d ",arr[i]);
}
printf("\n");
HashPrint(ht,"统计之后的结果为");
}
//测试用例test.c
#include "hash_table.h"
void TestInit()
{
HashTable ht;
size_t i=0;
Header;
HashInit(&ht,HashfuncDefault);
printf("size expect 0,actual %d\n",ht.size);
printf("ht->hash_func expect %p,actual %p\n",HashfuncDefault,ht.hash_func);
for(i=0;i<HashMaxSize; ++i)
{
if(ht.data[i].stat!=Empty)
{
printf("pos [%lu] elem error!\n",i);
}
}
}
void TestInsert()
{
HashTable ht;
Header;
HashInit(&ht,HashfuncDefault);
HashInsert(&ht,1,100);
HashInsert(&ht,1001,200);
HashInsert(&ht,1002,300);
HashInsert(&ht,1003,400);
HashInsert(&ht,2,500);
HashInsert(&ht,5,600);
HashPrint(&ht,"向哈希表插入六个元素");
}
void TestFind()
{
HashTable ht;
int ret;
int value=0;
Header;
HashInit(&ht,HashfuncDefault);
HashInsert(&ht,1,100);
HashInsert(&ht,1001,200);
HashInsert(&ht,1002,300);
HashInsert(&ht,1003,400);
HashInsert(&ht,2,500);
HashInsert(&ht,5,600);
ret=HashFind(&ht,1002,&value);
printf(" ret expect 1,actual %d\n value expect 300,actual %d\n",ret,value);
ret=HashFind(&ht,3,&value);
printf(" ret expect 0,actual %d\n",ret);
}
void TestRemove()
{
HashTable ht;
Header;
HashInit(&ht,HashfuncDefault);
HashInsert(&ht,1,100);
HashInsert(&ht,1001,200);
HashInsert(&ht,1002,300);
HashInsert(&ht,1003,400);
HashInsert(&ht,2,500);
HashInsert(&ht,5,600);
HashRemove(&ht,1002);
HashPrint(&ht,"删除1002之后的结果为");
}
void TestDestroy()
{
HashTable ht;
Header;
HashInit(&ht,HashfuncDefault);
HashInsert(&ht,1,100);
HashInsert(&ht,1001,200);
HashInsert(&ht,1002,300);
HashInsert(&ht,1003,400);
HashInsert(&ht,2,500);
HashInsert(&ht,5,600);
HashDestroy(&ht);
HashPrint(&ht,"销毁后的结果为");
}
void TestEmpty()
{
HashTable ht;
int ret;
Header;
HashInit(&ht,HashfuncDefault);
ret=HashEmpty(&ht);
printf("ret expect 1,actual %d\n",ret);
HashInsert(&ht,1,100);
HashInsert(&ht,1001,200);
ret=HashEmpty(&ht);
printf("ret expect 0,actual %d\n",ret);
}
void TestSize()
{
HashTable ht;
size_t size;
Header;
HashInit(&ht,HashfuncDefault);
HashInsert(&ht,1,100);
HashInsert(&ht,1001,200);
HashInsert(&ht,1002,300);
HashInsert(&ht,1003,400);
size=HashSize(&ht);
printf("size expect 4,actual %lu\n",size);
}
void TestCountNum()
{
HashTable ht;
Header;
HashInit(&ht,HashfuncDefault);
CountNum(&ht);
}
int main()
{
TestInit();
TestInsert();
TestFind();
TestRemove();
TestDestroy();
TestEmpty();
TestSize();
TestCountNum();
system("pause");
return 0;
}
第三种:开散列
开散列法又叫做链地址法(开链法);首先对每个关键码使用哈希函数求哈希地址,具有相同地址的关键码归于同一个集合,每一个集合称为一个桶,各个桶中的元素通过一个单链表连接起来,各链表的节点存储在一个哈希表中。
那么开散列哈希桶是怎样存储的呢?

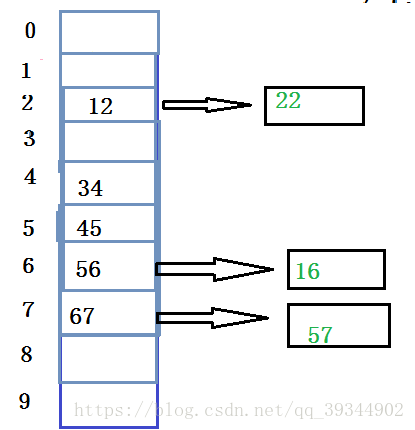
通常情况下,每个桶对应的节点很少,将n个关键码通过某一哈希函数,存放到哈希表中的m个桶中,那么每一个链表的平均长度为:n/m;以搜索平均长度为:n/m的链表代替搜索长度为n的顺序表,效率高了很多。
应用链地址法需要增加链接指针,这看似增加了存储开销,实际上,由于开地址法必须保证大量的空闲空间以确保搜索效率,如二次探测法要求负载因子a<0.5;而表项所占空间又比指针大的多,所以从本质上来说使用链地址法反而比开地址法更加节省空间。
下面是开散列的代码实现:
//hash_table.h
#pragma once
#include <stddef.h>
#include<Windows.h>
#include<stdio.h>
#define HashMaxSize 1000
typedef int KeyType;
typedef int ValType;
typedef size_t (*HashFunc)(KeyType key);
typedef struct HashElem {
KeyType key;
ValType value;
struct HashElem* next;
} HashElem;
// 数组的每一个元素是一个不带头结点的链表
// 对于空链表, 我们使用 NULL 来表示
typedef struct HashTable {
HashElem* data[HashMaxSize];
size_t size;
HashFunc hash_func;
} HashTable;
void HashInit(HashTable* ht, HashFunc hash_func);
// 约定哈希表中不能包含 key 相同的值.
int HashInsert(HashTable* ht, KeyType key, ValType value);
int HashFind(HashTable* ht, KeyType key, ValType* value);
void HashRemove(HashTable* ht, KeyType key);
size_t HashSize(HashTable* ht);
int HashEmpty(HashTable* ht);
void HashDestroy(HashTable* ht);
//hash_table.c
#include "hash_table2.h"
void HashInit(HashTable* ht, HashFunc hash_func)
{
size_t i=0;
if(ht==NULL)
{
return;
}
ht->size=0;
ht->hash_func=hash_func;
for(; i<HashMaxSize; ++i)
{
ht->data[i]=NULL;
}
return;
}
HashElem* HashBucketFind(HashElem* head,KeyType key)
{
HashElem* cur;
if(head==NULL)
{
return NULL;
}
cur=head;
for(; cur!=NULL; cur=cur->next)
{
if(cur->key!=key)
{
continue;
}
else
{
return cur;
}
}
return NULL;
}
HashElem* CreateHashNode(KeyType key,KeyType value)
{
HashElem* new_node=(HashElem*)malloc(sizeof(HashElem));
new_node->key=key;
new_node->value=value;
new_node->next=NULL;
return new_node;
}
int HashInsert(HashTable* ht, KeyType key, ValType value)
{
size_t offset;
HashElem* res;
HashElem* new_node;
if(ht==NULL)
{
return 0;
}
offset=ht->hash_func(key);
res=HashBucketFind(ht->data[offset],key);
if(res!=NULL)
{
return 0;
}
else
{
new_node=CreateHashNode(key,value);
new_node->next=ht->data[offset];
ht->data[offset]=new_node;
++ht->size;
return 1;
}
return 0;
}
int HashFind(HashTable* ht, KeyType key, ValType* value)
{
size_t offset;
HashElem* res;
if(ht==NULL||value==NULL)
{
return 0;
}
offset=ht->hash_func(key);
res=HashBucketFind(ht->data[offset],*value);
if(res==NULL)
{
return 0;
}
else
{
*value=ht->data[offset]->value;
return 1;
}
return 0;
}
int HashBucketFindPrevandcur(HashElem* head,KeyType key,HashElem** cur_output,HashElem** prev_output)
{
HashElem* pre=NULL;
HashElem* cur=head;
if(head==NULL||cur_output==NULL||prev_output==NULL)
{
return 0;
}
for(; cur!=NULL; pre=cur, cur=cur->next)
{
if(cur->key==key)
{
*cur_output=cur;
*prev_output=pre;
return 1;
}
}
return 0;
}
void DestroyHashNode(HashElem* ptr)
{
free(ptr);
}
void HashRemove(HashTable* ht, KeyType key)
{
size_t offset;
int res;
HashElem* cur;
HashElem* pre;
if(ht==NULL)
{
return;
}
offset=ht->hash_func(key);
pre=NULL;
cur=ht->data[offset];
res=HashBucketFindPrevandcur(ht->data[offset],key,&cur,&pre);
if(res==0)
{
return;
}
if(cur==ht->data[offset])
{
ht->data[offset]=cur->next;
}
else
{
pre->next=cur->next;
}
DestroyHashNode(cur);
--ht->size;
return;
}
size_t HashSize(HashTable* ht)
{
if(ht==NULL)
{
return 0;
}
return ht->size;
}
int HashEmpty(HashTable* ht)
{
if(ht==NULL)
{
return 0;
}
return ht->size==0?1:0;
}
void HashDestroy(HashTable* ht)
{
size_t i=0;
HashElem* cur;
HashElem* to_delete;
if(ht==NULL)
{
return;
}
ht->hash_func=NULL;
ht->size=0;
for(i=0;i<HashMaxSize; ++i)
{
cur=ht->data[i];
while(cur!=NULL)
{
to_delete=cur;
cur=cur->next;
DestroyHashNode(to_delete);
}
}
}
//测试用例test.c
#include "hash_table2.h"
#define HEADER printf("================%s=================\n",__FUNCTION__);
size_t HashFuncDefault(KeyType key)
{
return key%HashMaxSize;
}
void HashPrint(HashTable* ht,const char* msg)
{
size_t i=0;
HashElem* cur;
if(ht==NULL)
{
return;
}
printf("[%s]\n",msg);
for(i=0; i<HashMaxSize; ++i)
{
if(ht->data[i]!=NULL)
{
cur=ht->data[i];
for(; cur!=NULL; cur=cur->next)
{
printf("[%d] ",i);
printf("%d:%d;",ht->data[i]->key,ht->data[i]->value);
}
printf("\n");
}
}
}
void TestInit()
{
HashTable ht;
size_t i=0;
HEADER;
HashInit(&ht,HashFuncDefault);
printf("size expect 0,actual %d\n",ht.size);
printf("HashFunc expect %p,actual %p\n",HashFuncDefault,ht.hash_func);
for(i=0; i<HashMaxSize; ++i)
{
if(ht.data[i]!=NULL)
{
printf("pos[%lu] error!\n",i);
}
}
}
void TestInsert()
{
HashTable ht;
HEADER;
HashInit(&ht,HashFuncDefault);
HashInsert(&ht,1,100);
HashInsert(&ht,2,200);
HashInsert(&ht,1001,300);
HashInsert(&ht,3,400);
HashPrint(&ht,"插入四个元素");
printf("size %d\n",ht.size);
}
void TestFind()
{
HashTable ht;
ValType value=0;
int ret;
HEADER;
HashInit(&ht,HashFuncDefault);
HashInsert(&ht,1,100);
HashInsert(&ht,2,200);
HashInsert(&ht,1001,300);
HashInsert(&ht,3,400);
ret=HashFind(&ht,3,&value);
printf("ret expect 1,ectual %d\n",ret);
printf("value expect 400,actual %d\n",value);
}
void TestRemove()
{
HashTable ht;
HEADER;
HashInit(&ht,HashFuncDefault);
HashInsert(&ht,1,100);
HashInsert(&ht,2,200);
HashInsert(&ht,1001,300);
HashInsert(&ht,3,400);
HashRemove(&ht,1);
HashPrint(&ht,"删除1之后的结果为");
}
void TestSize()
{
HashTable ht;
int ret;
HEADER;
HashInit(&ht,HashFuncDefault);
HashInsert(&ht,1,100);
HashInsert(&ht,2,200);
HashInsert(&ht,1001,300);
HashInsert(&ht,3,400);
ret=HashSize(&ht);
printf("ret expect 4,actual %d\n",ret);
}
void TestEmpty()
{
HashTable ht;
int ret;
HEADER;
HashInit(&ht,HashFuncDefault);
ret=HashEmpty(&ht);
printf("ret expect 1,actual %d\n",ret);
HashInsert(&ht,1,100);
HashInsert(&ht,2,200);
HashInsert(&ht,1001,300);
HashInsert(&ht,3,400);
ret=HashEmpty(&ht);
printf("ret expect 0,actual %d\n",ret);
}
void TestDestroy()
{
HashTable ht;
HEADER;
HashInit(&ht,HashFuncDefault);
HashInsert(&ht,1,100);
HashInsert(&ht,2,200);
HashInsert(&ht,1002,300);
HashInsert(&ht,3,400);
HashDestroy(&ht);
printf("size expect 0,actual %d\n",ht.size);
}
int main()
{
TestInit();
TestInsert();
TestFind();
TestRemove();
TestSize();
TestEmpty();
TestDestroy();
system("pause");
return 0;
}