flink当中对于实时处理,有很多的算子,我们可以来看看常用的算子主要有哪些,dataStream当中的算子主要分为三大类,
- Transformations:转换的算子,都是懒执行的,只有真正碰到sink的算子才会真正加载执行
- partition:对数据进行重新分区等操作
- Sink:数据下沉目的地
- 官网算子介绍:https://ci.apache.org/projects/flink/flink-docs-master/dev/stream/operators/index.html
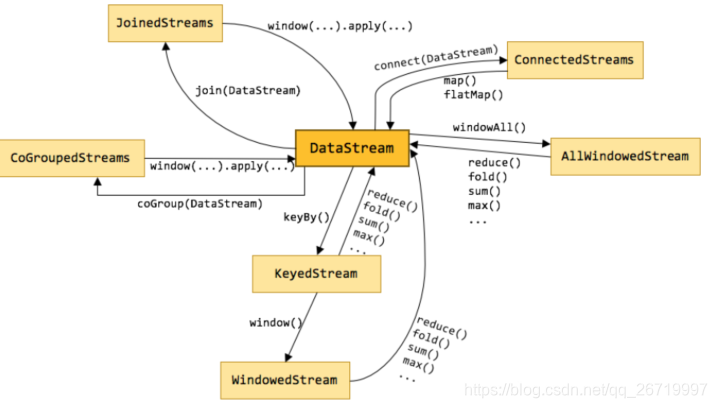
- Transformations算子
- map:输入一个元素,然后返回一个元素,中间可以做一些清洗转换等操作
- flatmap:输入一个元素,可以返回零个,一个或者多个元素
- filter:过滤函数,对传入的数据进行判断,符合条件的数据会被留下
- keyBy:根据指定的key进行分组,相同key的数据会进入同一个分区
- reduce:对数据进行聚合操作,结合当前元素和上一次reduce返回的值进行聚合操作,然后返回一个新的值
- aggregations:sum(),min(),max()等
- window:后面的文章单独讲解
- Union:合并多个流,新的流会包含所有流中的数据,但是union是一个限制,就是所有合并的流类型必须是一致的
- Connect:和union类似,但是只能连接两个流,两个流的数据类型可以不同,会对两个流中的数据应用不同的处理方法。
- Transformations小案例
- 1:获取两个dataStream,然后使用union将两个dataStream进行合并
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} object FlinkUnion { def main(args: Array[String]): Unit = { val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment import org.apache.flink.api.scala._ //获取第一个dataStream val firstStream: DataStream[String] = environment.fromElements("hello world","test scala") //获取第二个dataStream val secondStream: DataStream[String] = environment.fromElements("second test","spark flink") //将两个流进行合并起来 val unionAll: DataStream[String] = firstStream.union(secondStream) //结果不做任何处理 val unionResult: DataStream[String] = unionAll.map(x => { // println(x) x }) //调用sink算子,打印输出结果 unionResult.print().setParallelism(1) //开始运行 environment.execute() } }- 2 :使用connect实现不同类型的DataStream进行连接
import org.apache.flink.streaming.api.scala.{ConnectedStreams, DataStream, StreamExecutionEnvironment} object FlinkConnect { def main(args: Array[String]): Unit = { //获取程序入口类 val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment //导入隐式转换的包 import org.apache.flink.api.scala._ //定义string类型的dataStream val strStream: DataStream[String] = environment.fromElements("hello world","abc test") //定义int类型的dataStream val intStream: DataStream[Int] = environment.fromElements(1,2,3,4,5) //两个流进行connect操作 val connectedStream: ConnectedStreams[String, Int] = strStream.connect(intStream) //通过map对数据进行处理,传入两个函数 val connectResult: DataStream[Any] = connectedStream.map(x =>{ x + "abc"},y =>{ y * 2 }) connectResult.print().setParallelism(1) environment.execute("connect stream") } }- 3:使用split将一个DataStream切成多个DataStream
import java.{lang, util} import org.apache.flink.streaming.api.collector.selector.OutputSelector import org.apache.flink.streaming.api.scala.{DataStream, SplitStream, StreamExecutionEnvironment} object FlinkSplit { def main(args: Array[String]): Unit = { val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment import org.apache.flink.api.scala._ //获取第一个dataStream val resultDataStream: DataStream[String] = environment.fromElements("hello world","test spark","spark flink") //通过split来对我们的流进行切分操作 val splitStream: SplitStream[String] = resultDataStream.split(new OutputSelector[String] { override def select(out: String): lang.Iterable[String] = { val strings = new util.ArrayList[String]() if (out.contains("hello")) { //如果包含hello,那么我们就给这个流起名字叫做hello strings.add("hello") } else { strings.add("other") } strings } }) //对我么的stream进行选择 val helloStream: DataStream[String] = splitStream.select("hello") //打印包含hello的所有的字符串 helloStream.print().setParallelism(1) environment.execute() } } - Partition算子:prtition算子允许我们对数据进行重新分区,或者解决数据倾斜等问题
- Random partitioning:随机分区
- dataStream.shuffle()
- Rebalancing:对数据集进行再平衡,重分区,消除数据倾斜
- datatream.rebalance()
- Rescaling:Rescaling是通过执行oepration算子来实现的。由于这种方式仅发生在一个单一的节点,因此没有跨网络数据传输。
- dataStream.rescale()
- Custom partitioning:自定义分区自定义分区需要实现Partitioner接口
- dataStream.partitionCustom(partitioner, “someKey”)
- dataStream.partitionCustom(partitioner, 0)
- Broadcasting:广播变量(后面的文章会详细介绍)
- Random partitioning:随机分区
- Partition算子小案例
- 对我们filter过后的数据进行重新分区
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} object FlinkPartition { def main(args: Array[String]): Unit = { val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment import org.apache.flink.api.scala._ val dataStream: DataStream[String] = environment.fromElements("hello world","test spark","abc hello","hello flink") val resultStream: DataStream[(String, Int)] = dataStream.filter(x => x.contains("hello")) // .shuffle //随机的重新分发数据,上游的数据,随机的发送到下游的分区里面去 // .rescale .rebalance //对数据重新进行分区,涉及到shuffle的过程 .flatMap(x => x.split(" ")) .map(x => (x, 1)) .keyBy(0) .sum(1) resultStream.print().setParallelism(1) environment.execute() } }- 自定义分区策略,实现不同分区的数据发送到不同分区里面去进行处理,将包含hello的字符串发送到一个分区里面去,其他的发送到另外一个分区里面去
- 第一步:自定义分区类
import org.apache.flink.api.common.functions.Partitioner class MyPartitioner extends Partitioner[String]{ override def partition(word: String, num: Int): Int = { println("分区个数为" + num) if(word.contains("hello")){ 0 }else{ 1 } } }- 第二步:代码实现进行分区
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} object FlinkCustomerPartition { def main(args: Array[String]): Unit = { val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment //设置我们的分区数,如果不设置,默认使用CPU核数作为分区个数 environment.setParallelism(2) import org.apache.flink.api.scala._ //获取dataStream val sourceStream: DataStream[String] = environment.fromElements("hello world","spark flink","hello world","hive hadoop") val rePartition: DataStream[String] = sourceStream.partitionCustom(new MyPartitioner,x => x +"") rePartition.map(x =>{ println("数据的key为" + x + "线程为" + Thread.currentThread().getId) x }) rePartition.print() environment.execute() } } - sink算子
- writeAsText():将元素以字符串形式逐行写入,这些字符串通过调用每个元素的toString()方法来获取
- print() / printToErr():打印每个元素的toString()方法的值到标准输出或者标准错误输出流中
- 自定义输出addSink【kafka、redis】
- sink算子案例:自定义sink将数据输出到redis
- 第一步:导入flink整合redis的jar包
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka-0.11 --> <dependency> <groupId>org.apache.bahir</groupId> <artifactId>flink-connector-redis_2.11</artifactId> <version>1.0</version> </dependency>- 第二步:代码开发
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} import org.apache.flink.streaming.connectors.redis.RedisSink import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper} object Stream2Redis { def main(args: Array[String]): Unit = { //获取程序入口类 val executionEnvironment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment import org.apache.flink.api.scala._ //组织数据 val streamSource: DataStream[String] = executionEnvironment.fromElements("hello world","key value") //将数据包装成为key,value对形式的tuple val tupleValue: DataStream[(String, String)] = streamSource.map(x =>(x.split(" ")(0),x.split(" ")(1))) val builder = new FlinkJedisPoolConfig.Builder builder.setHost("node03") builder.setPort(6379) builder.setTimeout(5000) builder.setMaxTotal(50) builder.setMaxIdle(10) builder.setMinIdle(5) val config: FlinkJedisPoolConfig = builder.build() //获取redis sink val redisSink = new RedisSink[Tuple2[String,String]](config,new MyRedisMapper) //使用我们自定义的sink tupleValue.addSink(redisSink) //执行程序 executionEnvironment.execute("redisSink") } } class MyRedisMapper extends RedisMapper[Tuple2[String,String]]{ override def getCommandDescription: RedisCommandDescription = { new RedisCommandDescription(RedisCommand.SET) } override def getKeyFromData(data: (String, String)): String = { data._1 } override def getValueFromData(data: (String, String)): String = { data._2 } }
