背景需求
从kafka读取数据分别插入到mysql表和redis中。
读取kafka数据
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.util.Properties;
public class Kafka2mysql {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Readkafka(env);
//ReadSocket(env);
env.execute();
}
/**
* 读kafka数据
*/
public static void Readkafka(StreamExecutionEnvironment env){
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "172.0.0.1:9092");
properties.setProperty("group.id", "com.test");
DataStream<String> stream = env
.addSource(new FlinkKafkaConsumer<String>("test",new SimpleStringSchema(),properties));
SingleOutputStreamOperator<Tuple2<String, Integer>> streams = stream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] split = value.split(",");
for (String s : split) {
out.collect(new Tuple2<>(s, 1));
}
}
}).keyBy(x -> x.f0).sum(1);
//自定义sink实现
streams.addSink(new TestMysqlSink2());
}
}
自定义mysqlSink
自定义sink这里有个实现关键点在于:如何保证插入数据不重复?直接无脑insert的话会导致出现大量重复key,这也是flink计算特性导致(来一条处理一条)。所以这里关键在于如果是一条新数据进来就插入,旧的数据就做更新。
import com.utils.MYSQLUtils;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
/**
* RichSinkFun方法可以实现管理jdbc的生命周期,和自定义SourceFun使用方式相同
*/
import java.sql.Connection;
import java.sql.PreparedStatement;
public class TestMysqlSink2 extends RichSinkFunction<Tuple2<String, Integer>> {
Connection conn;
PreparedStatement updatepsmt;
PreparedStatement insertpsmt;
@Override
public void open(Configuration parameters) throws Exception {
conn = MYSQLUtils.getConnection("test");
insertpsmt = conn.prepareStatement("insert into test1(name,count) values(?,?)");
updatepsmt = conn.prepareStatement("update test1 set count = ? where name = ?");
}
@Override
public void close() throws Exception {
if(insertpsmt != null) insertpsmt.close();
if(updatepsmt != null) updatepsmt.close();
if(conn != null) conn.close();
}
@Deprecated
public void invoke(Tuple2<String, Integer> value, Context context) throws Exception {
System.out.println("=====invoke====="+value.f0+"==>"+value.f1);
updatepsmt.setInt(1, value.f1);
updatepsmt.setString(2, value.f0);
updatepsmt.execute();
//获取当前结果的更新计数,如果没有跟新数据就插入
if(updatepsmt.getUpdateCount() == 0){
insertpsmt.setString(1, value.f0);
insertpsmt.setInt(2, value.f1);
insertpsmt.execute();
}
}
}
连接mysql工具类
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class MYSQLUtils {
public static String database;
public static Connection getConnection(String database){
try {
Class.forName("com.mysql.jdbc.Driver");
return DriverManager.getConnection("jdbc:mysql://localhost:3306/"+database, "root", "123456");
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
public static void close(Connection conn, PreparedStatement prep){
if(conn != null){
try {
conn.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
if(prep != null){
try {
prep.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
}
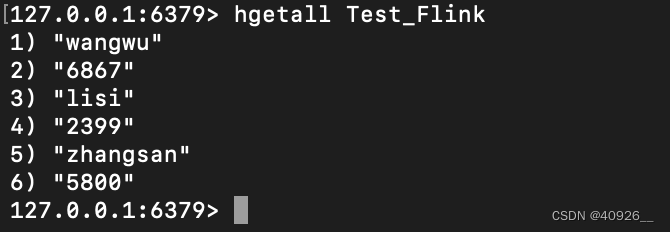
结果展示:

自定义redisSink
Flink官方提供自定义RedisSink的方式:https://bahir.apache.org/docs/flink/current/flink-streaming-redis/。官方已经把完整案例提供出来了,我们只需要套模版就行了。但这里需要注意一个地方,官方这里用的Hset指令类型,为什么这里要用哈希表呢?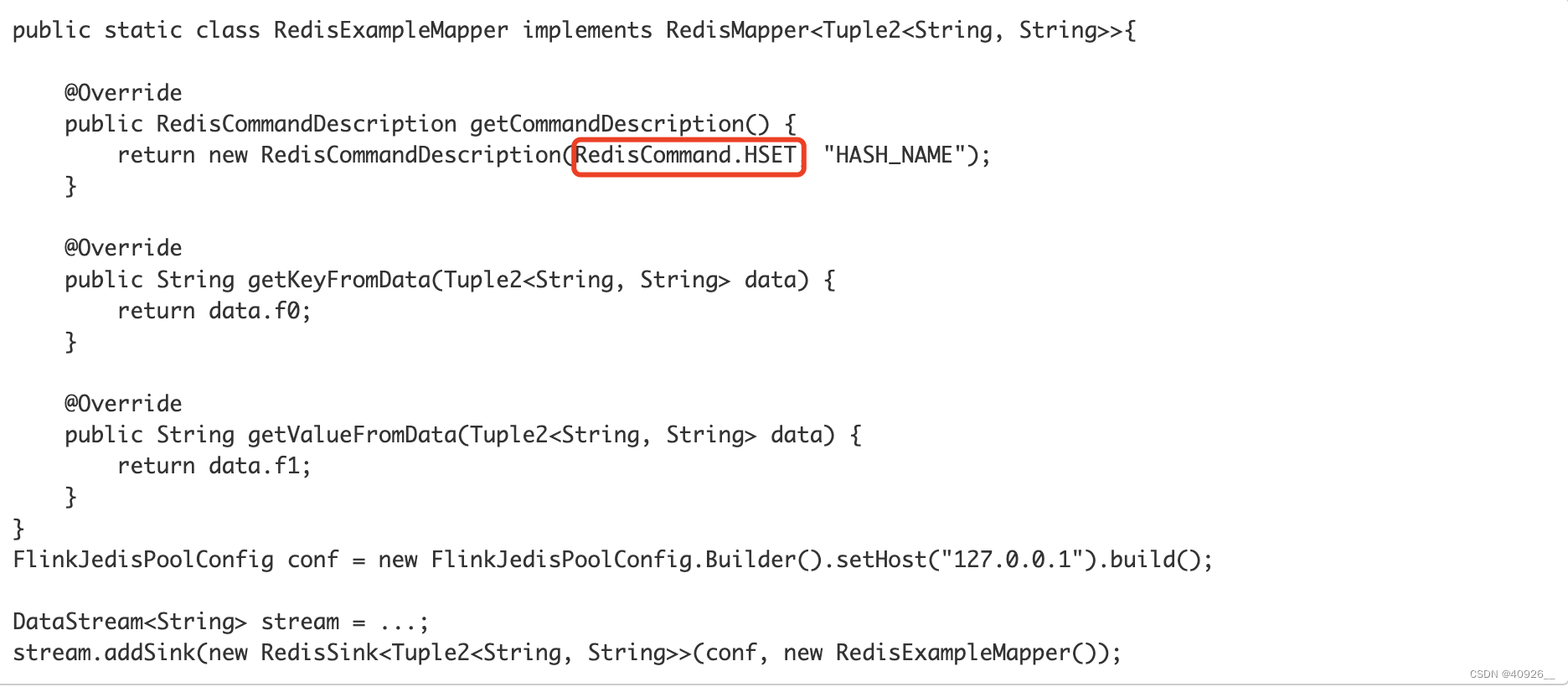
因为哈希表有如下两个特性:
1、如果HSET时表不存在时会被创建
2、如果filed域已经存在于哈希表中时,旧的value会被新的value替换
3、如果filed域不存在于哈希表中时会被创建
哈希表结构如下:key [flied value] [flied value] [flied value] …

所以这里完美规避了mysql插入重复值的问题。
接下来看下实现过程:
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.redis.RedisSink;
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig;
import org.apache.flink.util.Collector;
import java.util.Properties;
public class kafka2redis {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
ReadRedis(env);
env.execute();
}
/**
* 读kafka数据
*/
public static void ReadRedis(StreamExecutionEnvironment env) {
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "127.0.0.1:9092");
properties.setProperty("group.id", "com.test");
DataStream<String> stream = env
.addSource(new FlinkKafkaConsumer<String>("test", new SimpleStringSchema(), properties));
SingleOutputStreamOperator<Tuple2<String, Integer>> streams = stream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] split = value.split(",");
for (String s : split) {
out.collect(new Tuple2<>(s, 1));
}
}
}).keyBy(x -> x.f0).sum(1);
//TODO... 结果写入redis中
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("127.0.0.1").build();
streams.map(new MapFunction<Tuple2<String, Integer>, Tuple2<String,Integer>>() {
@Override
public Tuple2<String, Integer> map(Tuple2<String, Integer> value) throws Exception {
return Tuple2.of(value.f0,value.f1);
}
}).addSink(new RedisSink<Tuple2<String, Integer>>(conf,new TestRedisSink()));
}
}
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper;
public class TestRedisSink implements RedisMapper<Tuple2<String, Integer>> {
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.HSET,"Test_Flink");
}
@Override
public String getKeyFromData(Tuple2<String, Integer> value) {
return value.f0;
}
@Override
public String getValueFromData(Tuple2<String, Integer> value) {
return value.f1+"";
}
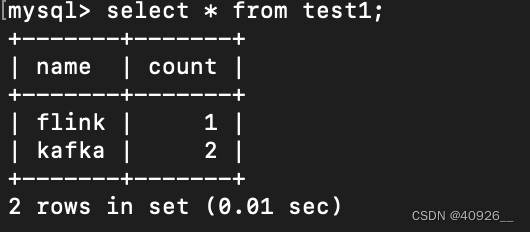
}
结果展示: