如果说FastText的词向量在表达句子时候很在行的话,GloVe在多义词方面表现出色,那么wordRank在相似词寻找方面表现地不错。 其是通过Robust Ranking来进行词向量定义。
wordRank,与 word2vec、fastText三者对比
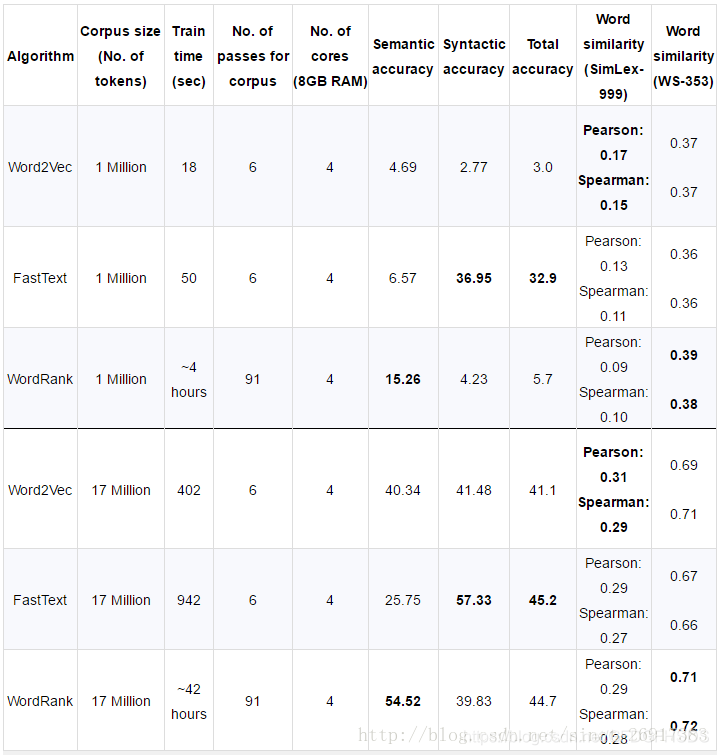
在不同的项目需求上,有着不同的训练精度,在句法表达上,fastText更好,而在单个词语的相似性等内容表达上wordRank是三者中最好的。 同时随着数据量的增加精度呈现增长的趋势。
wordRank,与 word2vec、GloVe三者对比
(1)精度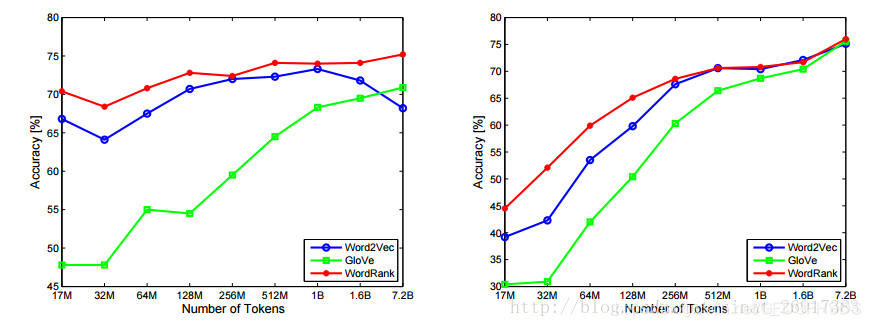
(2)词类比与词相似比较

相似词的寻找方面极佳,词类比方面不同数据集有不同精度。
结论:
1.在语义类比中,三种模型在低频词语上表现相对较差,在高频词语上表现效果较好;
2.在语法类比中,FastText优于Word2Vec和WordRank 。FastText模型在低频词语上表现的相当好,但是当词频升高时,准确率迅速降低,而WordRank和Word2Vec在很少出现和很频繁出现的词语上准确率较低;
3.FastText在综合类比中表现更好,最后一幅图说明整体类比结果与语法类比的结果比较相似,因为语法类比任务的数量远远多于语义类比,所以在综合结果中语法类比任务的结果占有更大的权重;
4、WordRank在语义类比任务上效果优于其他两种模型,而FastText在语法类比上效果更好。值得一提的是,如果用WordRank模型生成两个集合(词集合和上下文集合),WordRank使用它们词向量的内积对他们之间的关系建模,内积和他们之间的关系是直接成比例的,如果该词和上下文越相关,内积就会越大
综上,WordRank更适合语义类比,FastText更适合不同语料库下所有词频的语法类比。
